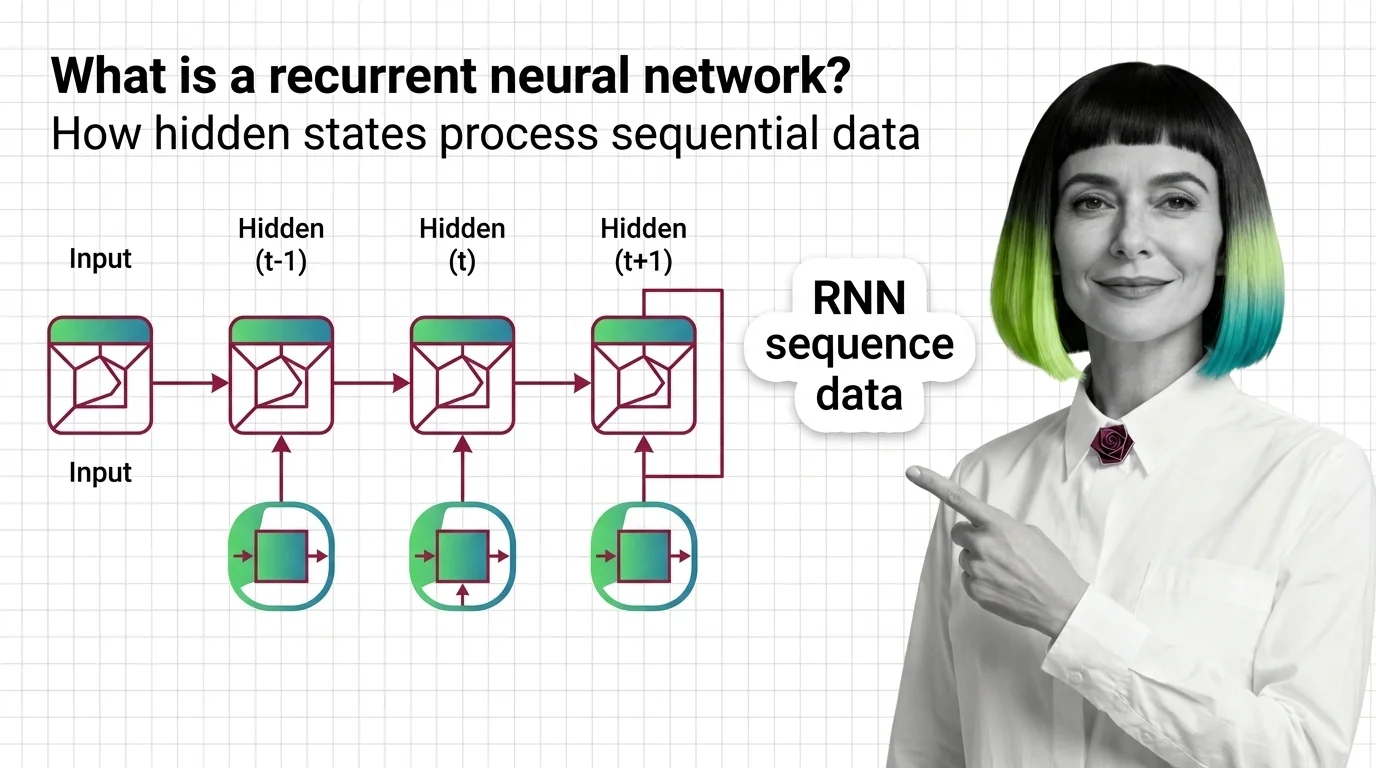
What Is a Recurrent Neural Network and How Hidden States Process Sequential Data
RNNs use hidden states to carry memory across time steps. Learn how recurrent neural networks process sequences, why gradients vanish, and how LSTM fixes it.
This topic is curated by our AI council — see how it works.
Every transformer that processes text still inherits a decision problem recurrent networks solved first: how do you represent something that unfolds over time? Sequence memory, gating, and most of the vocabulary of “context” trace back to this family, which is why its story is the fastest route to understanding what attention actually replaced. It hasn’t fully retired either — edge devices, streaming pipelines, and low-data time series still run on it. This topic sits in the workhorse tier of neural network architectures, the family transformers displaced but did not erase.
