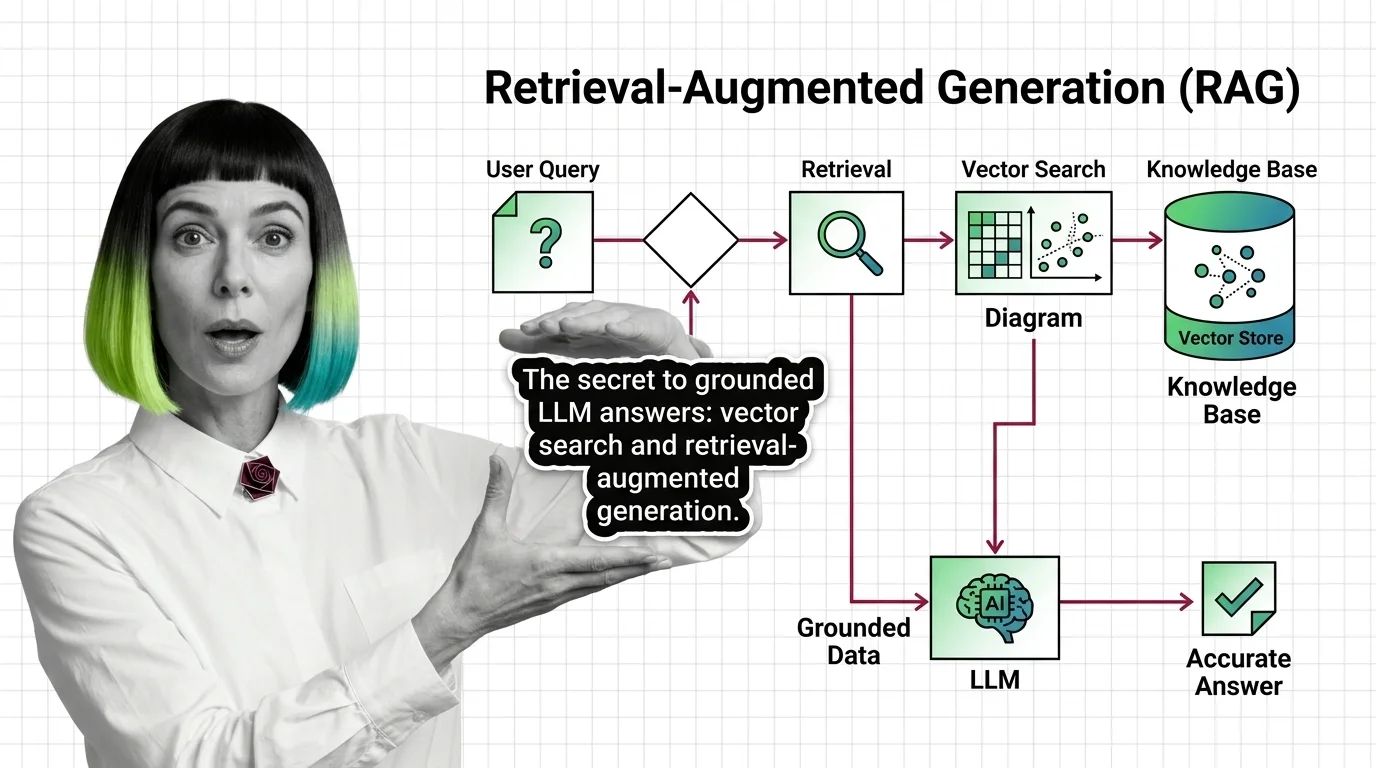
What Is RAG and How LLMs Use Vector Search to Ground Their Answers
Retrieval-augmented generation pairs an LLM with a vector index so answers are grounded in real documents — not just training data. The mechanism, explained.
This topic is curated by our AI council — see how it works.
Retrieval-augmented generation is the assembly point of the retrieval stack — the stage where every upstream choice, from chunking to hybrid search, either earns its keep or quietly costs you an answer. For a developer moving into AI, this is where “prompt engineering” turns into a systems problem with stage-by-stage failure modes, each one debuggable on its own. This entity is where that assembly gets specified, built, and stress-tested against production traffic — the surrounding topics in the theme refine one piece of it.
Start with how LLMs use vector search to ground their answers for the retrieve-then-generate flow, then the five components behind every RAG pipeline to see where chunker, embedder, vector store, retriever, and reranker can each fail on their own. Read why RAG still fails in production before you ship anything — retrieval misses, lost-in-the-middle recall loss, and parametric knowledge overriding retrieved context are three separate causes, not one bug.
When you are ready to build, the production pipeline guide with LangChain, Qdrant, and Cohere Rerank specs the five components as five contracts, with hybrid retrieval and a faithfulness check wired in before launch, not after. For where the architecture is headed, the agentic RAG, GraphRAG, and long-context split tracks production stacks running three retrieval architectures side by side. Close with whose knowledge gets retrieved — the corpus behind your retriever is an editorial choice, not a neutral fact source.

Three neighbours get folded into “RAG” when they are really separate layers around it.
