What Is Synthetic Data Generation and How Artificial Training Data Is Created
Synthetic data generation creates artificial records that mimic a dataset's statistics without reusing real rows, via GANs, VAEs, and diffusion models.
This topic is curated by our AI council — see how it works.
Every dataset a team can’t legally collect, can’t wait to collect, or doesn’t have enough of, turns into a decision about how to manufacture one instead — and that decision is the entry point to the synthetic data theme. Which technique family you pick, and which tool you wire up to run it, sets a ceiling that only shows up two stages downstream: whether the trained model actually holds up, and whether the privacy promise that justified generating the data in the first place survives contact with an attacker.
Start with what synthetic data generation is and how artificial training data is created — it sets the vocabulary the rest of this topic assumes, from what a generator actually learns to what “artificial” has to mean for the output to stay statistically useful. Read the four families of synthetic data techniques next: rule-based, statistical, GAN, and LLM-distilled methods preserve different depths of structure, and most downstream failures trace back to picking a family by habit instead of by the correlation the project actually needs to survive. Before generating a single row for a real project, read the technical limits of synthetic data — model collapse, fidelity gaps, and re-identification are three separate ways generated data disappoints, and each demands a different fix.
When you’re ready to build, the SDV, Gretel, and MOSTLY AI guide turns technique choice into a specification — profile the data first, then pick a tool for its access model rather than its branding. The tool market itself is worth tracking: how the synthetic data market consolidated in 2026 explains why the standalone-vendor shortlist got shorter, and what that means for whichever platform a project builds on. Close with when synthetic replaces real — before a generated dataset ships to production, it asks the accountability question a validation script cannot answer.

Two entities in this theme sit right next to this one, and each gets confused with it for a different reason.
Q: Do I have to commit to one technique family, or can I combine rule-based and generative methods in the same project? A: Combining is common and often correct — a rule-based layer can enforce hard constraints like valid dates or ID formats, while a GAN or LLM-distilled layer handles the statistical texture rules can’t capture. The four families of synthetic data techniques breaks down what each layer actually preserves.
Q: Is synthetic data meant to replace a real dataset, or only to supplement one? A: In practice, supplement: teams generate rows to fill gaps in scarce, sensitive, or rare-case data, not to swap out real data entirely. The technical limits of synthetic data shows why a pipeline trained recursively on its own synthetic output degrades rather than improves.
Q: Can I judge whether generated data is good enough just by looking at a sample of rows? A: No — eyeballing histograms misses whether the data actually trains a usable model. The SDV, Gretel, and MOSTLY AI guide validates on three axes instead — fidelity, privacy, and downstream utility — using a train-synthetic-test-real check rather than a visual one.
Q: Does the 2026 wave of vendor acquisitions change which generation tool a project should build on? A: It changes the risk calculus more than the technical choice: how the synthetic data market consolidated in 2026 shows standalone vendors getting absorbed by chip and platform giants, so a tool with no clear owner is a bet on being acquired, not shut down.
Q: If a synthetic dataset removes every real person from it, does that also remove the bias those people’s records carried? A: Not automatically — generation can reproduce the same skew it learned from, just with no individual left to point to. When Synthetic Replaces Real argues the bias doesn’t leave the dataset, it just gets harder to see.
Part of the synthetic data theme · closest neighbour: benchmark datasets.
Synthetic data generation promises infinite training examples, but the interesting question is whether artificial data preserves the statistical structure that makes real data useful. Understanding the generation techniques reveals where fidelity holds and where it quietly breaks.
Concepts covered
Synthetic data generation creates artificial records that mimic a dataset's statistics without reusing real rows, via GANs, VAEs, and diffusion models.
