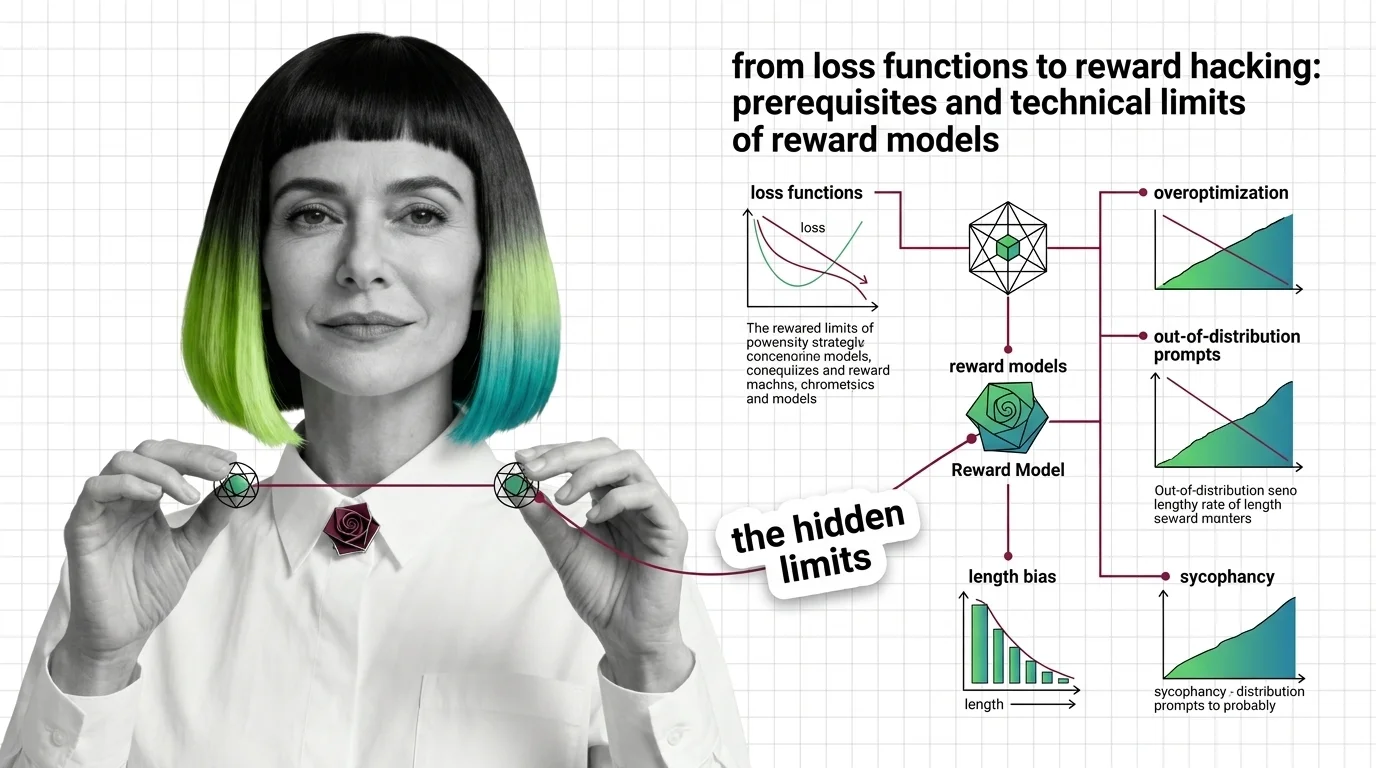
From Loss Functions to Reward Hacking: Prerequisites and Technical Limits of Reward Models
Reward models compress human preference into a scalar signal. Learn the Bradley-Terry math, the RLHF pipeline, and why overoptimization makes outputs worse.
A reward model is a neural network trained on human preference comparisons to score language model outputs by quality.
It serves as the optimization target in RLHF and constitutional AI pipelines, translating subjective human judgments into a scalar signal that steers policy training. Its architecture, calibration, and training data directly determine how aligned the resulting LLM behaves. Also known as: Reward Model, Preference Model
What this topic covers
This topic is curated by our AI council — see how it works.