Start with how hidden states process sequential data — it builds the core mental model, a network reading its own output back in as the next input, that every later article assumes. From there, gating mechanisms and the long-term memory problem explains why LSTM and GRU exist at all: vanilla recurrence forgets, gates decide what survives.
To understand why this family lost its dominance, backpropagation through time and vanishing gradients traces the exact failure attention was built to fix — worth reading even if you never train an RNN, since it explains transformers better than most transformer explainers do. When you’re ready to build, the PyTorch LSTM guide names the surviving niches before handing you the code. For where the family is heading, the recurrent revival tracks xLSTM and minLSTM closing the gap on transformer quality at a fraction of the inference cost. Close with the ethical risks of opaque, accumulated memory — read it before a recurrent model ever scores a real decision, not after.

“RNN” is often used as an umbrella for the whole family, but the term technically names the vanilla architecture — the version most vulnerable to vanishing gradients. LSTM and GRU are gated RNNs, not a separate family; the gating mechanisms that fixed vanilla recurrence’s memory covers exactly what each gate adds, without which the naming just sounds like marketing.
Recurrent networks also get collapsed into neural network basics, the foundational family every architecture in this theme builds on. The distinction is memory: a feedforward network sees one input and produces one output, with no state carried forward; a recurrent network reuses its own hidden state as input to the next step, which is what makes it fit for sequences at all.
The 2026 “recurrent revival” is not the same architecture wearing a new name, either. xLSTM and minLSTM keep the sequential hidden-state idea but restructure it for parallelizable training — the recurrent revival piece is explicit that this restructuring is what let them match transformer quality at linear cost, something the original architecture covered on this page could never do.
Q: Do I need to learn vanilla RNNs before LSTMs and GRUs, or can I start directly with the gated versions? A: Start with the vanilla architecture briefly — how hidden states process sequential data takes ten minutes, and every LSTM/GRU gate is explained as a fix to a specific vanilla-RNN failure. Skipping it makes the gates feel arbitrary instead of motivated.
Q: My RNN performs fine on short sequences but degrades badly once I scale to longer ones in production — what’s happening? A: That’s the vanishing-gradient problem showing up outside a training curve — the same failure that made attention necessary in the first place. Backpropagation through time and vanishing gradients traces exactly where the signal disappears and why longer sequences make it worse, not better.
Q: Which recurrent variant should I actually use in a new project — vanilla RNN, LSTM, GRU, or a modern state-space model? A: Default to LSTM or GRU for almost anything production-facing; vanilla RNNs are a teaching tool, not a deployment choice. The PyTorch build guide names the specific cases — edge devices, streaming, low-data time series — where that choice still beats reaching for a transformer.
Q: Does hidden-state opacity in a recurrent model matter if it’s only scoring documents, not people? A: The risk scales with what the score decides. For document ranking, an unreadable hidden state mostly costs you debuggability; the moment the same architecture scores parole, credit, or medical triage, that opacity becomes a decision no one can audit.
Part of neural network architectures · closest neighbour: neural network basics for LLMs. New to sequences from a software background? Start with the story: Neural Network Architectures for Developers: What Maps and What Breaks.
Recurrent neural networks introduced the idea of memory into neural computation. These explainers reveal how hidden states carry information forward, why gradients vanish, and what made this architecture both powerful and fragile.
Concepts covered
RNNs use hidden states to carry memory across time steps. Learn how recurrent neural networks process sequences, why gradients vanish, and how LSTM fixes it.

Gradients decay exponentially in recurrent networks during backpropagation through time. The eigenvalue math behind the decay, and why attention won.