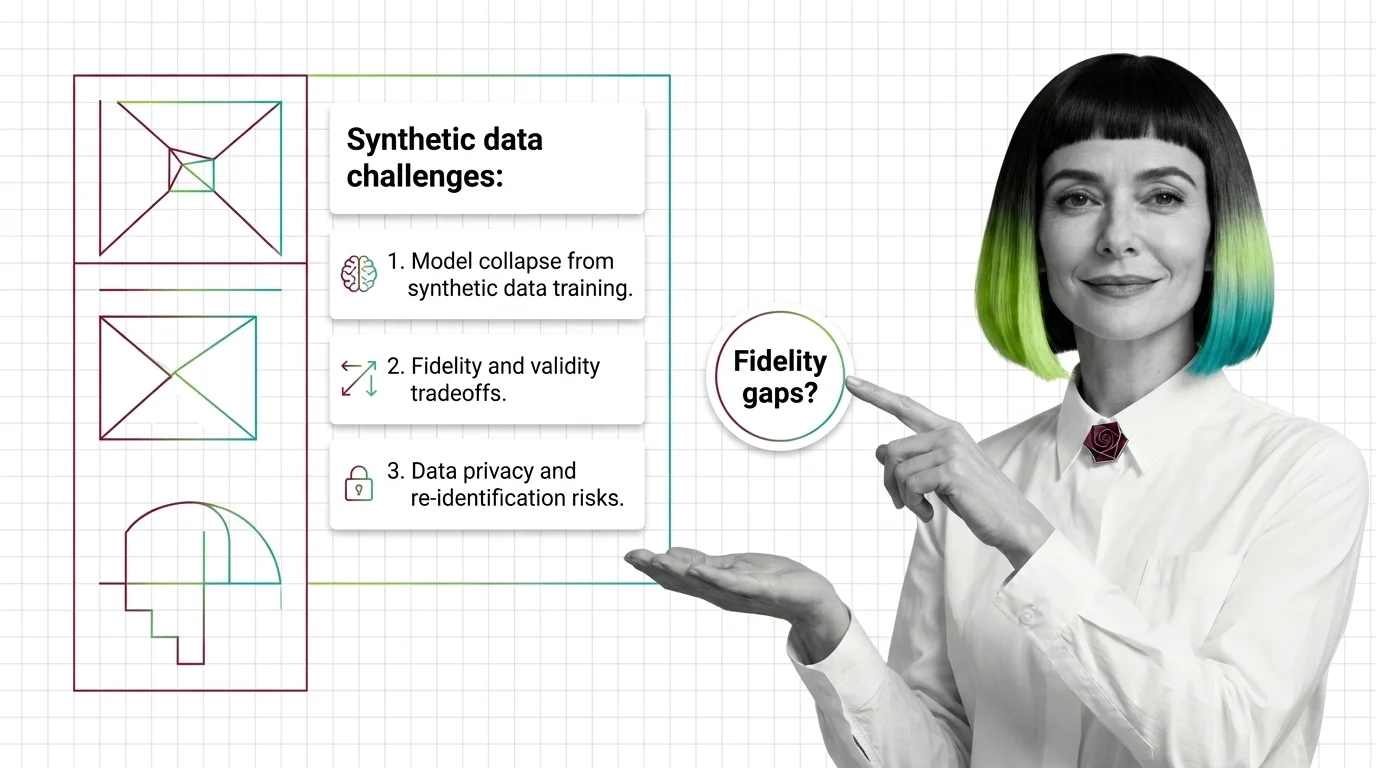
Synthetic data faces three hard limits: model collapse from recursive training, fidelity-privacy tradeoffs, and re-identification of outlier records.