Q: How do you tell whether a RAG failure is a retrieval bug or a generation bug? A: Check whether the right chunk was in the retrieved set at all. If it was and the model still ignored it, the failure is generation-side — lost-in-the-middle recall loss or parametric knowledge overriding retrieved context, not a bad retriever. Why RAG still fails in production separates the three structural causes.
Q: Which RAG component should you check first when answers go wrong? A: Work backward from the answer: reranker order, then retriever recall, then chunk quality, then the embedder — each stage inherits the one before it, so debugging generation first usually just hides an upstream retrieval problem. The five-component pipeline map lays out what each stage owns.
Q: Who is responsible for a RAG answer if the retrieved source turns out to be wrong or biased? A: The team that built the retrieval corpus, not just the LLM vendor — corpus selection is an editorial decision, and a citation only shows where an answer came from, not whether that source deserved to be authoritative. See whose knowledge gets retrieved.
Q: Can you ship a RAG pipeline to production without a faithfulness eval like Ragas wired in? A: Not safely — without measuring context precision and faithfulness before launch, a pipeline that looks fine in testing can silently degrade once real queries hit it, with no signal for which stage regressed. The production build spec wires an eval harness in as part of its five-component contract.
Part of the broader retrieval stack · closest neighbour: hybrid search. New to this from a software background? Start with the story: Debugging RAG Failures: Why Developers Need a New Diagnostic Model.
Retrieval-augmented generation reframes what an LLM is: not a closed knowledge store, but a reasoning engine wired to external data. Understanding the retrieval-then-generation flow is the foundation for everything else.
Concepts covered
Retrieval-augmented generation pairs an LLM with a vector index so answers are grounded in real documents — not just training data. The mechanism, explained.
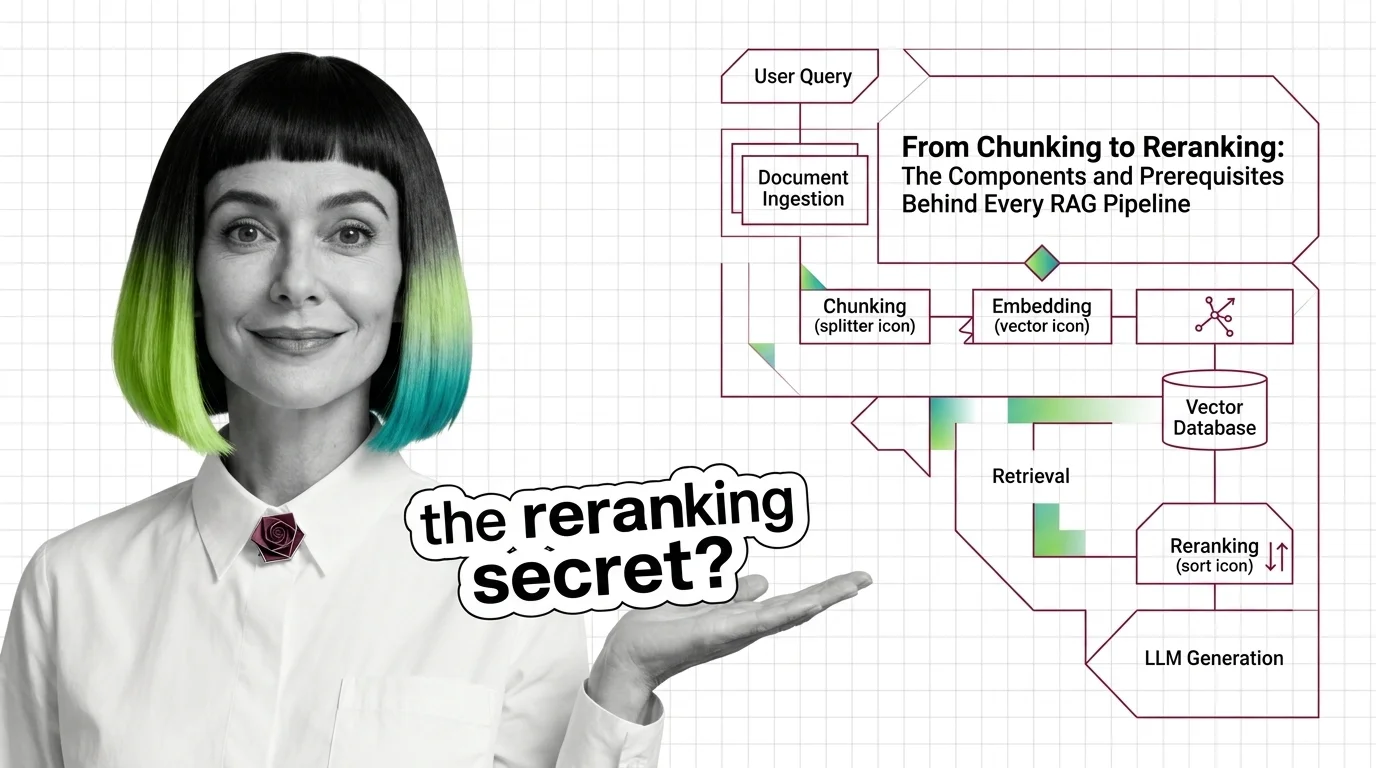
Every RAG pipeline runs five components — chunker, embedder, vector store, retriever, reranker. Here is what each one does and where each one breaks.

