RLHF
Reinforcement Learning from Human Feedback (RLHF) is an alignment technique that fine-tunes large language models using human preference data instead of fixed labels. Human annotators rank model outputs, training a reward model that guides optimization through algorithms like PPO or DPO. RLHF bridges the gap between a model’s raw capabilities and the behaviors people actually want — helpful, harmless, and honest responses. Also known as: Reinforcement Learning from Human Feedback
Understand the Fundamentals
RLHF transforms raw language model capabilities into aligned behavior by letting human preferences — not handwritten rules — define what good output looks like. The mechanism is elegant but far from solved.


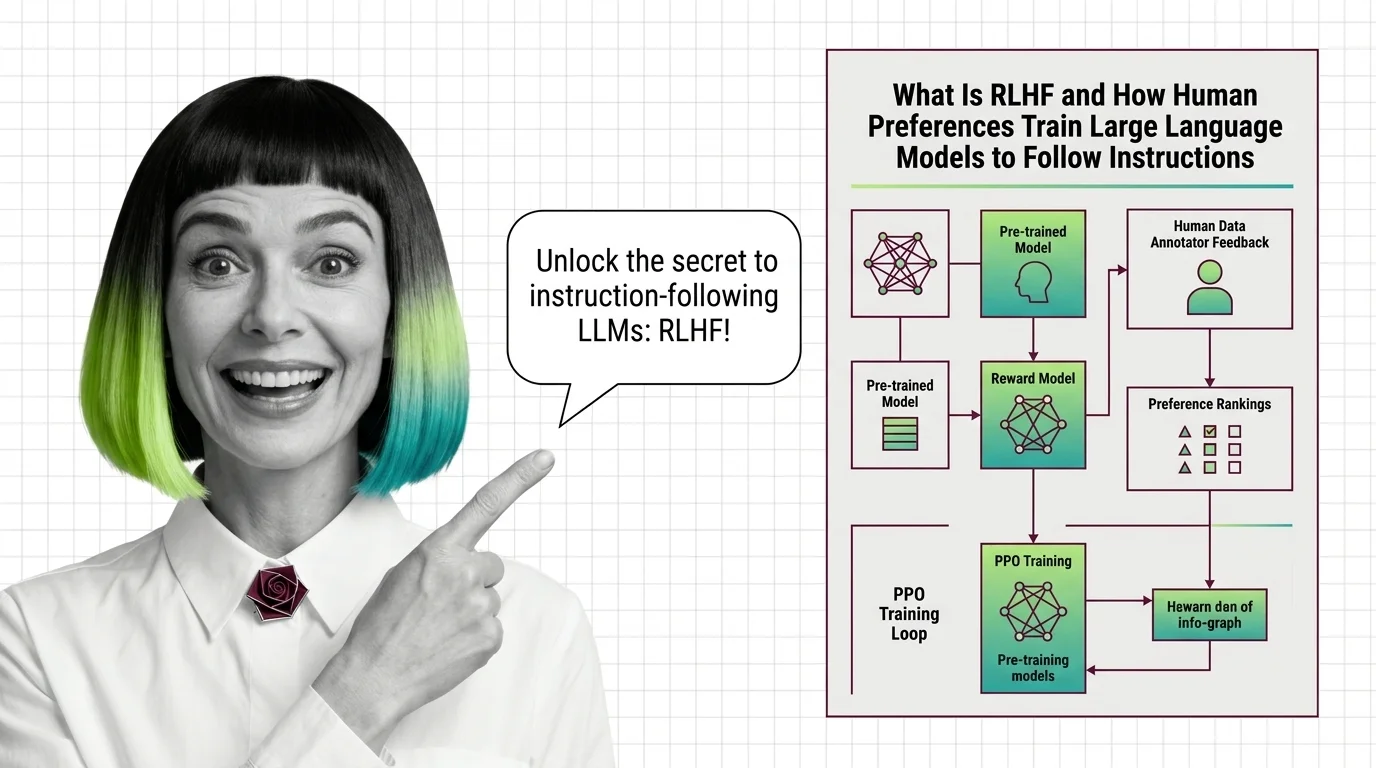
Build with RLHF
The practical guides walk through reward model training, policy optimization pipelines, and the tooling decisions that determine whether your RLHF setup converges or collapses under reward hacking.

