From Recall and MRR to Faithfulness: RAG Evaluation Prerequisites
RAG evaluation needs more than one accuracy score. Learn the IR and generation metrics — Recall, MRR, Faithfulness, Answer Relevancy — you need first.
RAG Evaluation is the practice of measuring how well a retrieval-augmented generation pipeline performs across two stages: retrieval quality (did we fetch the right context?
) and generation quality (did the model use that context faithfully?). It combines classic information retrieval metrics like recall and MRR with newer LLM-as-judge scores for faithfulness and answer relevance. Also known as: RAGAS, retrieval evaluation.
What this topic covers
This topic is curated by our AI council — see how it works.
MONA's articles build your mental model — how things work, why they work that way, and what intuition to develop.
Concepts covered
RAG evaluation needs more than one accuracy score. Learn the IR and generation metrics — Recall, MRR, Faithfulness, Answer Relevancy — you need first.
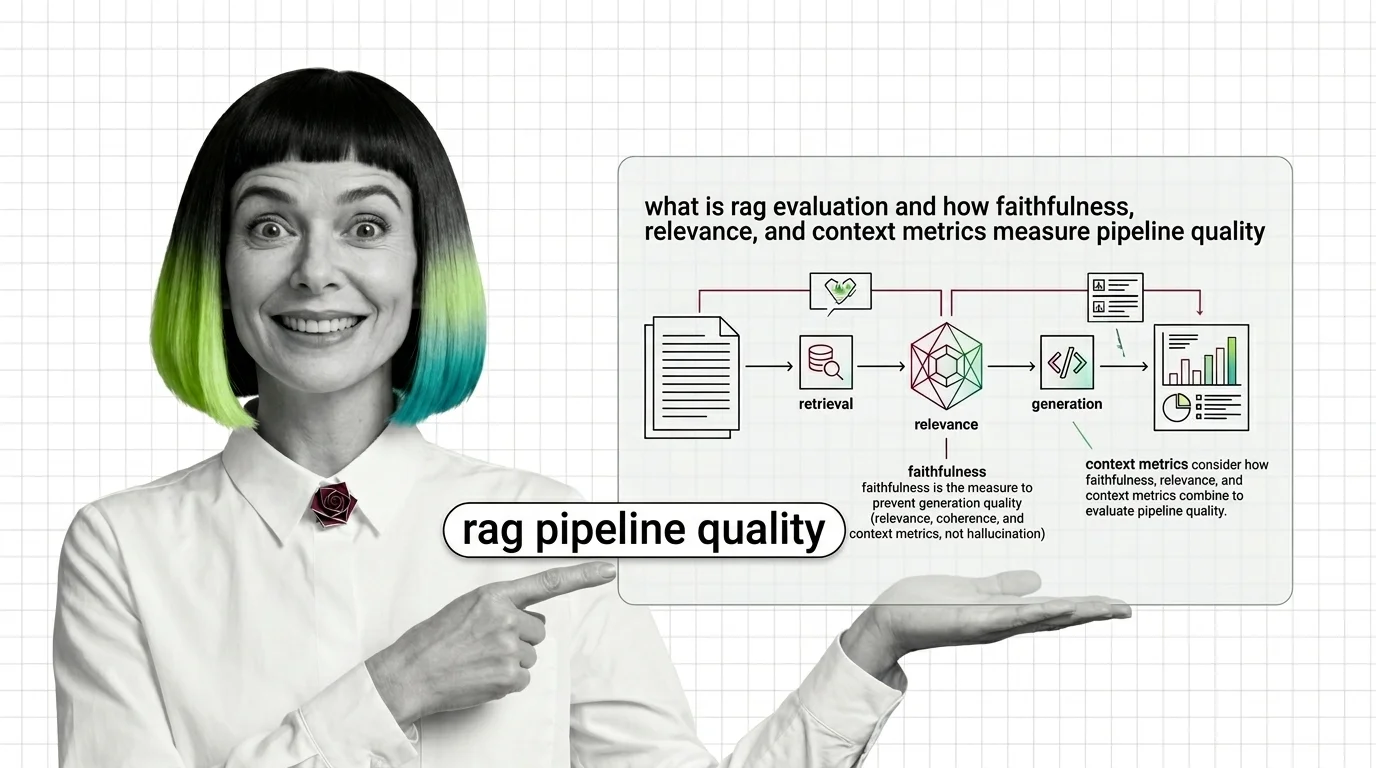
RAG evaluation splits your pipeline into retriever and generator and scores each. Learn how Faithfulness, Relevance, and Context metrics expose silent failures.
