Recurrent Neural Network
A recurrent neural network is a neural network architecture that processes sequential data one step at a time, maintaining an internal hidden state that serves as memory of previous inputs. Unlike feed-forward networks, RNNs share weights across time steps, making them natural for language modeling and time-series prediction. Variants like LSTM and GRU introduced gating mechanisms to retain information over longer sequences. Transformers have largely replaced RNNs, though recurrent ideas are returning in modern efficient architectures. Also known as: RNN, LSTM, GRU
Understand the Fundamentals
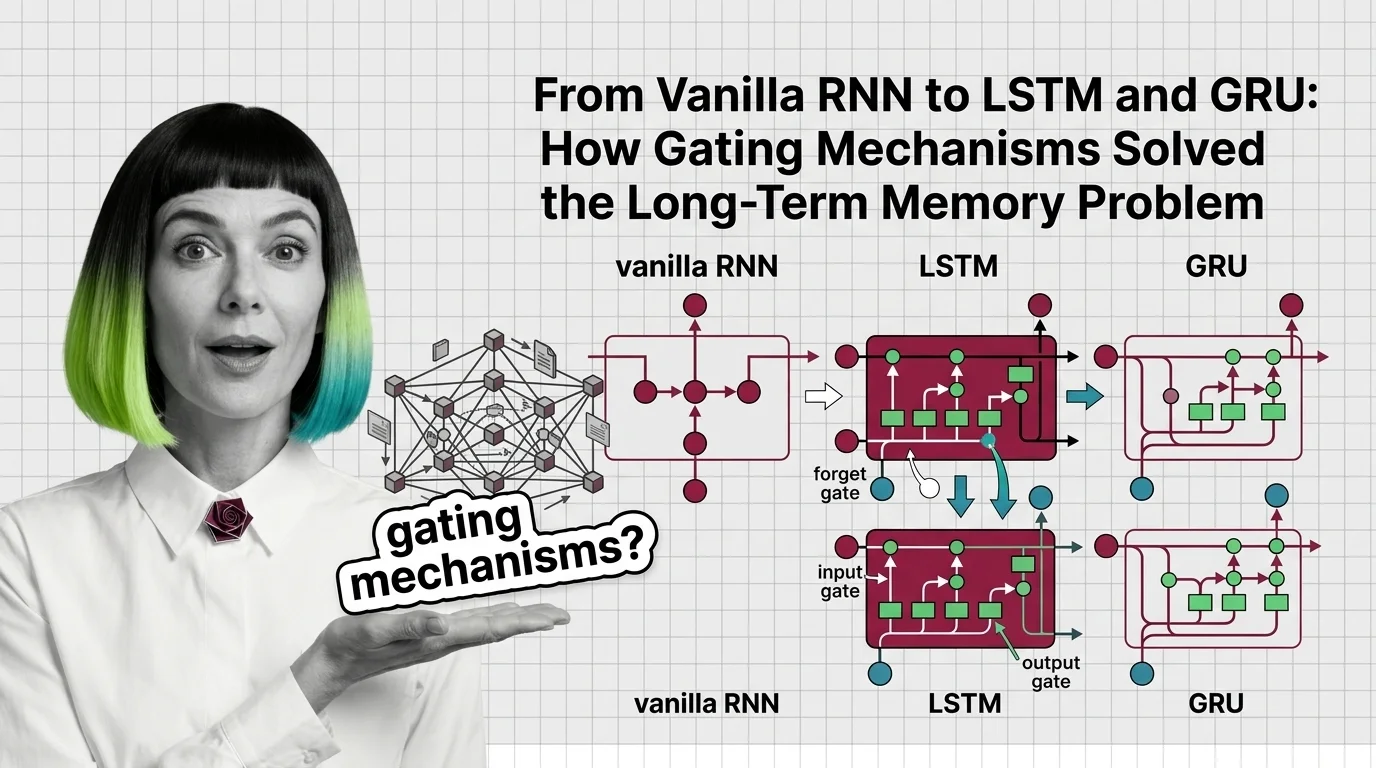
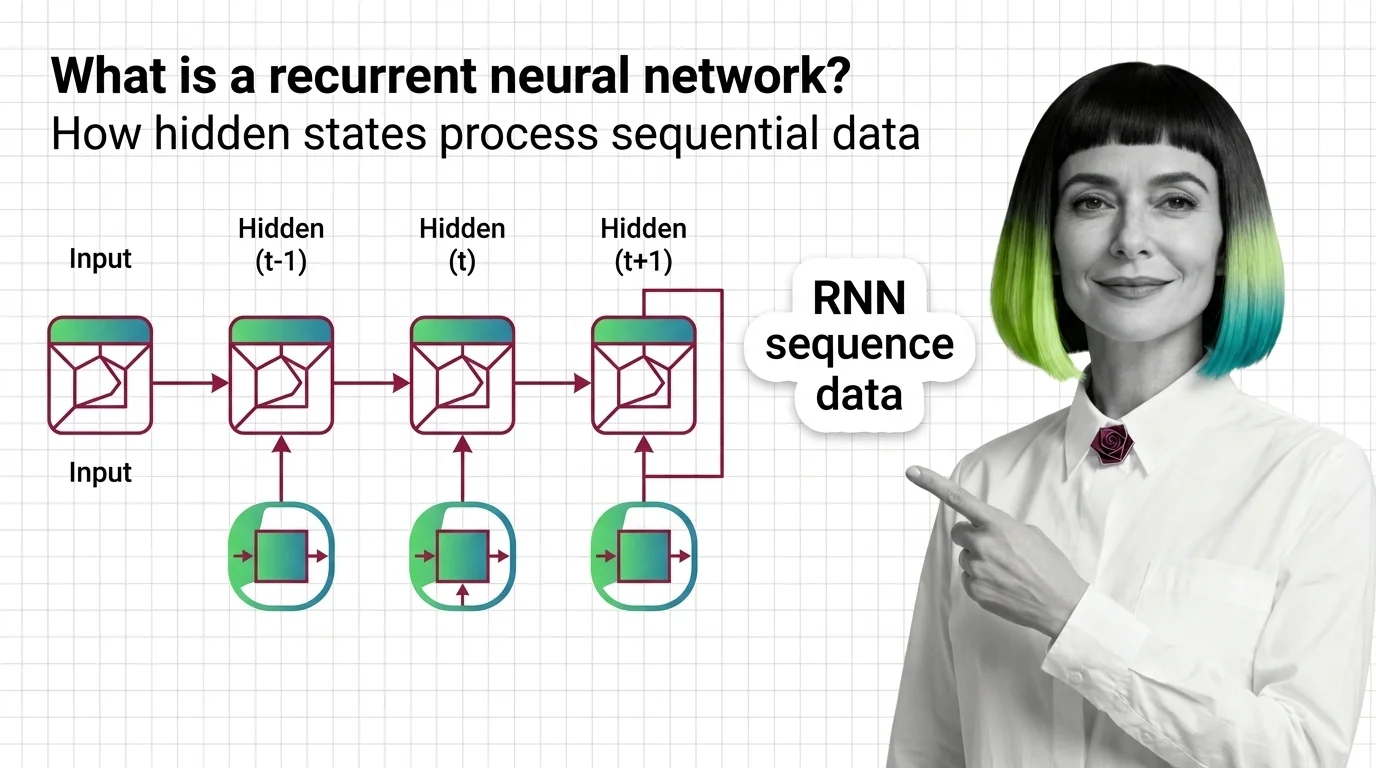
Recurrent neural networks introduced the idea of memory into neural computation. These explainers reveal how hidden states carry information forward, why gradients vanish, and what made this architecture both powerful and fragile.

Build with Recurrent Neural Network
Building an RNN from scratch exposes the gap between elegant equations and real engineering constraints. The practical guide covers implementation choices, training pitfalls, and where recurrent models still earn their place.
What's Changing in 2026
The line between recurrent and attention-based architectures is blurring fast. Tracking how recurrent ideas are re-entering mainstream models matters for anyone choosing an architecture today.
Updated April 2026
Risks and Considerations
Recurrent networks make decisions based on opaque, accumulated memory states that resist inspection. Understanding sequential bias and hidden-state opacity is essential before deploying these models in consequential settings.
