Quantization
Quantization is the process of reducing the numerical precision of a neural network’s weights and activations, for example converting 32-bit floating point values to 8-bit or 4-bit integers. This compression shrinks the model’s memory footprint and accelerates inference, making it possible to run large language models on consumer-grade GPUs and edge devices with manageable quality tradeoffs. Also known as: Model Quantization
Understand the Fundamentals
Quantization trades numerical precision for efficiency, but the relationship between bit-width and model capability is far from linear. These explainers unpack where the math breaks and why some tasks degrade before others.

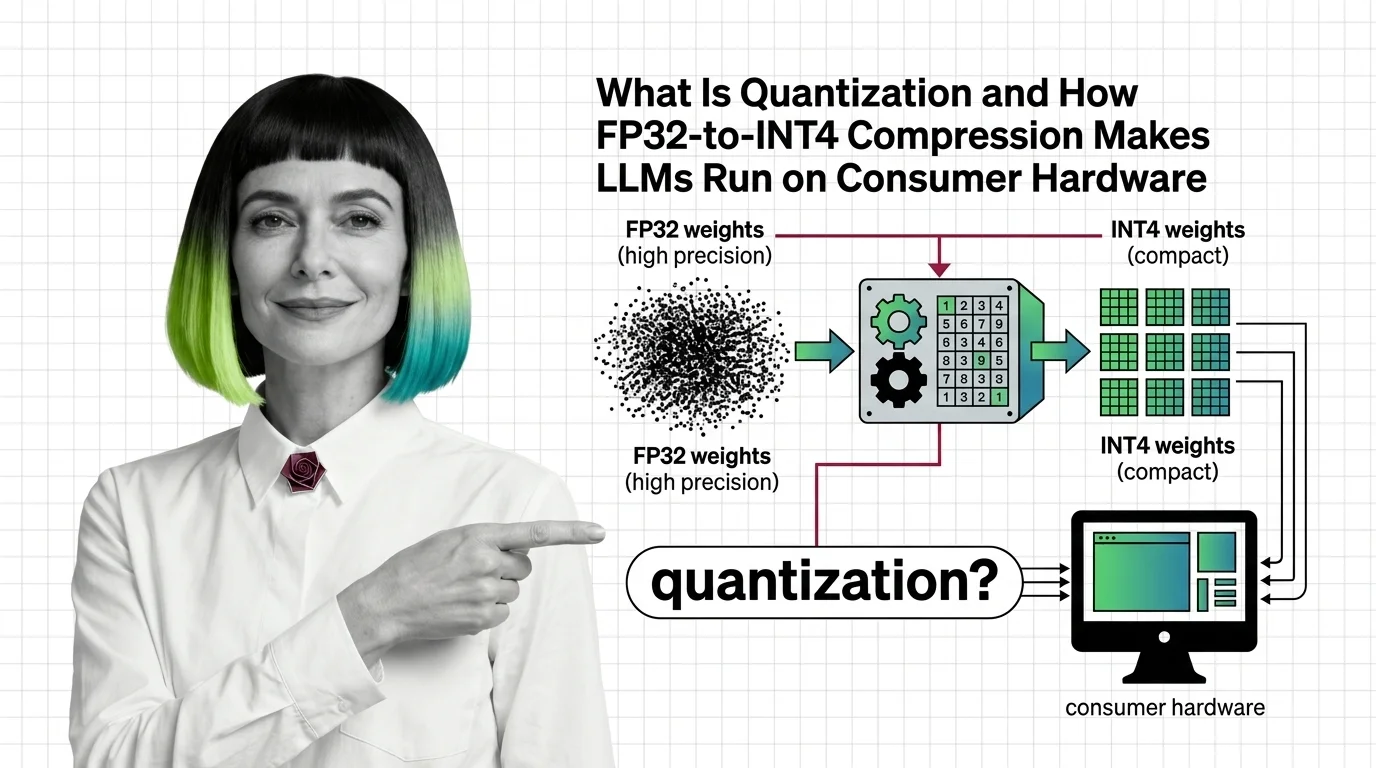
Build with Quantization
Deploying a quantized model means choosing between competing formats, calibration strategies, and hardware targets. These guides walk through real deployment pipelines and the engineering tradeoffs at each decision point.
