Sentence Transformers
Sentence Transformers is a framework that uses contrastive learning and siamese networks to produce sentence-level embeddings optimized for semantic similarity. It maps full sentences into dense vector spaces where geometric proximity reflects meaning, enabling fast comparison for semantic search, clustering, and retrieval-augmented generation. The framework powers most production embedding pipelines today. Also known as: SBERT, Bi-Encoder.
Understand the Fundamentals
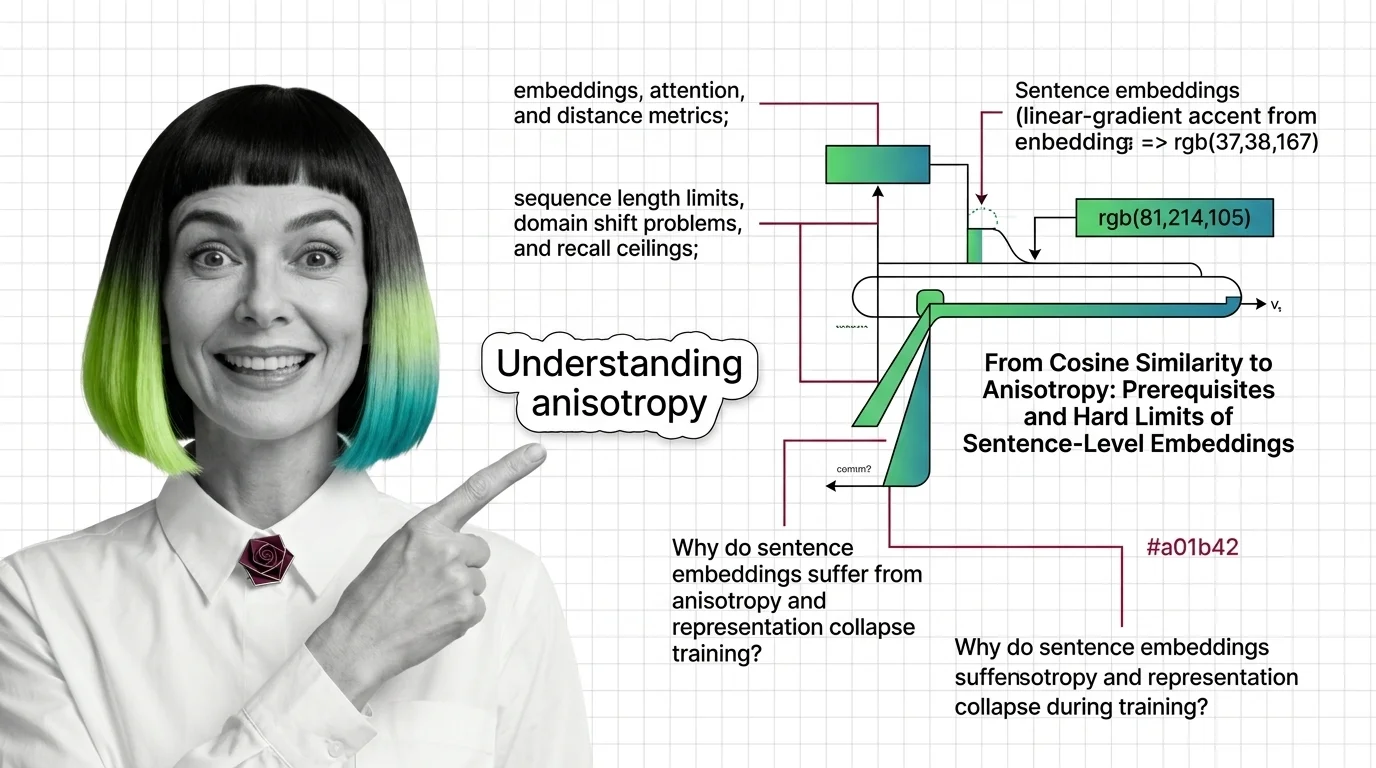
Sentence Transformers bridge the gap between word-level representations and whole-sentence meaning. Understanding how contrastive objectives shape embedding geometry reveals why some similarity comparisons succeed and others silently fail.
