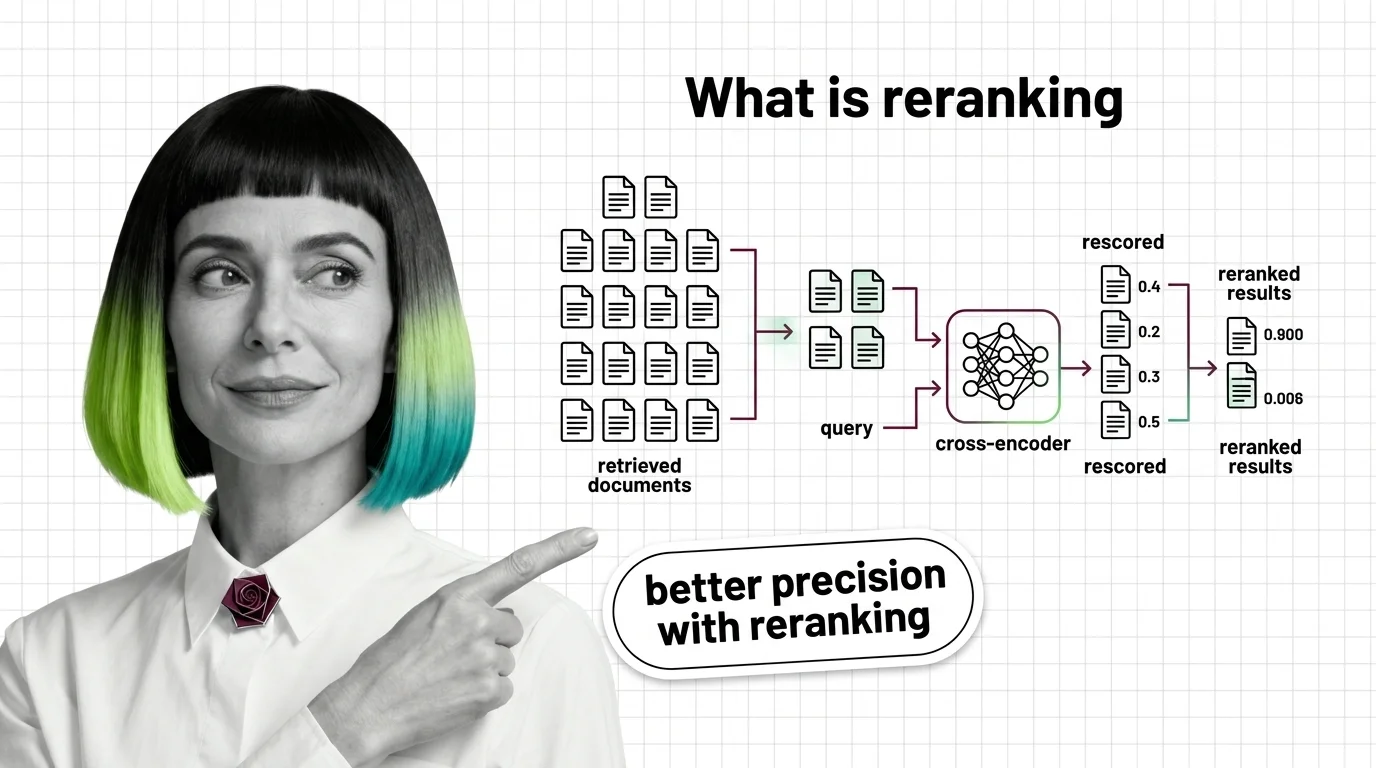
What Is Reranking and Why Cross-Encoders Rescore RAG Retrieval
Reranking splits recall and precision into two stages. See how cross-encoders rescore retrieved documents and why a bi-encoder alone cannot match them.
This topic is curated by our AI council — see how it works.
Every reranker sits at the same seam in the retrieval-augmented generation stack: downstream of the search that decided what a model could possibly see, upstream of the answer it gives. Get that seam wrong and no amount of prompt tuning recovers a document that never made the shortlist; get it right and one second-stage pass often buys more precision than a bigger first-stage retriever ever will. That trade only pays off once you know which candidates are worth the expensive rescore and which reranker actually earns its latency budget — which is what this topic’s six articles walk through in order.
Start with what reranking is and how cross-encoders rescore retrieved documents — the shortest path to the mechanism every later article assumes: a second, heavier model reading each query-document pair together instead of separately. Then read the prerequisites behind cross-encoders, bi-encoders, and listwise scoring in the same sitting — it maps the three reasoning shapes a reranker can take, which decides how much latency you are actually buying. Before you wire one into a pipeline, the hard technical limits of cross-encoder reranking is worth the ten minutes: latency scales quadratically with token length, and relevance learned on general benchmarks drifts on specialized domains.
When you are ready to add one, the integration guide for Cohere Rerank-4-Pro, Voyage Rerank-2.5, and Zerank-2 compares the managed APIs against self-hosting and flags the licence trap hiding in one of them. For where the market moved since, the open-vs-closed reranker race on the 2026 Agentset leaderboard tracks how fast open-weight models closed the quality gap. Close with the ethical cost of outsourcing search ranking to a closed API — if a vendor’s scoring decides what your users see, read it before the contract renews, not after.