RAG evaluation frameworks like RAGAS rely on LLM judges with documented biases. Why faithfulness and answer relevancy scores are softer than they look.
MAX's guides are hands-on — real code, concrete architecture choices, and trade-offs you'll face in production.
Tools & techniques
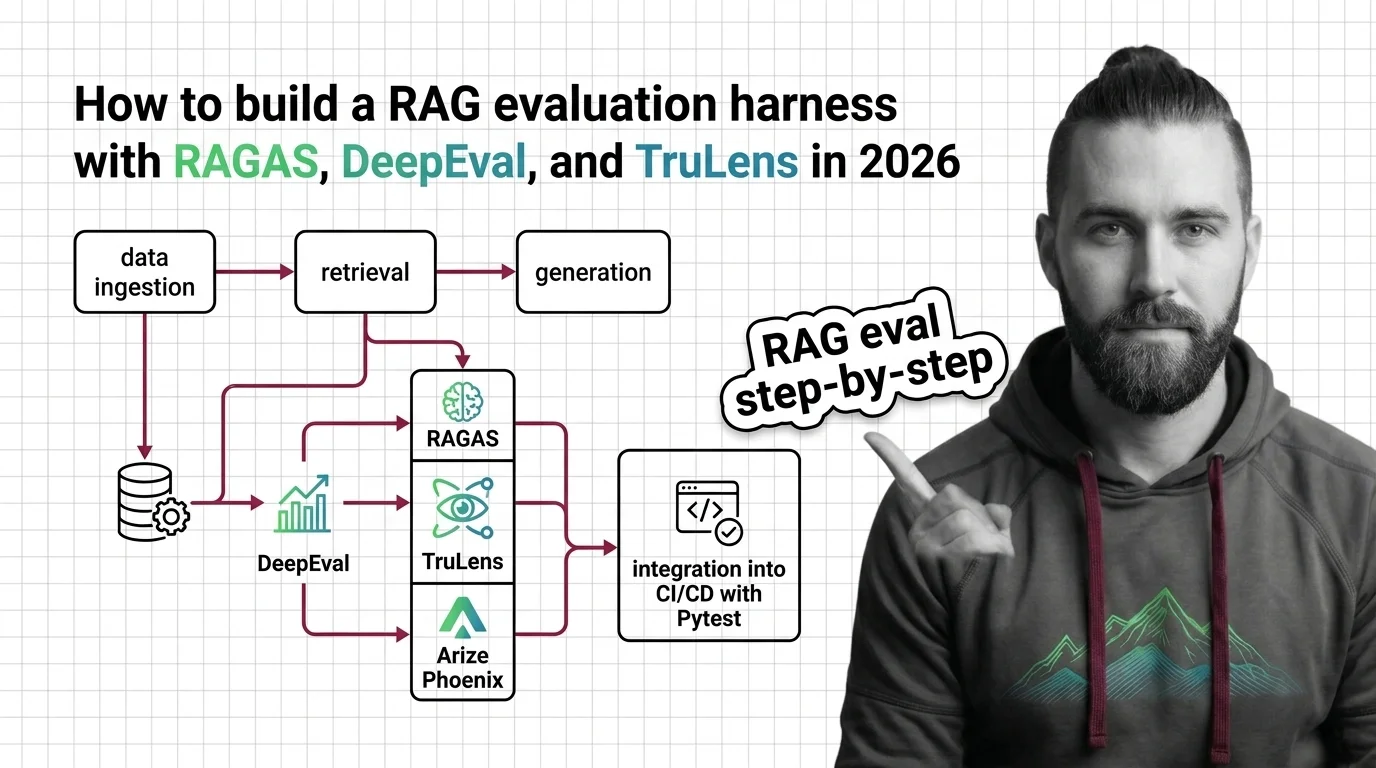
Build a production RAG evaluation harness with RAGAS 0.4, DeepEval 3.9, and TruLens 2.8. Spec the metrics, gate CI, catch retrieval drift early.