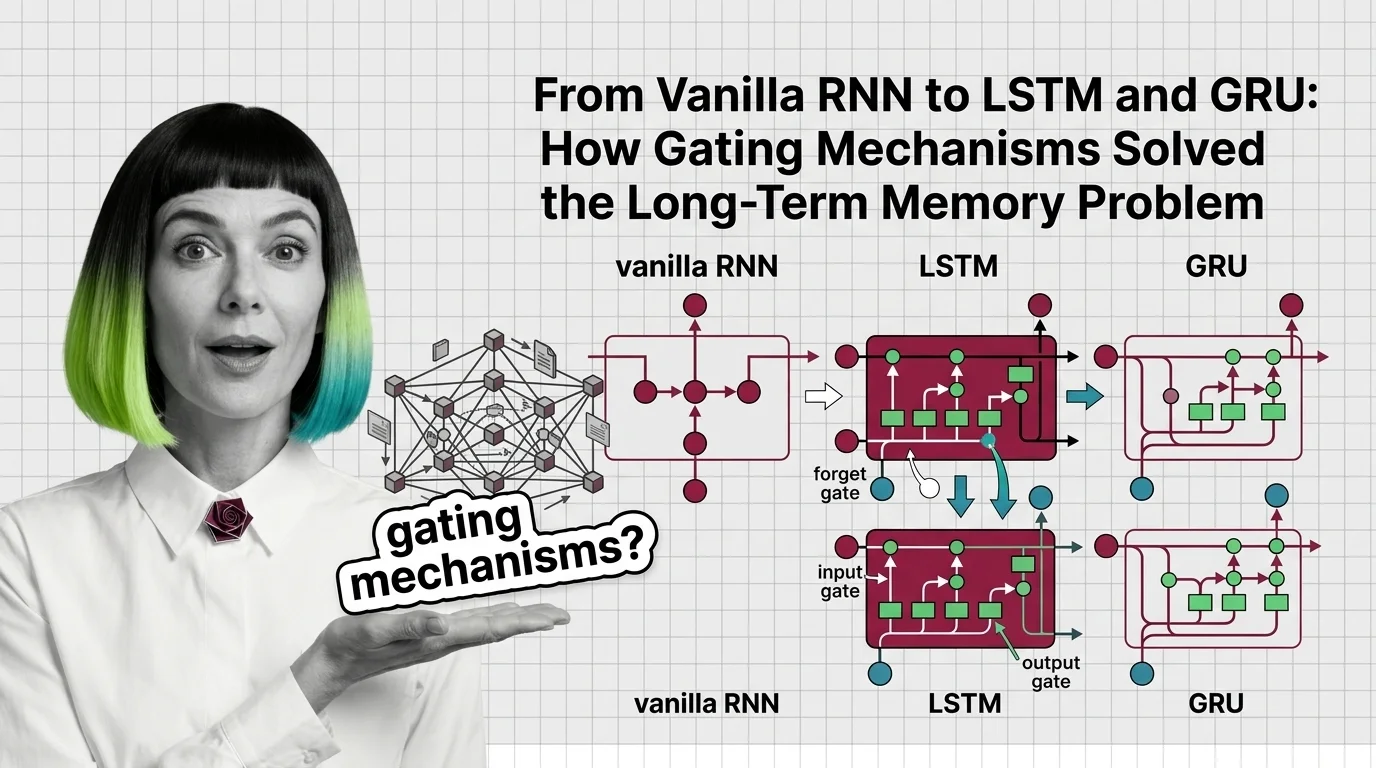
Trace how LSTM forget, input, and output gates fix the vanishing gradient problem that crippled vanilla RNNs, and how GRU simplifies the three-gate design.
Building an RNN from scratch exposes the gap between elegant equations and real engineering constraints. The practical guide covers implementation choices, training pitfalls, and where recurrent models still earn their place.
Tools & techniques
Learn when LSTMs beat transformers in 2026 — edge deployment, anomaly detection, time series — and how to specify an LSTM build for AI coding tools in PyTorch.
The line between recurrent and attention-based architectures is blurring fast. Tracking how recurrent ideas are re-entering mainstream models matters for anyone choosing an architecture today.
Models & benchmarks
Updated April 2026
xLSTM, minLSTM, and Mamba-3 prove recurrent architectures rival transformer quality at linear cost. What the hybrid architecture shift means for your inference stack.
Recurrent networks make decisions based on opaque, accumulated memory states that resist inspection. Understanding sequential bias and hidden-state opacity is essential before deploying these models in consequential settings.
Risks & metrics

RNNs carry opaque sequential memory into high-stakes decisions. Explore why hidden states resist auditing and what that means for accountability in AI systems.