Two neighbours get folded into “reranking” in planning docs, and the confusion changes which fix a team reaches for.
Q: Should I use a hosted reranking API or self-host an open-weight model? A: Self-hosting BGE Reranker v2-m3 or mxbai-rerank-large-v2 only pays off once you have measured retrieval quality and have the serving budget to run it; otherwise a managed API is the faster path. The integration guide compares both.
Q: Are open-weight rerankers now as good as Cohere or Voyage? A: On the Agentset leaderboard, yes — a 4B open-weight reranker now leads the ELO ranking ahead of Cohere’s flagship, and the absolute quality gap on nDCG@10 has closed too. The 2026 leaderboard race tracks the shift.
Q: Does a reranker’s licence matter if I only call it through a hosted API? A: Yes — hosted access does not erase the underlying licence. Zerank-2 ships under a CC-BY-NC licence that blocks commercial use even through a paid endpoint, exactly the kind of fine print outsourced ranking decisions hide from procurement.
Q: Why does a reranker that scored well in benchmarks misrank my legal or financial documents? A: Most cross-encoders are trained on MS-MARCO-style web queries, and that relevance judgment drifts on legal, financial, and argument-heavy text with a different notion of “relevant.” The hard limits of cross-encoder reranking covers this wall alongside latency.
Part of the retrieval-augmented generation theme · closest neighbour: hybrid search. Coming to RAG pipelines from classical software engineering? Start with the story: Debugging RAG Failures: Why Developers Need a New Diagnostic Model.
Reranking sits between fast initial retrieval and the LLM, scoring each candidate document against the query with far more precision. Understanding why this two-stage design beats single-stage search is the foundation.
Concepts covered
Reranking splits recall and precision into two stages. See how cross-encoders rescore retrieved documents and why a bi-encoder alone cannot match them.
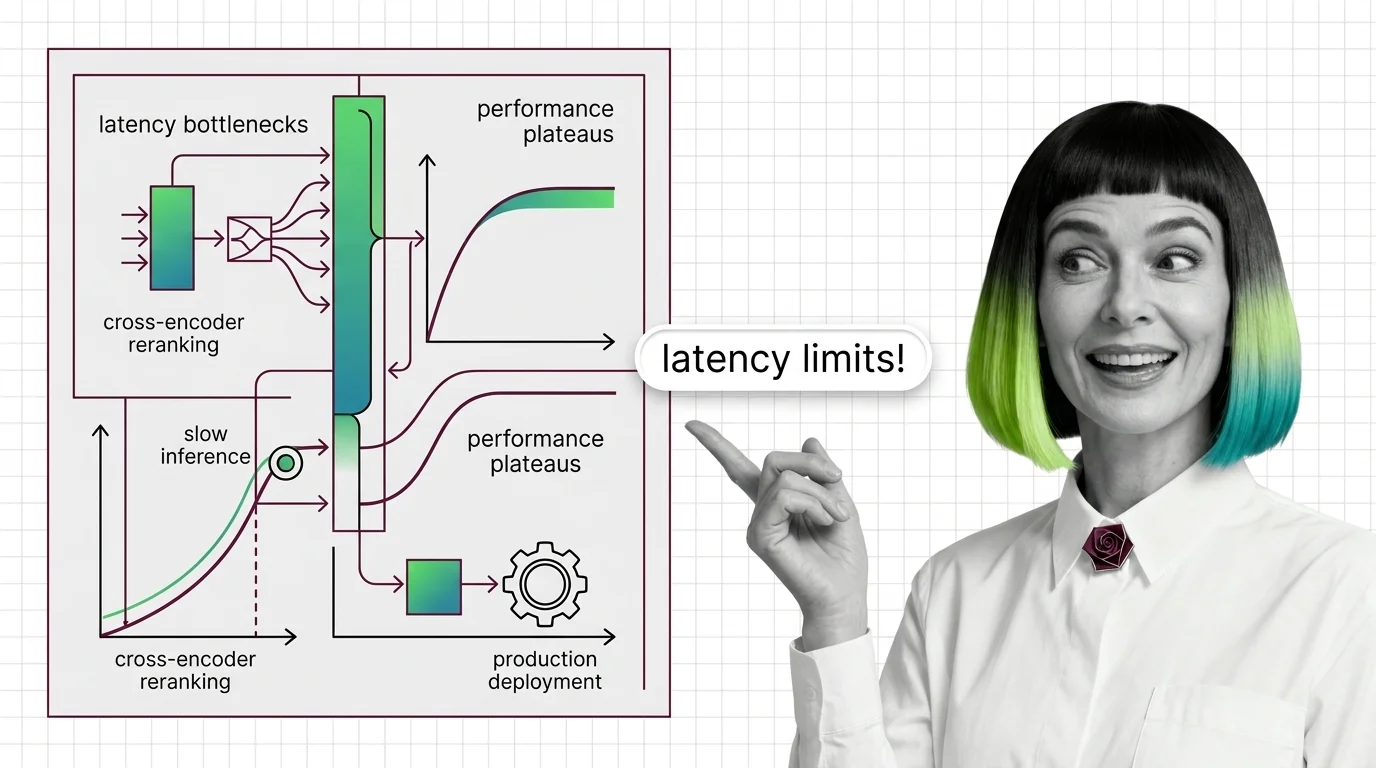
Cross-encoder rerankers hit two architectural walls: latency scales linearly with candidates and quadratically with tokens, plus MS-MARCO domain drift.