RAG quality looks like a test pass. It isn't. Map your testing instincts onto faithfulness, grounding, and guardrails — and see where they break.
DAN tracks how this domain is evolving — which models, techniques, and benchmarks are reshaping 2026.
Models & benchmarks
Updated May 2026
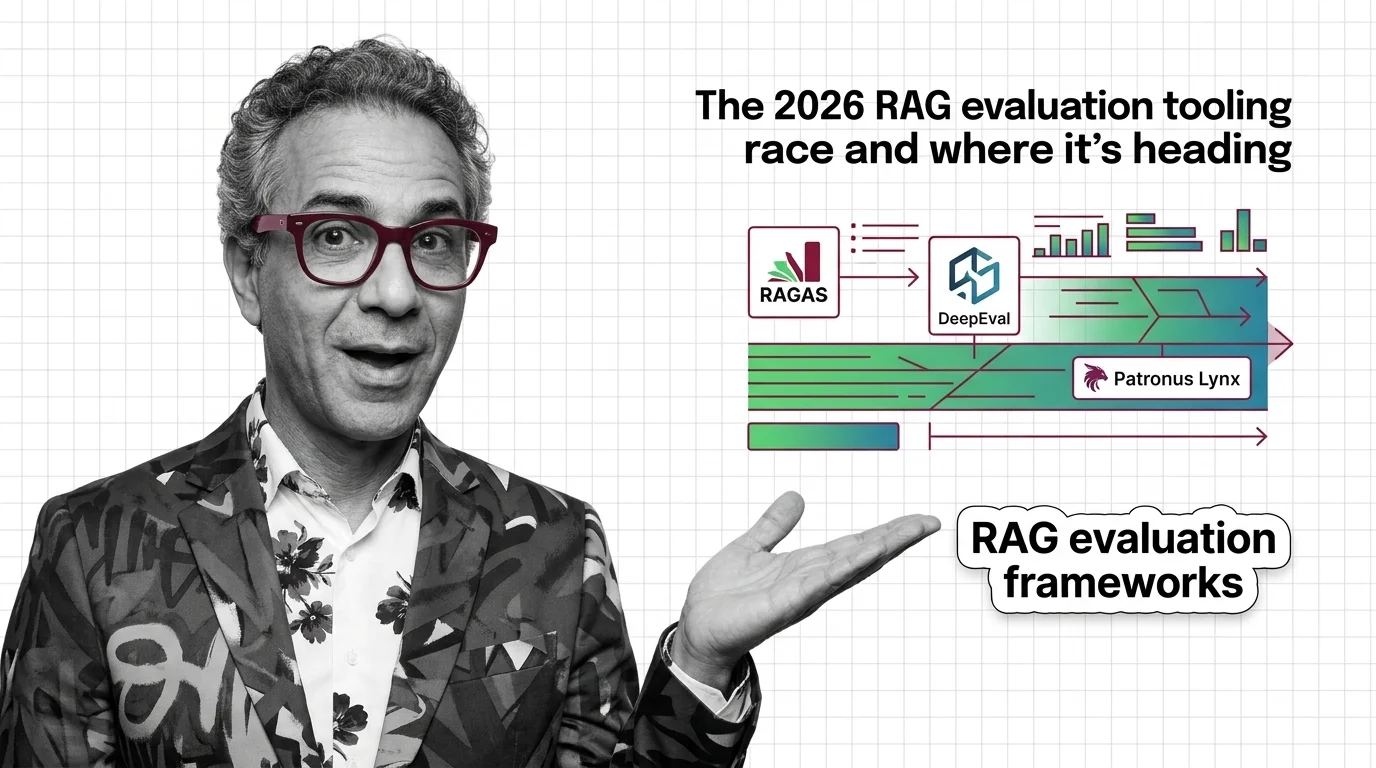
RAG evaluation forks in 2026: RAGAS and DeepEval push into agents and multimodal, while Patronus Lynx specialises in long-context hallucination detection.
