Similarity Search Algorithms
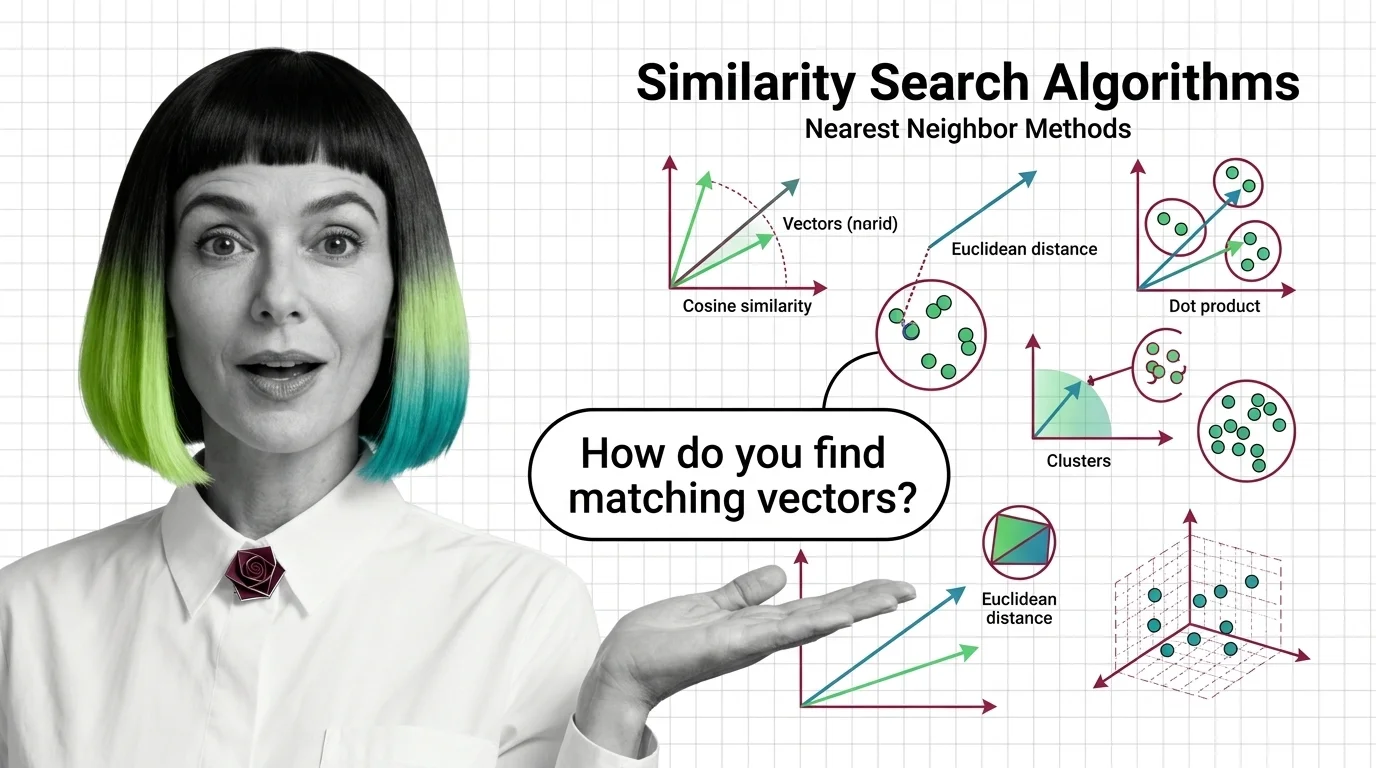
Similarity search algorithms are the core mathematical methods used to find the nearest matching vectors in high-dimensional embedding spaces. Techniques like cosine similarity, dot product comparison, and Euclidean distance measurement determine how retrieval systems locate relevant results among millions of candidate vectors. These algorithms form the computational foundation of every vector database, semantic search engine, and retrieval-augmented generation pipeline, converting geometric proximity between vectors into meaningful search results. Also known as: Nearest Neighbor Search, ANN, Approximate Nearest Neighbor.
Understand the Fundamentals
Similarity search algorithms translate the abstract problem of finding meaning into measurable distances between vectors. Understanding how different metrics shape retrieval reveals why no single algorithm suits every use case.

