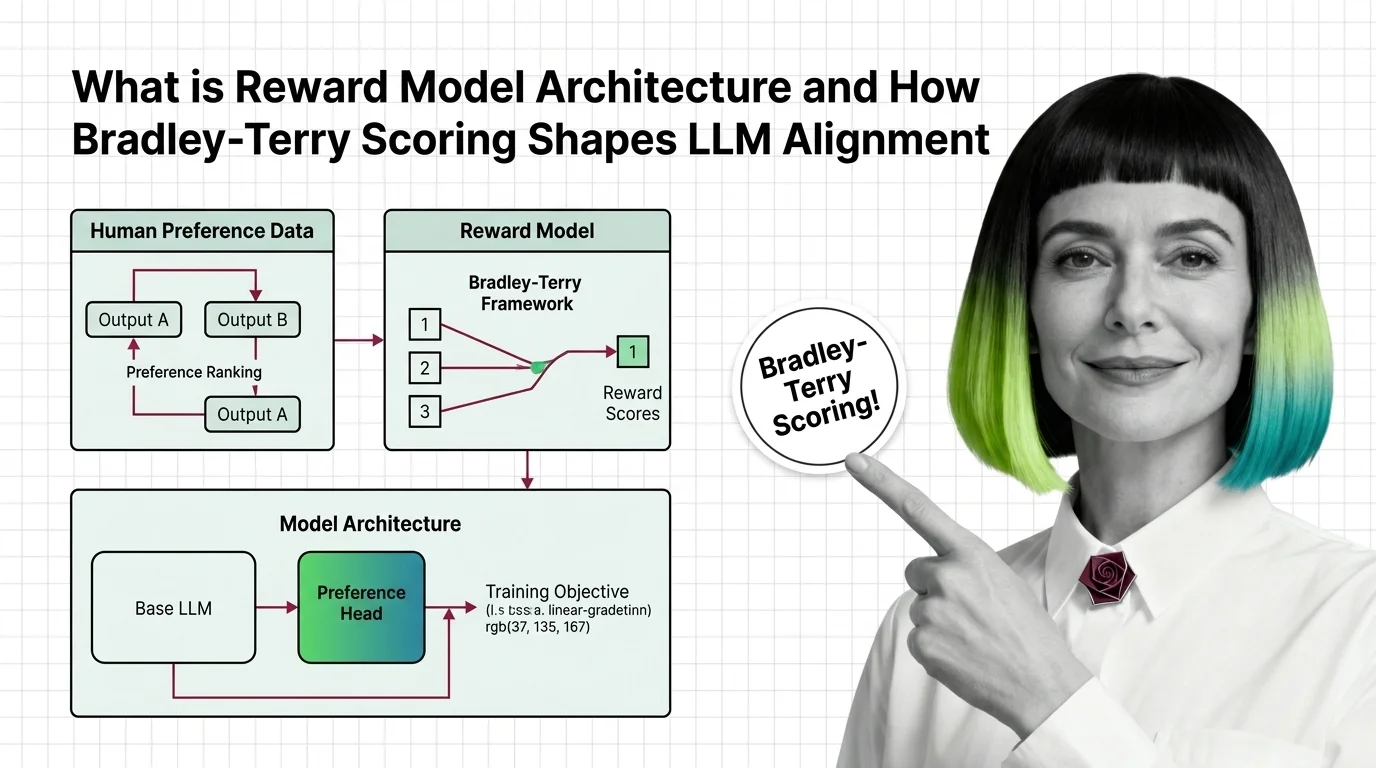
Reward Model Architecture
A reward model is a neural network trained on human preference comparisons to score language model outputs by quality. It serves as the optimization target in RLHF and constitutional AI pipelines, translating subjective human judgments into a scalar signal that steers policy training. Its architecture, calibration, and training data directly determine how aligned the resulting LLM behaves. Also known as: Reward Model, Preference Model
Understand the Fundamentals
Reward model architecture determines how human preferences become optimization signals. Understanding its design reveals why alignment outcomes depend as much on scoring mechanics as on the data annotators provide.