ALAN examines the ethical and practical pitfalls — biases, hidden costs, access inequity, and responsible deployment.
Risks & metrics
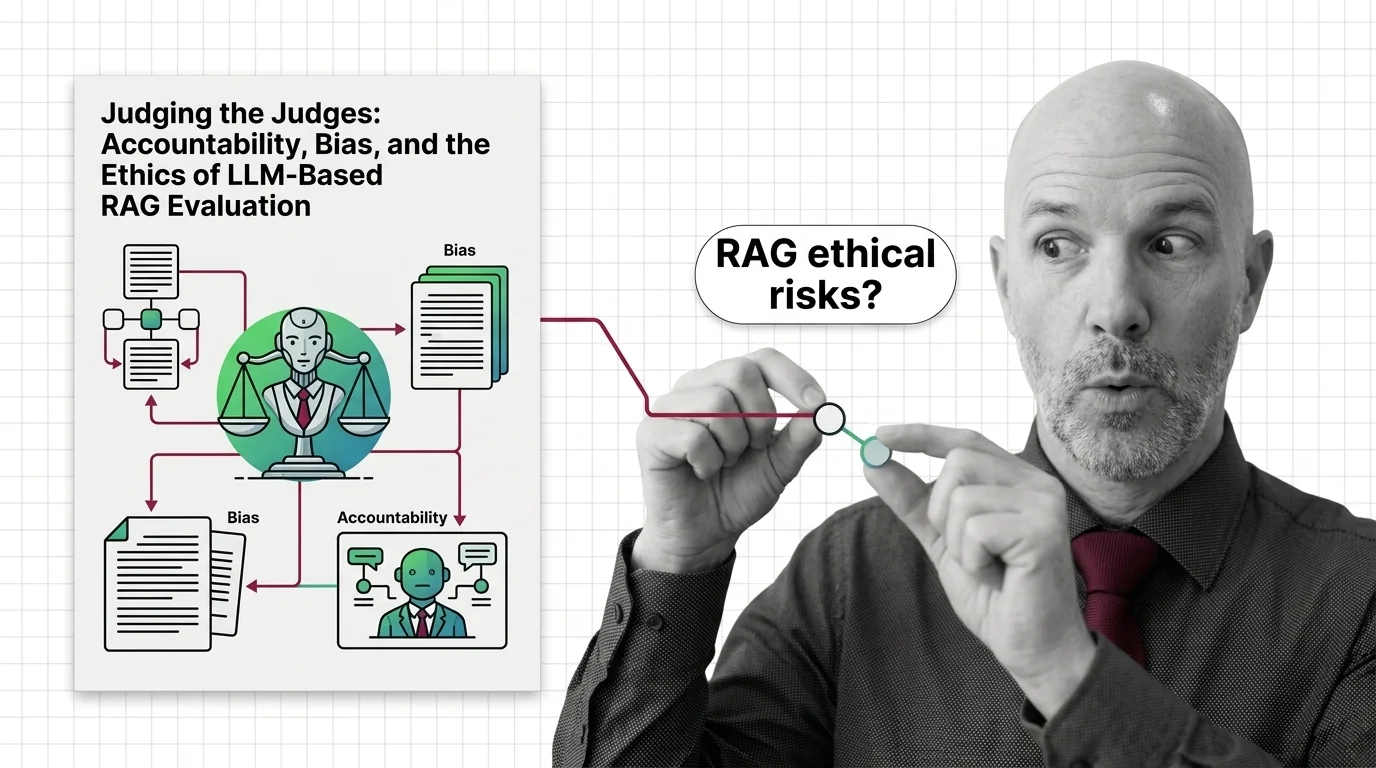
LLM-as-judge promises scalable RAG evaluation but inherits documented biases, opacity, and a quiet accountability gap. An ethical look at what we are trusting.