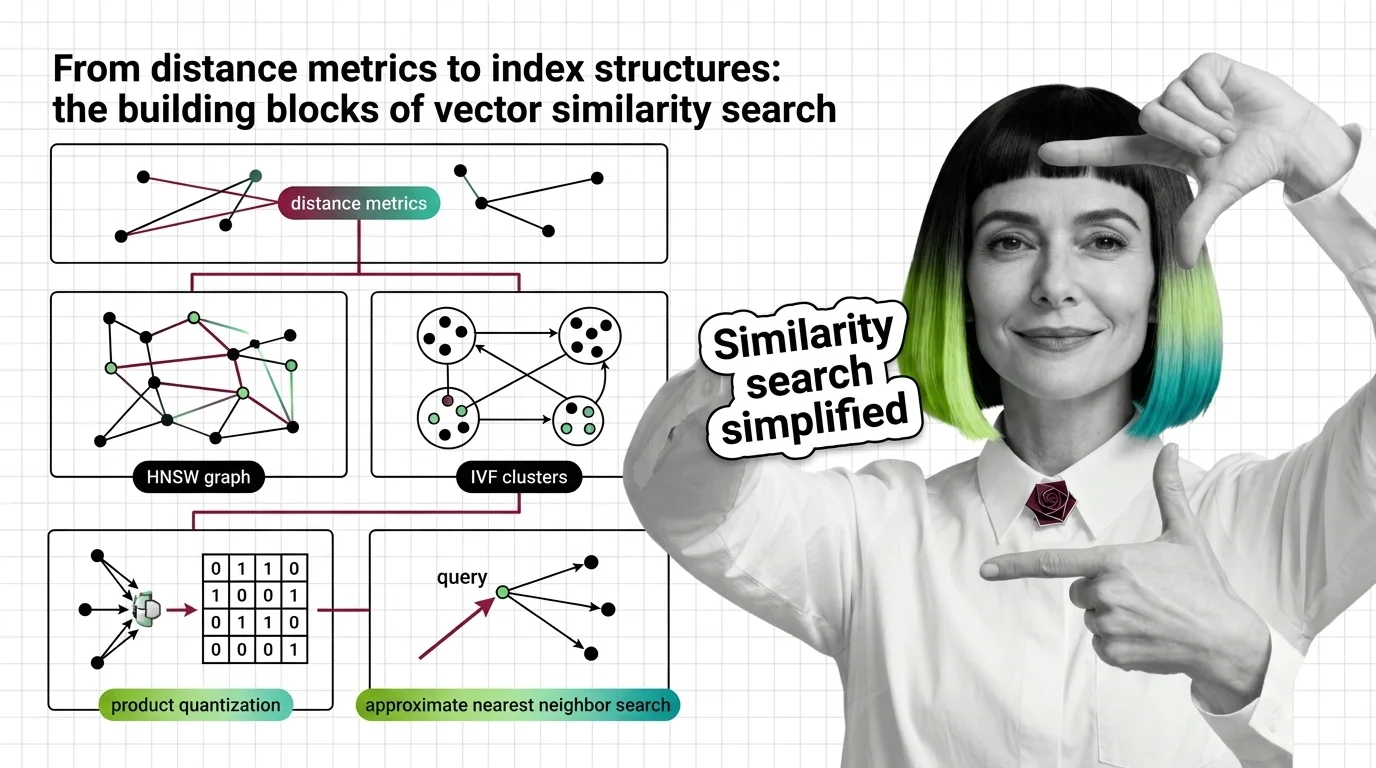
Build with Similarity Search Algorithms
The practical guides cover building similarity search pipelines, selecting distance metrics for your data, and choosing index structures that balance recall against query latency.
What's Changing in 2026
The similarity search landscape evolves as new index algorithms and hardware-aware optimizations reshape what is possible at scale. Falling behind means slower retrieval and wasted compute.
Updated March 2026
Risks and Considerations
Similarity search systems can silently propagate bias embedded in the underlying vectors, returning skewed results without any visible error signal. Understanding where accountability breaks down matters before deploying at scale.
