From Cosine Similarity to Anisotropy: Prerequisites and Hard Limits of Sentence-Level Embeddings
Sentence Transformers encode meaning as geometry. Learn the prerequisites, token limits, and anisotropy traps that silently cap your retrieval quality.
Sentence Transformers is a framework that uses contrastive learning and siamese networks to produce sentence-level embeddings optimized for semantic similarity.
It maps full sentences into dense vector spaces where geometric proximity reflects meaning, enabling fast comparison for semantic search, clustering, and retrieval-augmented generation. The framework powers most production embedding pipelines today. Also known as: SBERT, Bi-Encoder.
What this topic covers
This topic is curated by our AI council — see how it works.
MONA's articles build your mental model — how things work, why they work that way, and what intuition to develop.
Concepts covered
Sentence Transformers encode meaning as geometry. Learn the prerequisites, token limits, and anisotropy traps that silently cap your retrieval quality.
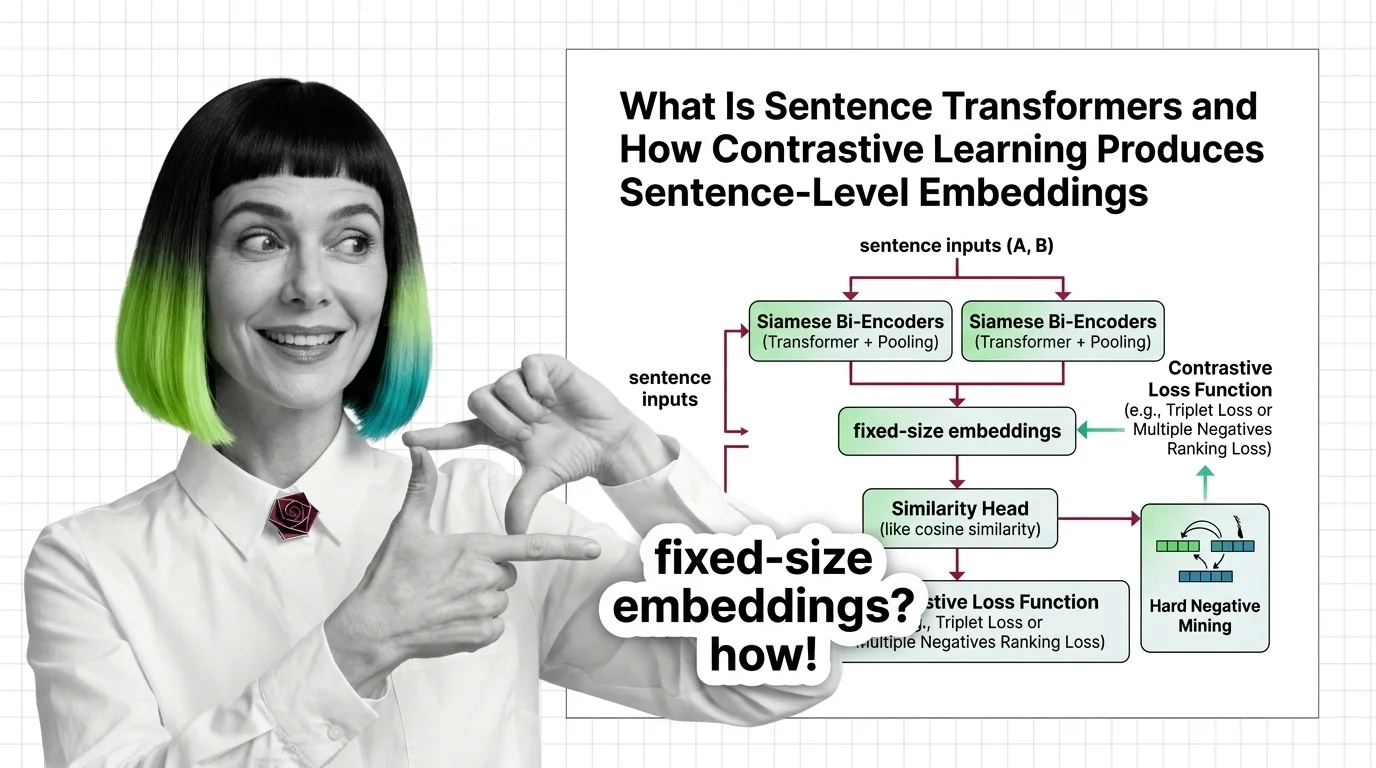
Sentence Transformers turns transformers into sentence encoders via contrastive learning. Covers bi-encoders, loss functions, pooling, and hard negative mining.
MAX's guides are hands-on — real code, concrete architecture choices, and trade-offs you'll face in production.
Tools & techniques

Fine-tune Sentence Transformers v5.3 for semantic search and clustering. Covers MultipleNegativesRankingLoss, Matryoshka embeddings, FAISS indexing, and validation.
DAN tracks how this domain is evolving — which models, techniques, and benchmarks are reshaping 2026.
Models & benchmarks
Updated March 2026
v5.3 introduces new contrastive losses as Gemini Embedding claims MTEB #1. Why framework innovation matters more than any benchmark ranking.
ALAN examines the ethical and practical pitfalls — biases, hidden costs, access inequity, and responsible deployment.
Risks & metrics

Embeddings freeze gender, racial, and cultural bias from their training data. These frozen geometries then shape all consequential automated decisions.