Red Teaming for AI
Red teaming for AI is adversarial testing where humans or automated systems deliberately probe an AI model to find failures, harmful outputs, jailbreaks, and edge cases before production deployment. Teams simulate real-world attacks to uncover vulnerabilities that standard evaluations miss, including bias, toxicity, and safety failures. The practice draws from military and cybersecurity traditions but adapts them for the unique risks of generative AI systems. Also known as: AI Red Teaming, Adversarial Testing
Understand the Fundamentals
Red teaming reveals failure modes that standard benchmarks cannot surface. These explainers break down how adversarial probing works, what attack taxonomies exist, and where automated methods fall short of human creativity.

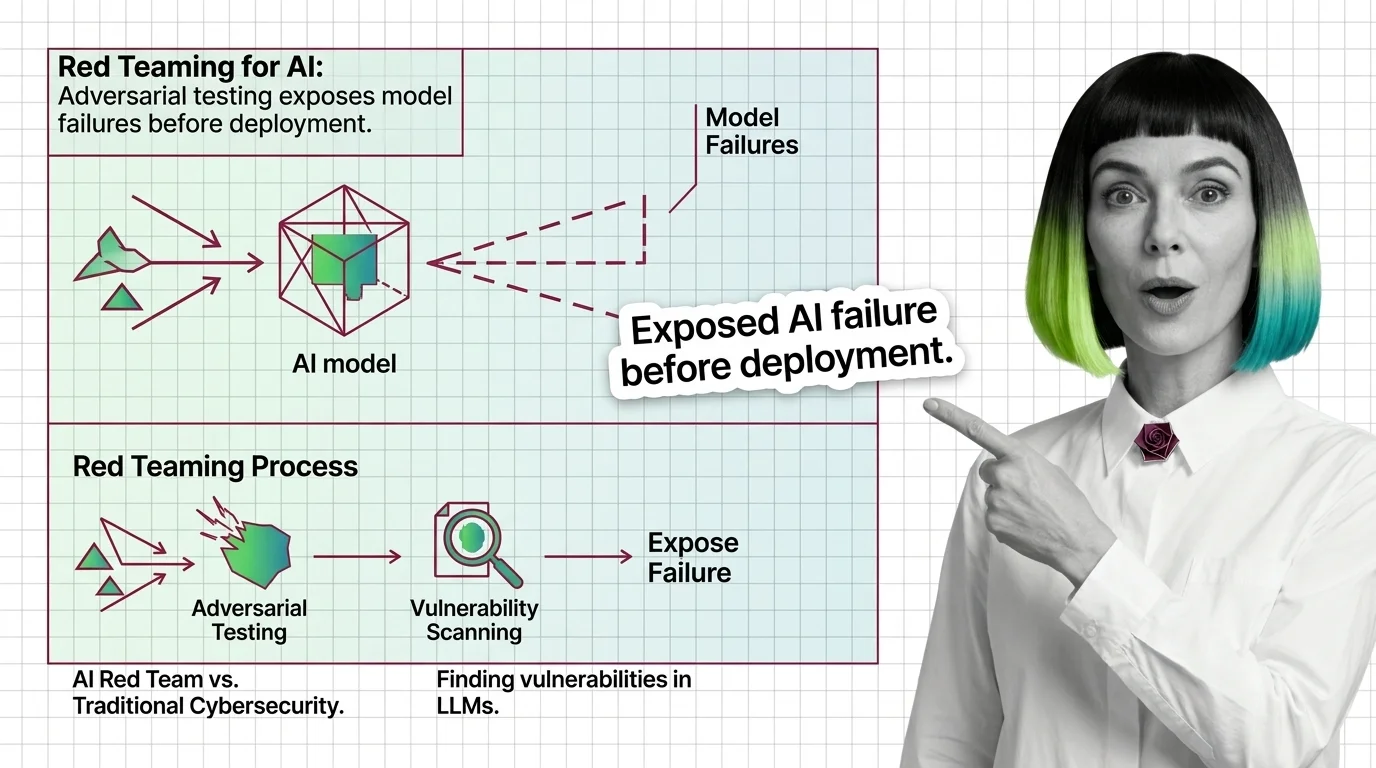
Build with Red Teaming for AI
Running a red team exercise involves choosing tools, designing attack scenarios, and interpreting results under time constraints. These guides cover practical workflows from setup through remediation.

What's Changing in 2026
Red teaming has shifted from an ad hoc practice to a regulatory expectation in a remarkably short time. Following this space means tracking the policies, mandates, and tooling shaping deployment standards.
Updated March 2026
Risks and Considerations
Who conducts red teaming, which vulnerabilities get prioritized, and whose harms are tested for are deeply political questions. These pieces examine the power dynamics and blind spots in current practice.
