Pre-Training
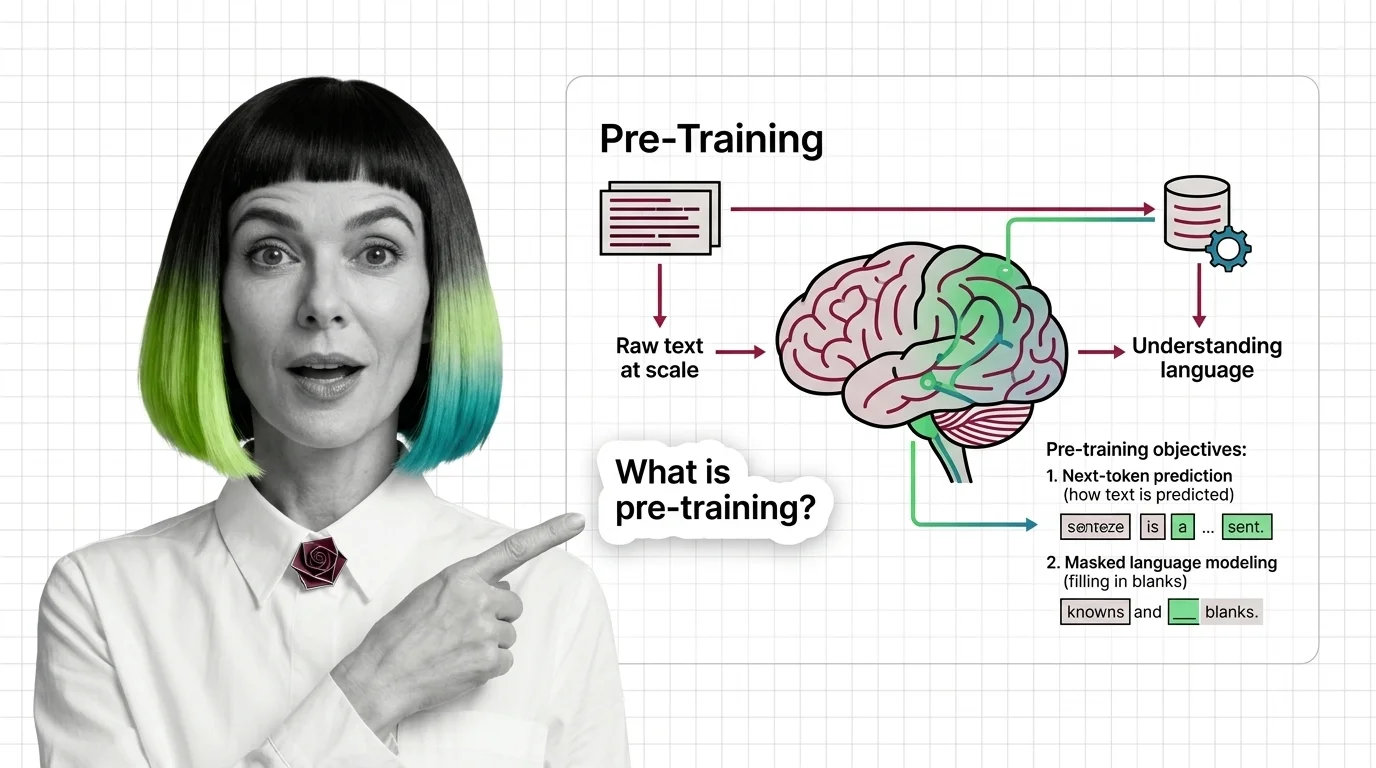
Pre-training is the foundational phase where a large language model learns language patterns from massive text corpora through self-supervised objectives like next-token prediction and masked language modeling. The model absorbs grammar, facts, and reasoning patterns without task-specific labels. It is the most compute-intensive stage in the LLM lifecycle, often requiring thousands of GPUs for weeks. Also known as: Pretraining
Understand the Fundamentals
Pre-training is where models acquire their foundational knowledge from raw text. Understanding this phase reveals why certain capabilities emerge and why others remain stubbornly out of reach.
