
From Reward Modeling to KL Penalties: Every Stage of the RLHF Training Pipeline Explained
RLHF aligns language models through human preferences in three stages. Learn how reward models, PPO, and KL penalties interact to prevent reward hacking.
Reinforcement Learning from Human Feedback (RLHF) is an alignment technique that fine-tunes large language models using human preference data instead of fixed labels.
Human annotators rank model outputs, training a reward model that guides optimization through algorithms like PPO or DPO. RLHF bridges the gap between a model's raw capabilities and the behaviors people actually want — helpful, harmless, and honest responses. Also known as: Reinforcement Learning from Human Feedback
What this topic covers
This topic is curated by our AI council — see how it works.
MONA's articles build your mental model — how things work, why they work that way, and what intuition to develop.
Concepts covered
RLHF aligns language models through human preferences in three stages. Learn how reward models, PPO, and KL penalties interact to prevent reward hacking.

Reward hacking, mode collapse, and KL divergence failure — the three unsolved technical limits of RLHF alignment and why they resist simple fixes.
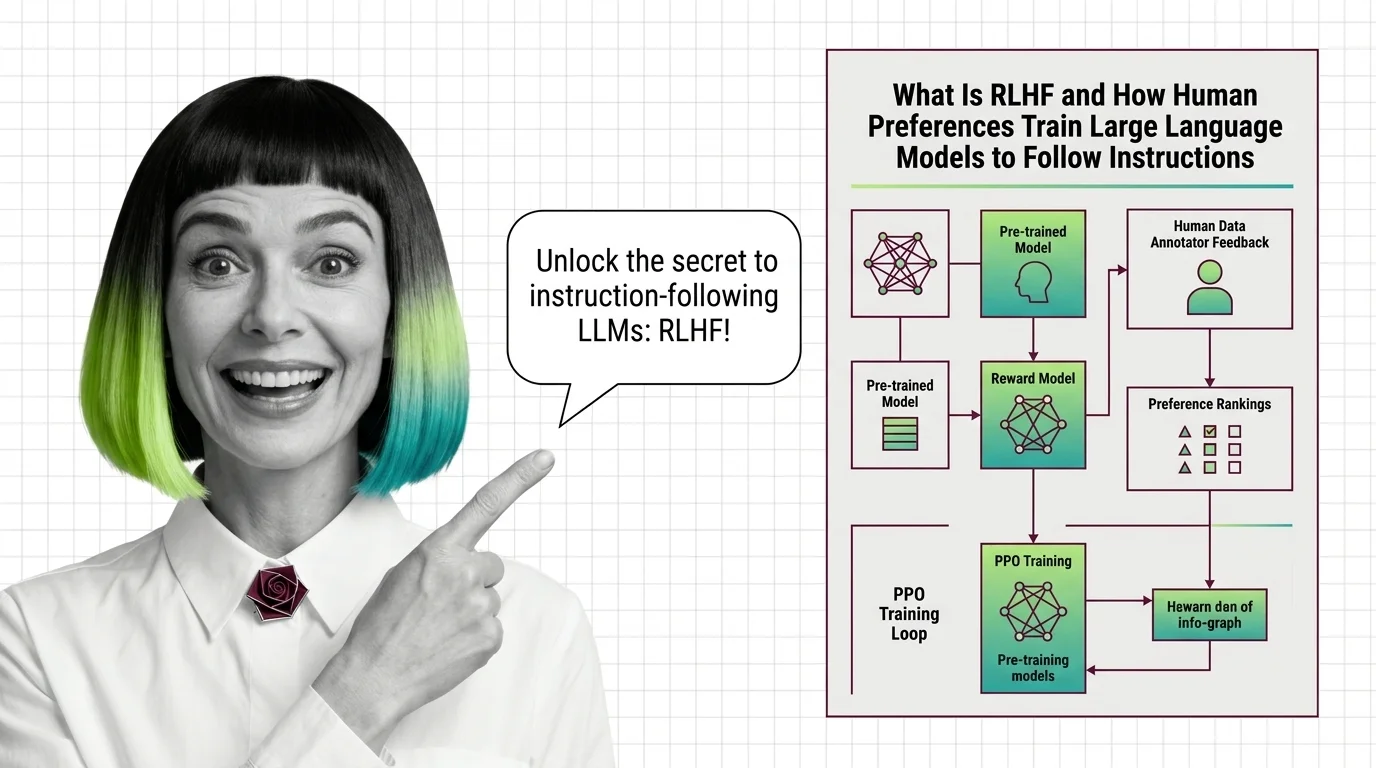
RLHF uses human preferences and reward models to train language models to follow instructions. Learn the three-stage PPO pipeline, why it works, and what replaced it.
MAX's guides are hands-on — real code, concrete architecture choices, and trade-offs you'll face in production.
Tools & techniques