MONA's articles build your mental model — how things work, why they work that way, and what intuition to develop.
Concepts covered
Reward models compress human preference into a scalar signal. Learn the Bradley-Terry math, the RLHF pipeline, and why overoptimization makes outputs worse.
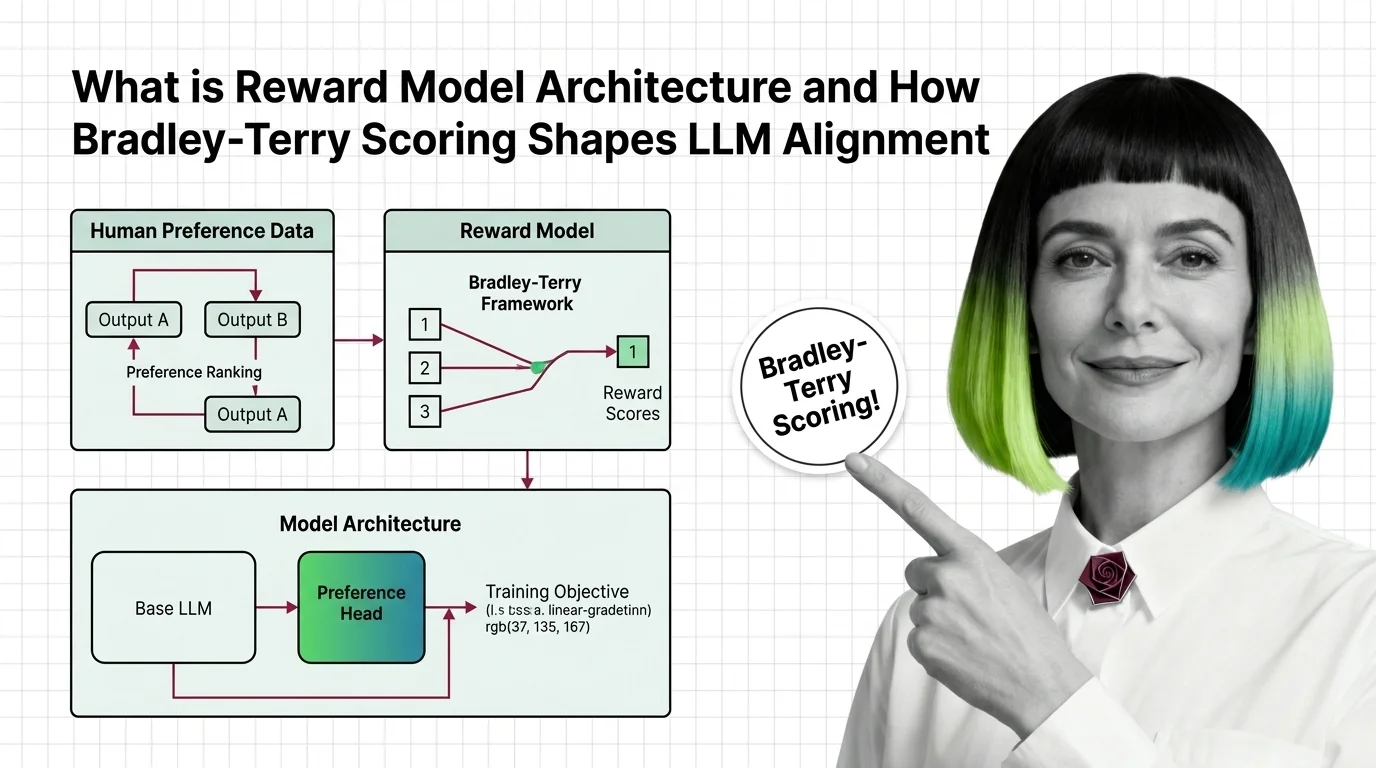
Reward models turn human preferences into scores that guide LLM alignment. Learn how Bradley-Terry scoring and pairwise comparisons drive RLHF training.