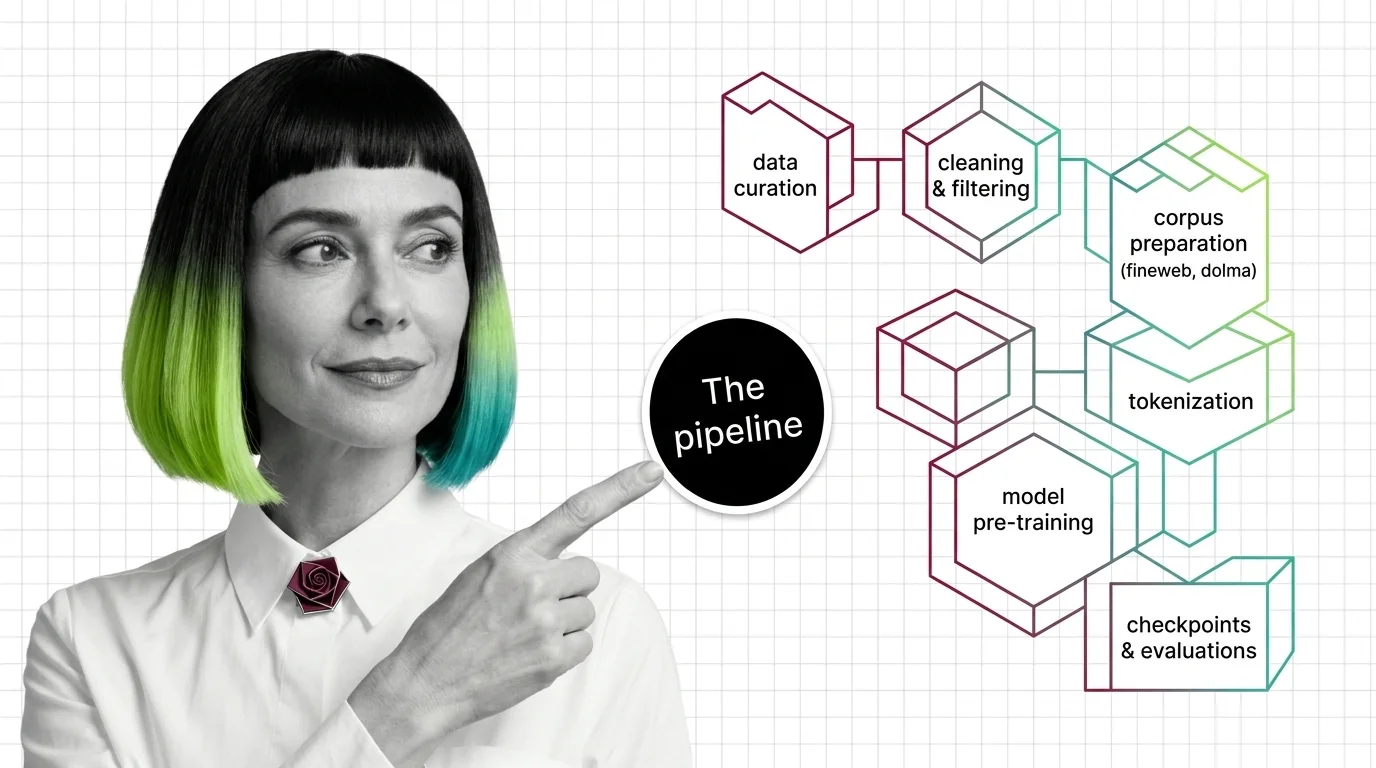
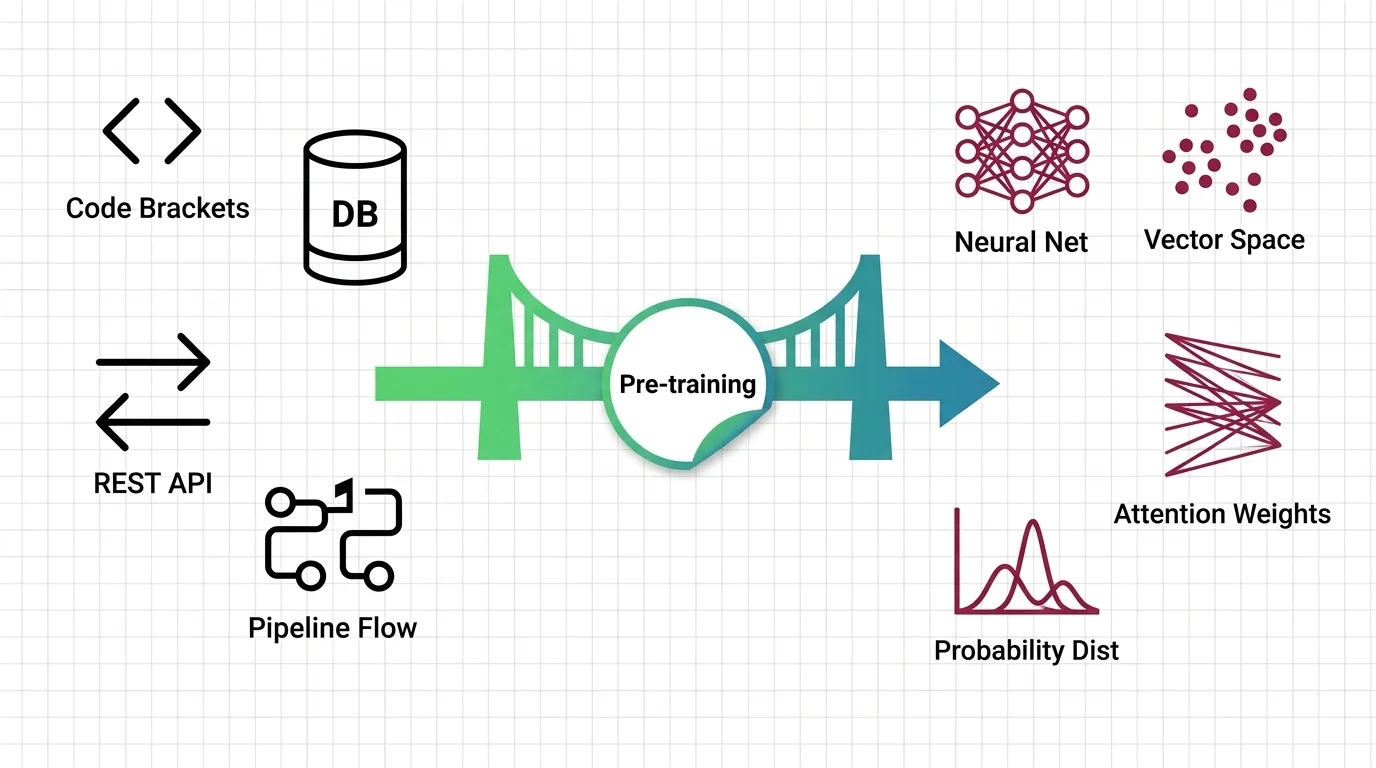
Build with Pre-Training
The practical guides cover data curation pipelines, distributed training setups, and checkpoint management — the engineering decisions that determine whether a pre-training run succeeds or wastes compute.
What's Changing in 2026
Pre-training strategies are evolving rapidly as labs confront data scarcity and push architectural boundaries. Staying current here means understanding where the next generation of models will come from.
Updated March 2026

Risks and Considerations
Training on web-scale data raises serious questions about copyright, consent, and environmental cost. Pre-training decisions made today shape what biases and limitations downstream applications inherit.