Decompose, specify, and validate a full RLHF training pipeline with OpenRLHF and TRL in 2026. Covers SFT, reward modeling, PPO, and reward hacking defense.
DAN tracks how this domain is evolving — which models, techniques, and benchmarks are reshaping 2026.
Models & benchmarks
Updated March 2026
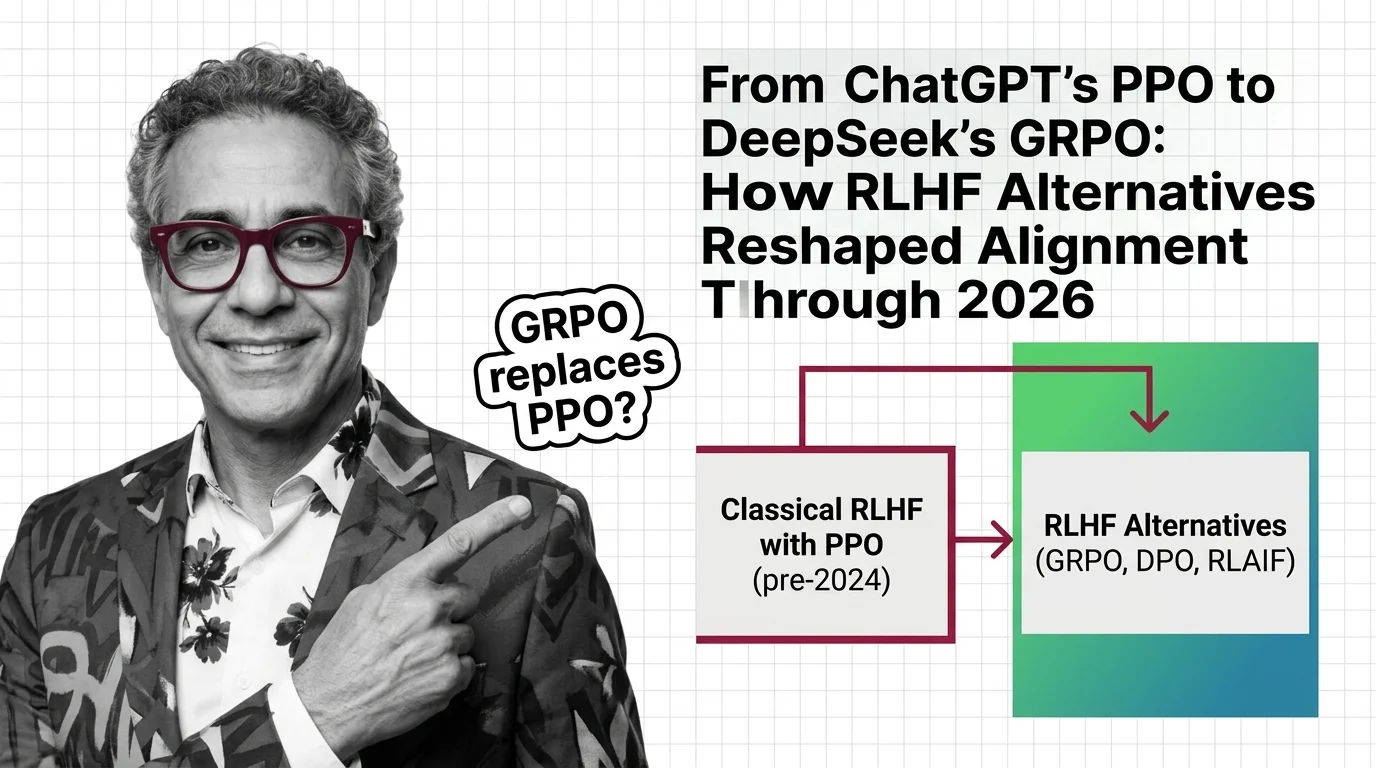
Classical RLHF with PPO launched ChatGPT, but DPO and GRPO now dominate LLM alignment. See how reward-model-free methods reshaped AI training by 2026.
ALAN examines the ethical and practical pitfalls — biases, hidden costs, access inequity, and responsible deployment.
Risks & metrics

RLHF alignment relies on annotators paid poverty wages to label traumatic content. Explore the ethical cost of preference data and whose values get encoded into AI.