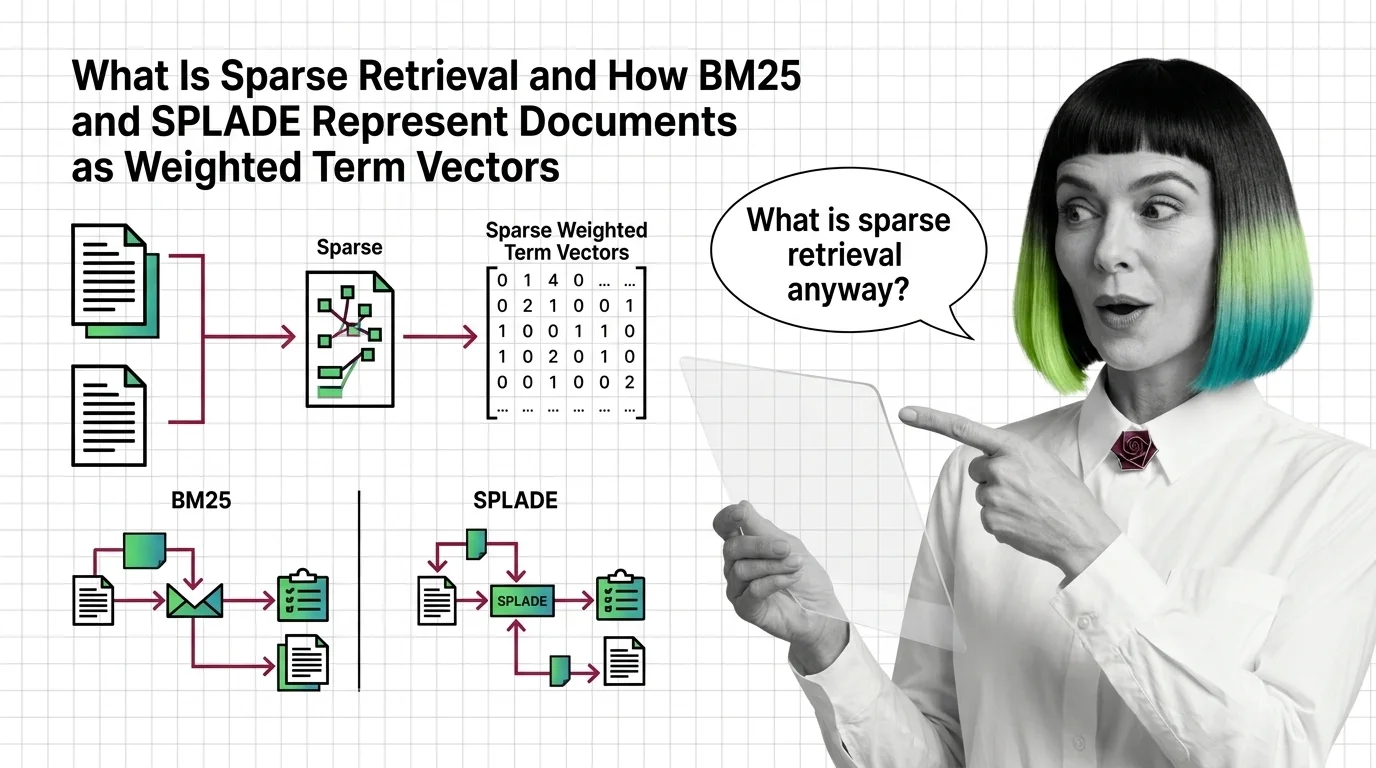
What Is Sparse Retrieval and How BM25 and SPLADE Represent Documents as Weighted Term Vectors
Sparse retrieval encodes documents as weighted term vectors. Here is how BM25 and SPLADE produce those weights and why they beat dense models on exact terms.