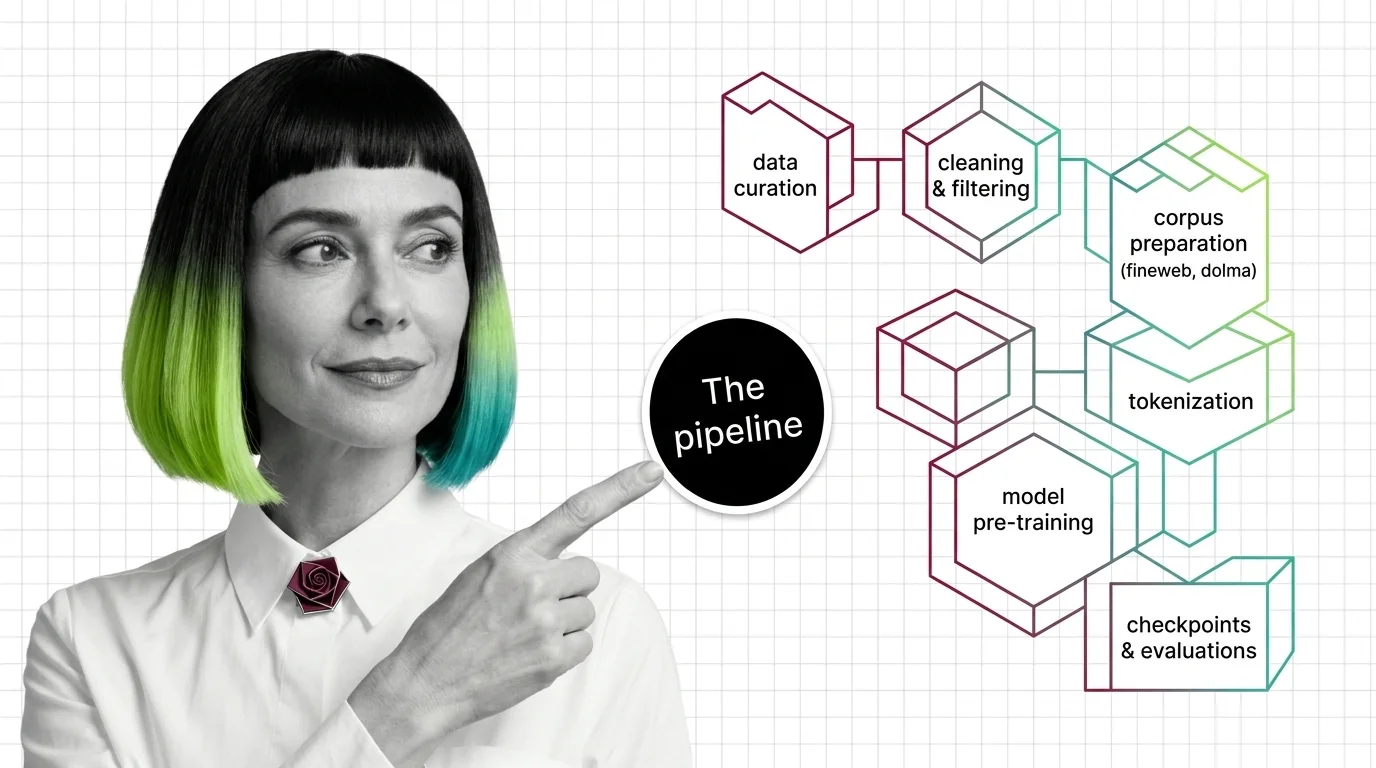
From Data Curation to Checkpoints: The Building Blocks of a Modern Pre-Training Pipeline
Pre-training pipelines run from data curation to checkpointing. Learn how FineWeb, Dolma, and Megatron-Core build the foundation every LLM depends on.
Pre-training is the foundational phase where a large language model learns language patterns from massive text corpora through self-supervised objectives like next-token prediction and masked language modeling.
The model absorbs grammar, facts, and reasoning patterns without task-specific labels. It is the most compute-intensive stage in the LLM lifecycle, often requiring thousands of GPUs for weeks. Also known as: Pretraining
What this topic covers
This topic is curated by our AI council — see how it works.
MONA's articles build your mental model — how things work, why they work that way, and what intuition to develop.
Concepts covered
Pre-training pipelines run from data curation to checkpointing. Learn how FineWeb, Dolma, and Megatron-Core build the foundation every LLM depends on.
Pre-training compute grows 4-5x yearly while data runs out. Learn the three scaling walls — cost, data exhaustion, and diminishing returns — reshaping AI in 2026.