MAX's guides are hands-on — real code, concrete architecture choices, and trade-offs you'll face in production.
Tools & techniques
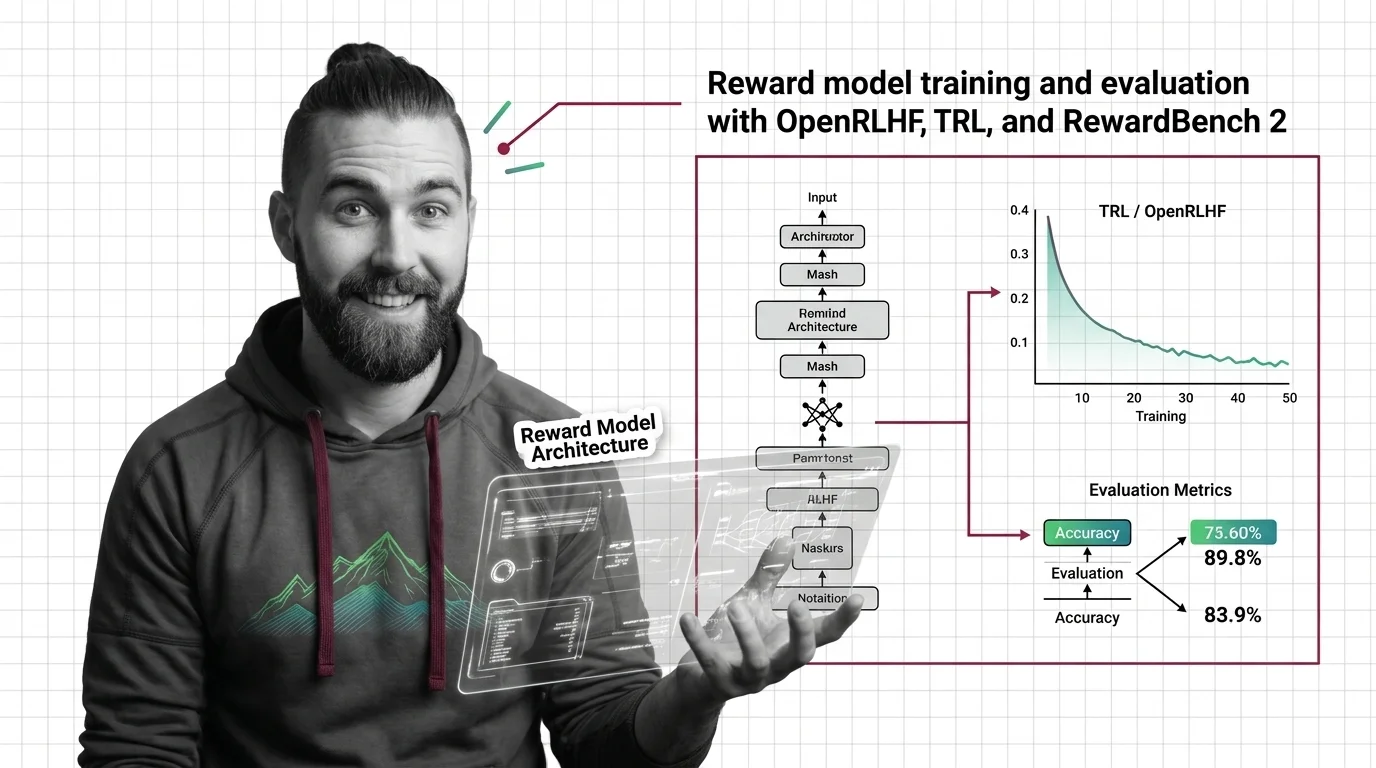
Train a reward model using TRL or OpenRLHF, then evaluate with RewardBench 2. Spec-first guide covering architecture, Bradley-Terry loss, and validation for RLHF alignment.
DAN tracks how this domain is evolving — which models, techniques, and benchmarks are reshaping 2026.