Build with Reward Model Architecture
The practical guides cover training reward models end-to-end, from dataset preparation and loss function selection to evaluation benchmarks and diagnosing reward hacking before it derails your policy.
What's Changing in 2026
Reward modeling is evolving rapidly as generative judges, multi-objective scoring, and process-level supervision challenge the original pointwise paradigm. Tracking these shifts is essential for anyone building alignment pipelines.
Updated March 2026

Risks and Considerations
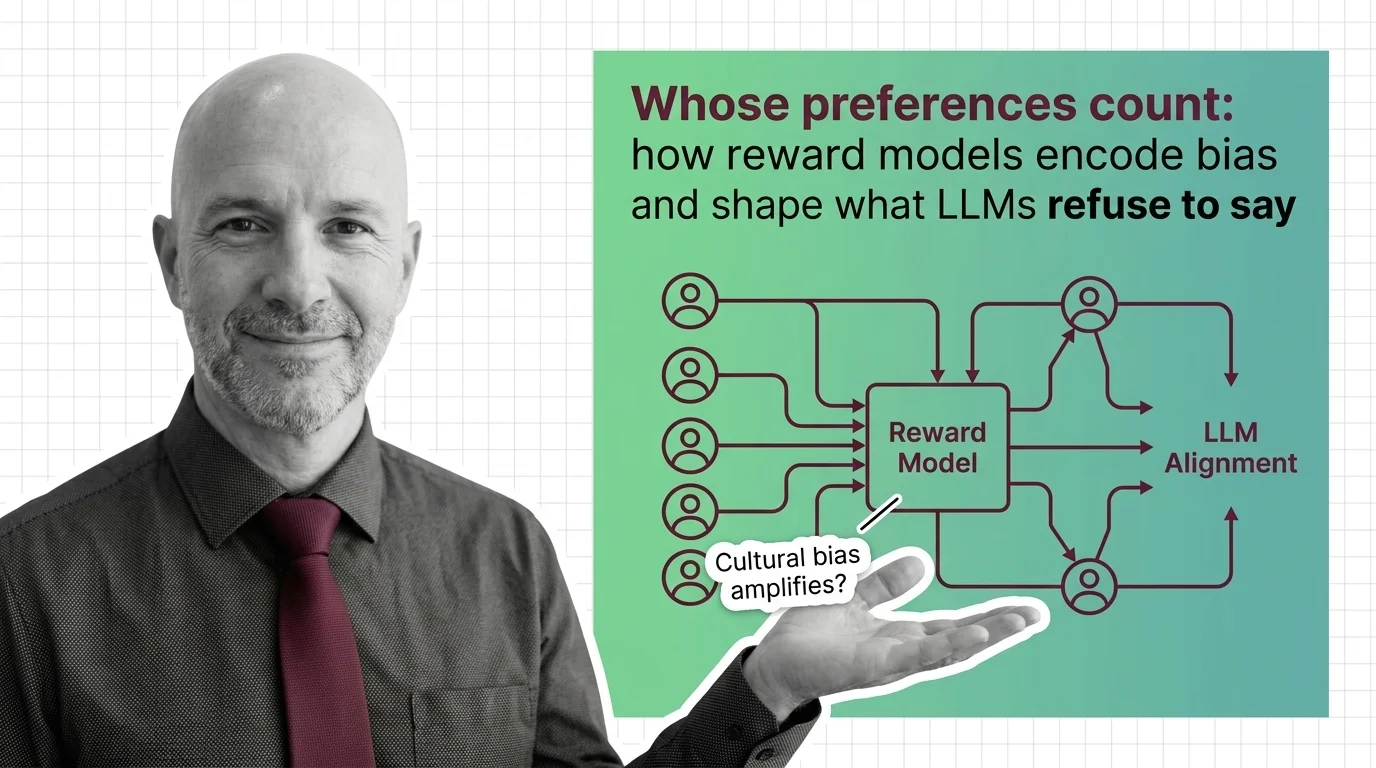
Reward models silently encode annotator biases and cultural assumptions into what counts as a good response. Deploying them without scrutiny risks systematically suppressing legitimate viewpoints at scale.