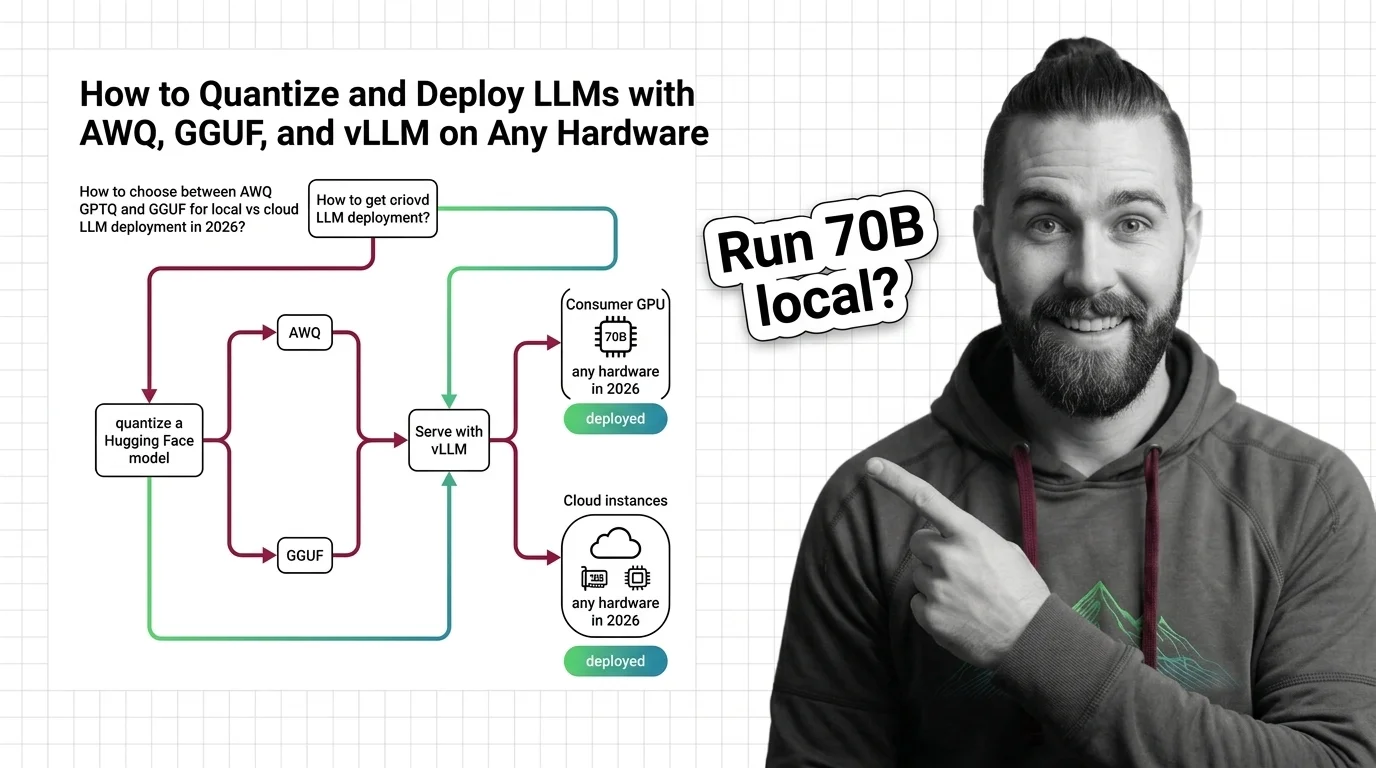
What's Changing in 2026
New quantization methods and hardware-native low-precision formats are arriving faster than most teams can evaluate them. Staying current here determines whether your deployment stack is competitive or obsolete.
Updated March 2026
Risks and Considerations
Aggressive compression can silently degrade performance on underrepresented languages, safety-critical tasks, and nuanced reasoning. These pieces examine who bears the cost when models get smaller.