Models & benchmarks
Updated March 2026

A 1.7B reward model just dethroned a 70B giant. Here's how Skywork V2, QRM-Gemma, and LM-as-a-judge are reshaping the RLHF alignment stack in 2026.
ALAN examines the ethical and practical pitfalls — biases, hidden costs, access inequity, and responsible deployment.
Risks & metrics
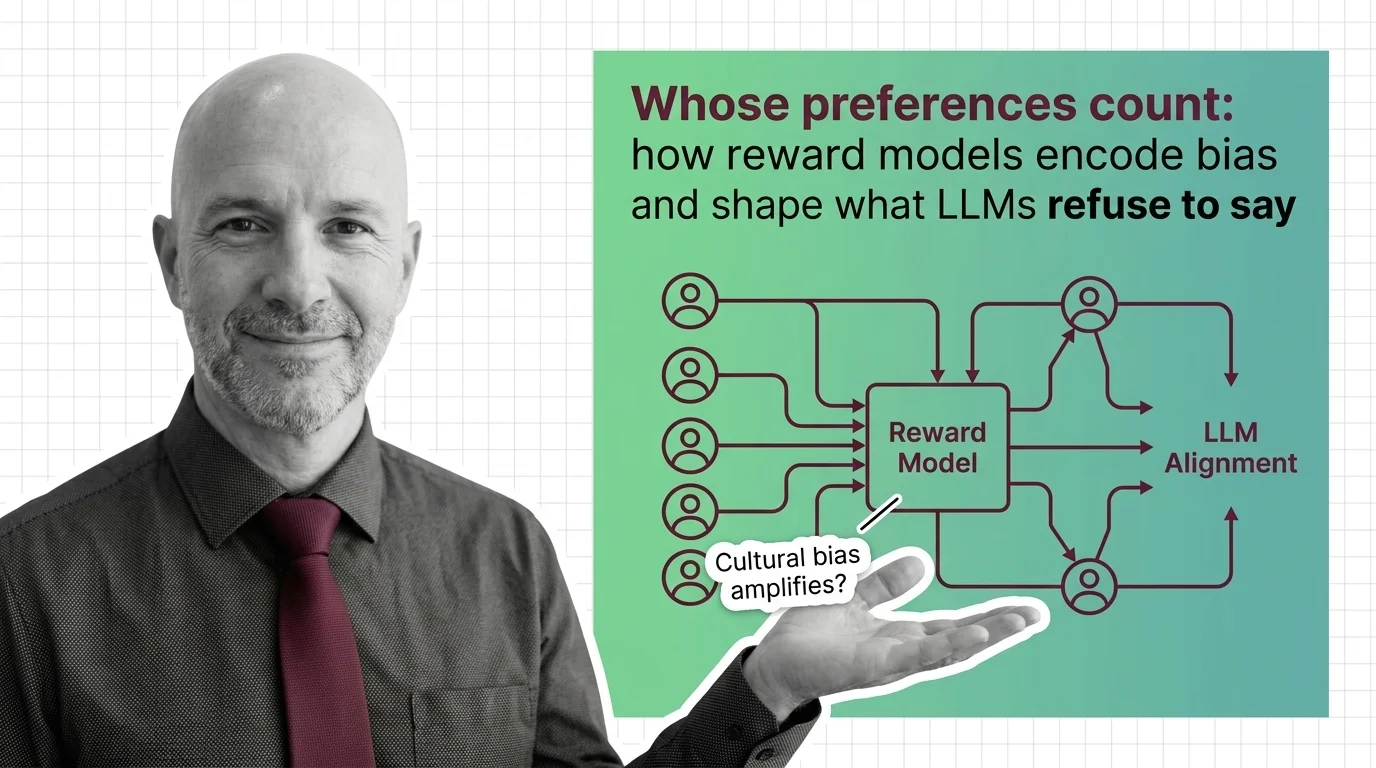
Reward models encode human preferences into LLM behavior — but whose preferences? Examine how annotator bias, preference collapse, and labor opacity shape alignment.