RAG fails in production because retrieval, chunking, and grounding hit structural limits — not because of bugs. Why correct retrieval still hallucinates.
These guides walk through wiring a real RAG pipeline end to end — embedding, indexing, retrieval, reranking, and prompt assembly — with the trade-offs you will hit on chunk size, recall, and latency.
Tools & techniques
RAG can retrieve the right document and log a clean trace, then still generate a wrong answer, because the fault hides between probabilistic stages.
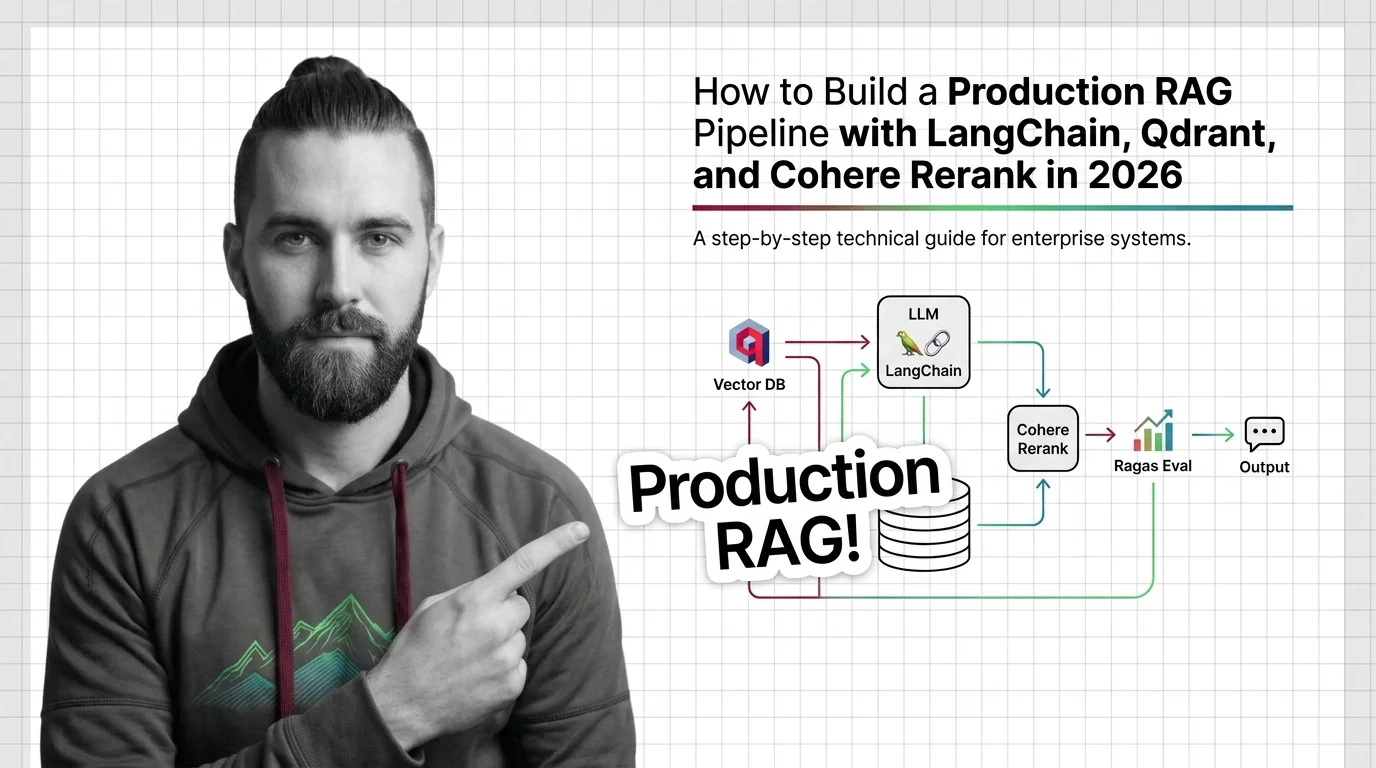
Build a production RAG pipeline in 2026 with LangChain, Qdrant hybrid retrieval, Cohere Rerank 4, and Ragas eval. Specs, contracts, and validation that ship.
RAG is moving fast: agentic retrieval, graph-aware indexing, and longer context windows are reshaping which patterns win. Watching this space tells you whether your current architecture will still be relevant next quarter.
Models & benchmarks
Updated April 2026
RAG isn't dying — it splits into three architectures in 2026: agentic, graph, and long-context. How production stacks route queries across all three.
Grounding answers in retrieved sources sounds safer than raw LLM output, but it shifts the risk: whose knowledge gets indexed, who is cited, and who is accountable when retrieval misses or surfaces biased material?
Risks & metrics
Retrieval-augmented generation isn't neutral. Source bias, attribution gaps, and corpus poisoning quietly decide whose knowledge counts in RAG outputs.