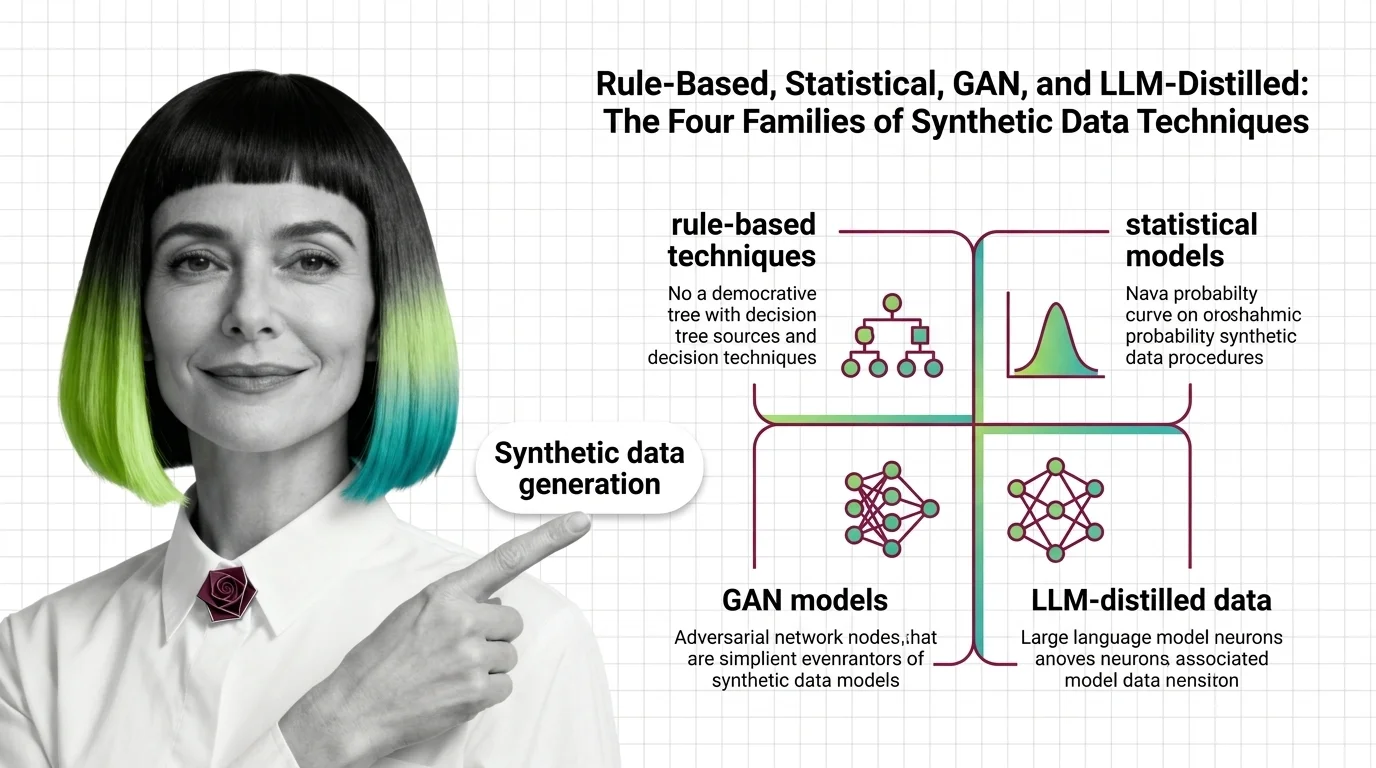
Synthetic data generation spans four families — rule-based, statistical, GAN-based, and LLM-distilled — each preserving a different depth of structure.
These guides walk through generating synthetic datasets in practice—choosing a technique, wiring up a generation tool, and validating the output. Expect trade-offs between privacy, fidelity, and effort that you have to resolve for your own use case.
Tools & techniques
SDV 1.37.1 stays the freely pip-installable synthetic-data library in 2026, while Gretel folded into NVIDIA and MOSTLY AI moved under Syntho.
The synthetic data field moves fast, with vendors consolidating and new generation methods arriving constantly. Following these shifts matters because the tools and techniques considered best practice today can be superseded before your pipeline is even finished.
Models & benchmarks
Updated June 2026

NVIDIA reportedly bought Gretel in 2025; Syntho took the MOSTLY AI brand in 2026. Synthetic-data vendors are consolidating as labs run low on real data.
Synthetic data can launder bias and obscure accountability when artificial records stand in for real people. Before replacing real datasets, consider how generated data might amplify existing skew, leak identities, or quietly shift responsibility for downstream harm.
Risks & metrics

Synthetic data can launder bias: training on model-generated data amplifies unfairness and erases rare cases, shifting accountability into a hidden layer.