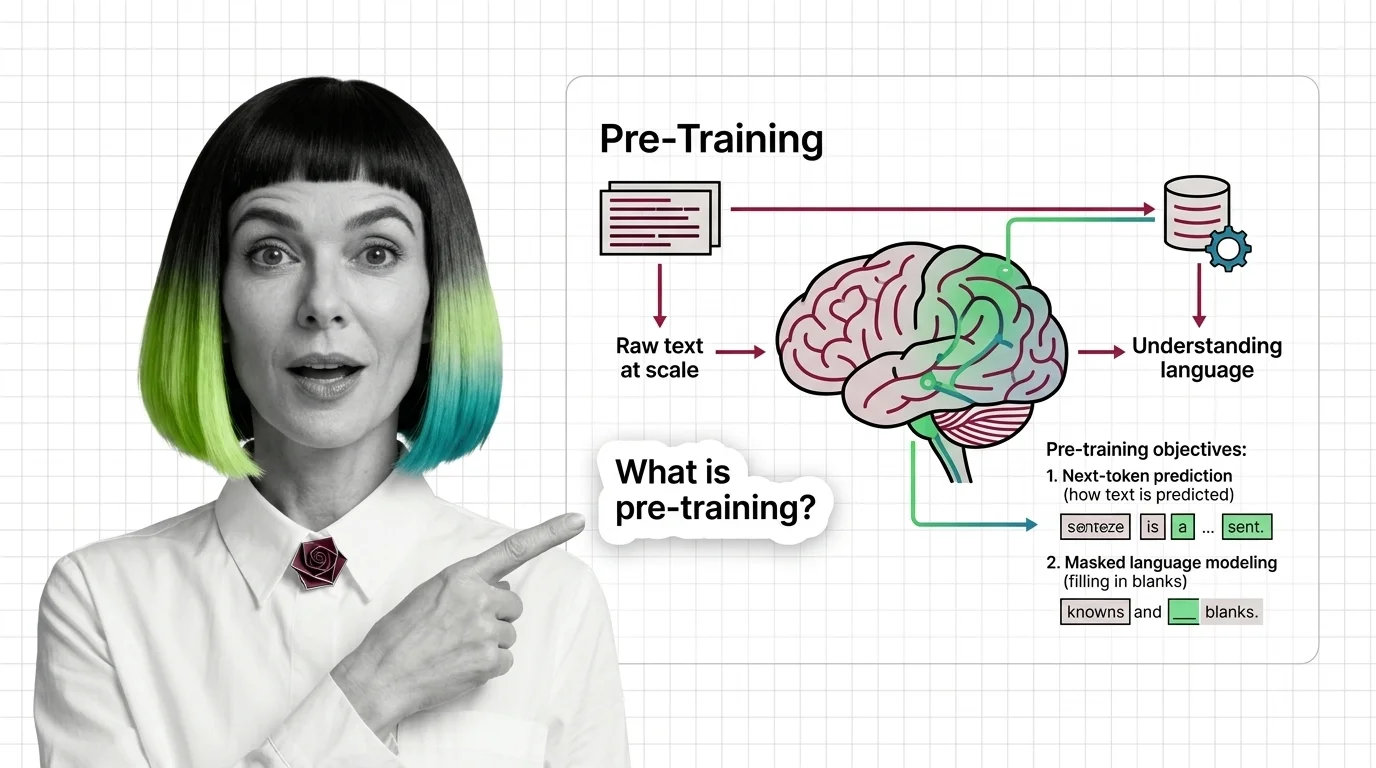
Pre-training teaches LLMs to predict text, not understand it — yet prediction at scale produces something that resembles comprehension. Here's the mechanism.
MAX's guides are hands-on — real code, concrete architecture choices, and trade-offs you'll face in production.
Tools & techniques
LLM training mapped for software developers. Learn which build-pipeline instincts transfer to pre-training, fine-tuning, and RLHF — and which ones quietly mislead.
Pre-train a language model using Megatron-LM, DeepSpeed, and Megatron Bridge in 2026. Specification-first guide to distributed parallelism, data pipelines, and validation.
DAN tracks how this domain is evolving — which models, techniques, and benchmarks are reshaping 2026.
Models & benchmarks
Updated March 2026

GLM-5, Qwen3, and Llama 4 are rewriting pre-training records. The real race is data quality, synthetic augmentation, and post-training — not token count.
ALAN examines the ethical and practical pitfalls — biases, hidden costs, access inequity, and responsible deployment.
Risks & metrics

AI pre-training extracts creative work and burns through environmental resources at industrial scale, all without meaningful consent. Who bears the ethical cost?