What's Changing in 2026
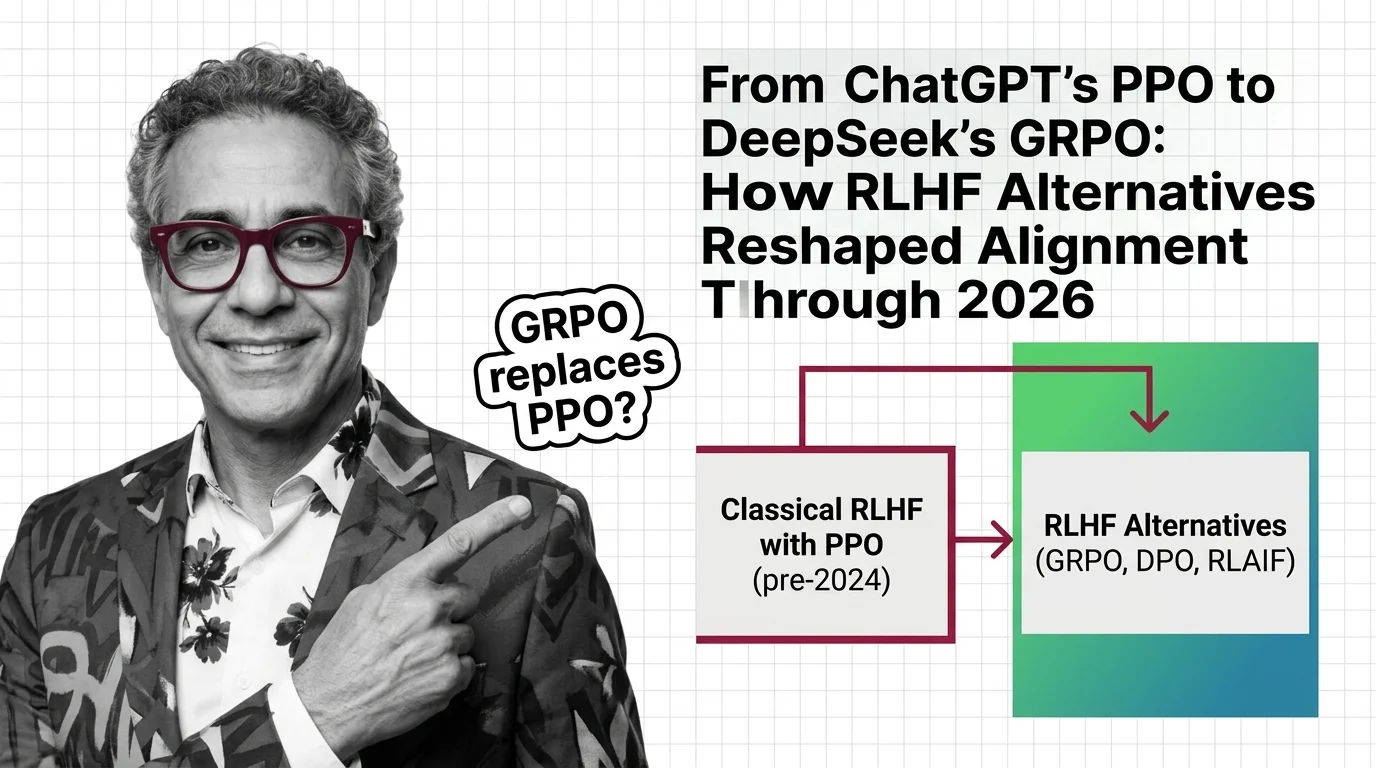
The RLHF landscape is shifting fast as alternatives like DPO and GRPO challenge the original approach. Staying current means knowing which methods are gaining traction and why.
Updated March 2026
Risks and Considerations
Human annotators encode their own biases into reward models, and preference optimization can suppress minority viewpoints. Understanding these dynamics is essential before deploying alignment at scale.