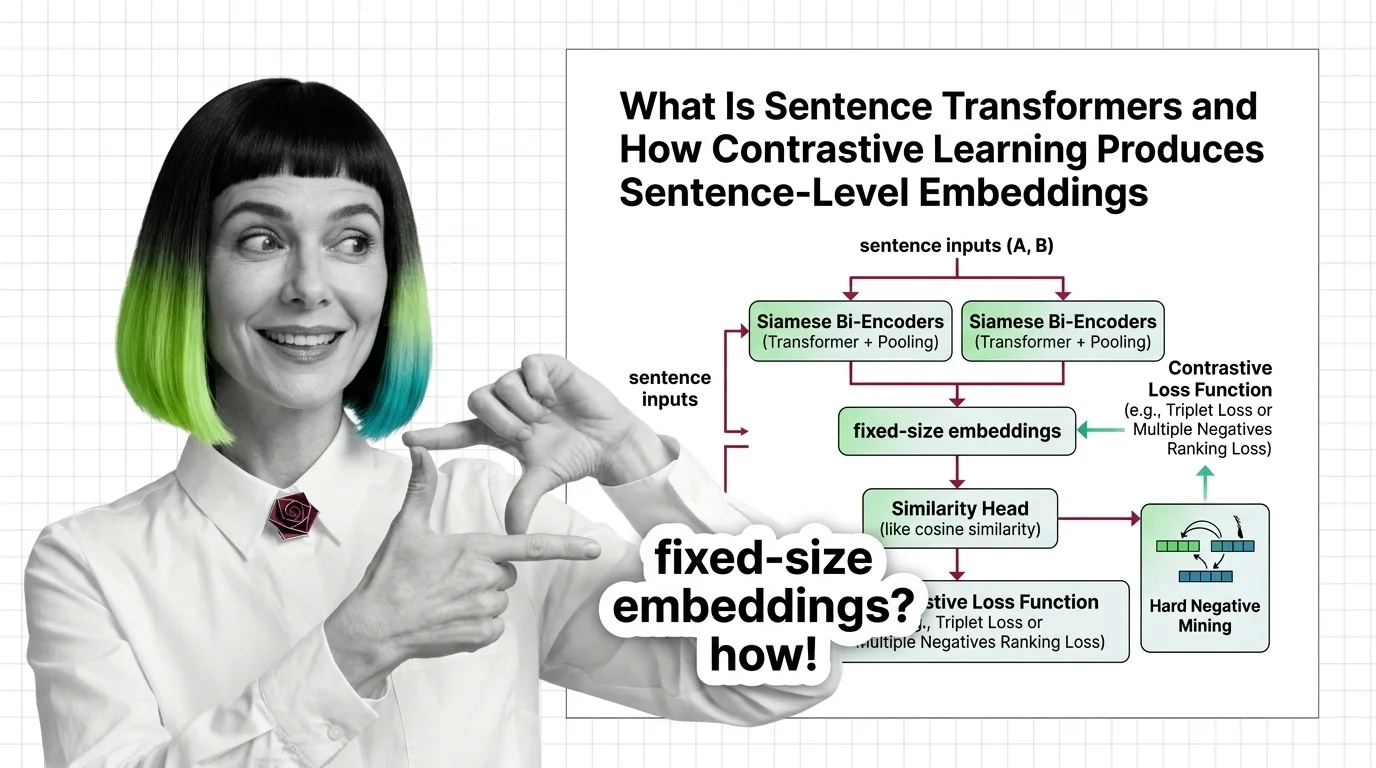
Build with Sentence Transformers
The guides cover fine-tuning embedding models on domain-specific data, selecting loss functions, and deploying inference pipelines that balance latency against recall in real-world semantic search systems.

What's Changing in 2026
The embedding landscape shifts rapidly as new architectures compete on benchmarks and multilingual coverage. Tracking which training approaches gain traction shapes how teams invest in retrieval infrastructure.
Updated March 2026
Risks and Considerations
Sentence embeddings encode social biases from training data into vector geometry, making discrimination invisible and hard to audit. Automated systems using these representations require careful fairness evaluation.