A reranker reorders the top candidates from vector search using a heavier model. Cross-encoders, bi-encoders, and listwise scoring explained.
Adding a reranker is one of the highest-leverage changes you can make to a RAG pipeline. These guides walk through API integration, latency budgeting, and trade-offs between hosted and self-hosted rerankers.
Tools & techniques
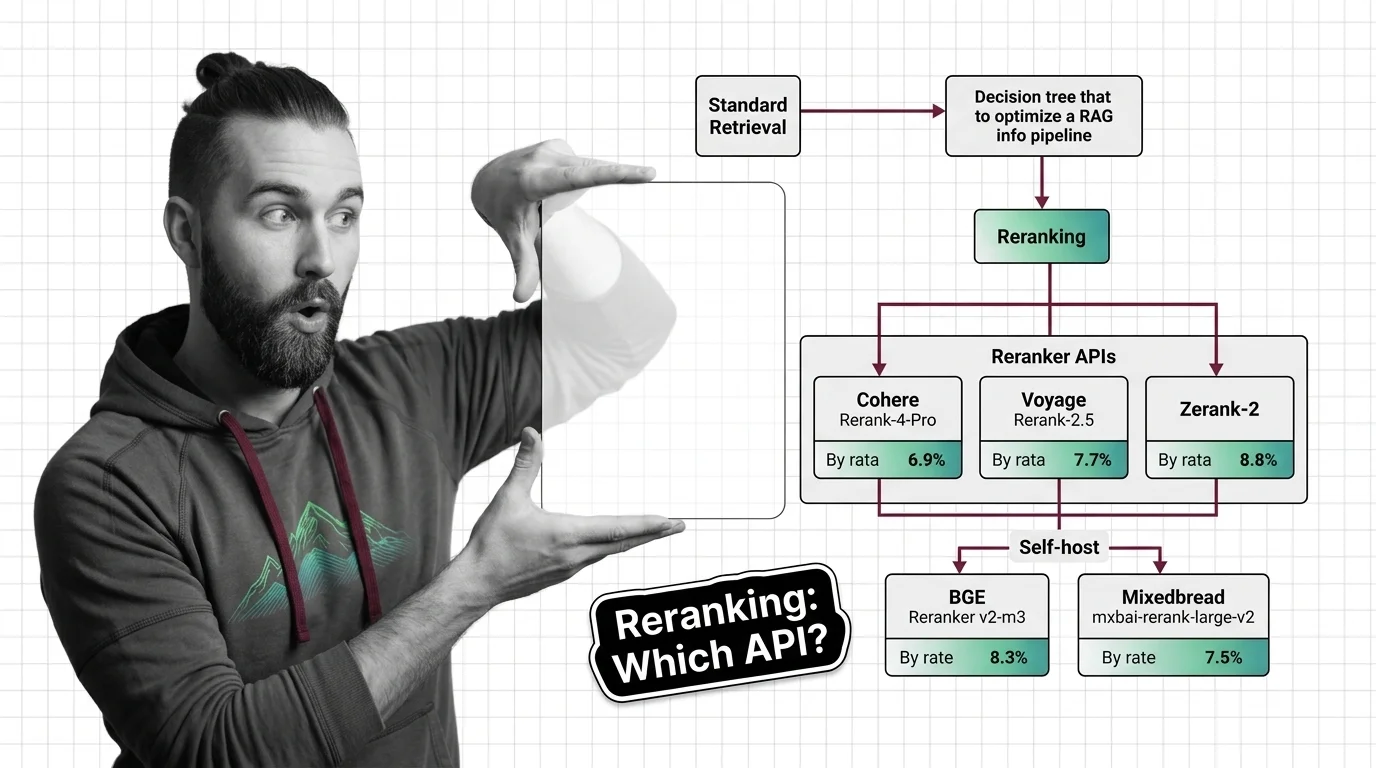
Add a reranker to your RAG pipeline in 2026. Compare Cohere Rerank 4 Pro, Voyage Rerank-2.5, Zerank-2, and self-hosted BGE/Mixedbread options.
The reranker landscape moves fast — new models, leaderboards, and licensing shifts redraw the map every few months. Tracking who leads on quality, latency, and cost decides which dependency you bet on.
Models & benchmarks
Updated April 2026

The 2026 Agentset reranker leaderboard shows a 4B open-weight model topping Cohere's flagship — and on absolute retrieval quality, the gap is gone.
Outsourcing ranking decisions to a third-party model means trusting opaque scoring on user-facing results. Consider licensing, data flow, vendor lock-in, and what happens when the API behind your search changes overnight.
Risks & metrics

Top rerankers come with non-commercial licenses or closed APIs. Reranking quality is rising; our ability to inspect the scoring is not.