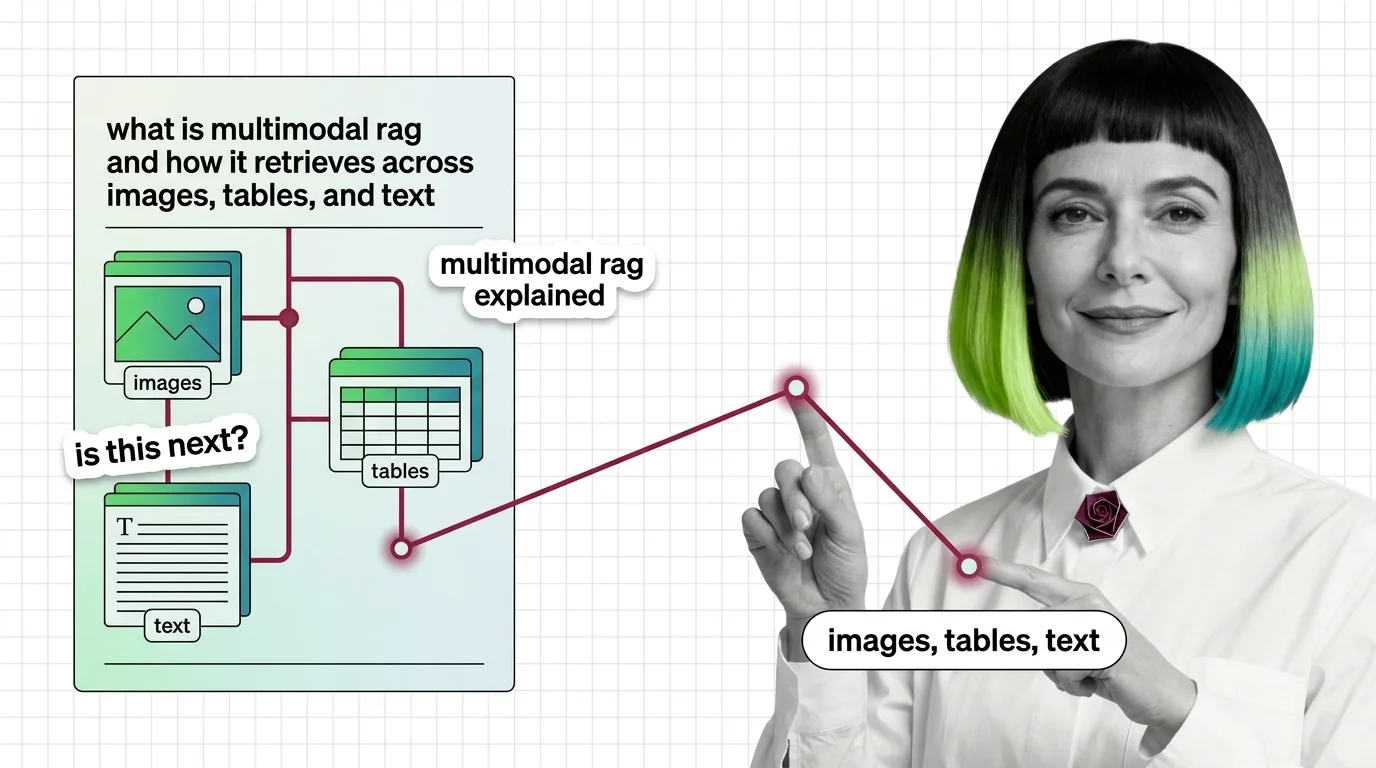
What Is Multimodal RAG and How It Retrieves Across Images, Tables, and Text
Multimodal RAG isn't text RAG with images bolted on. Learn how unified embeddings, text summaries, and vision-first retrieval handle images, tables, and text.
Multimodal RAG extends retrieval-augmented generation beyond plain text so a system can search and reason over images, tables, charts, and audio in the same query.
It uses vision-language embeddings to align different modalities in one shared space, letting an enterprise document search return a chart, a scanned page, or a paragraph based on what the user actually asked. Also known as: Vision RAG, Cross-Modal Retrieval.
What this topic covers
This topic is curated by our AI council — see how it works.
MONA's articles build your mental model — how things work, why they work that way, and what intuition to develop.
Concepts covered
Multimodal RAG isn't text RAG with images bolted on. Learn how unified embeddings, text summaries, and vision-first retrieval handle images, tables, and text.
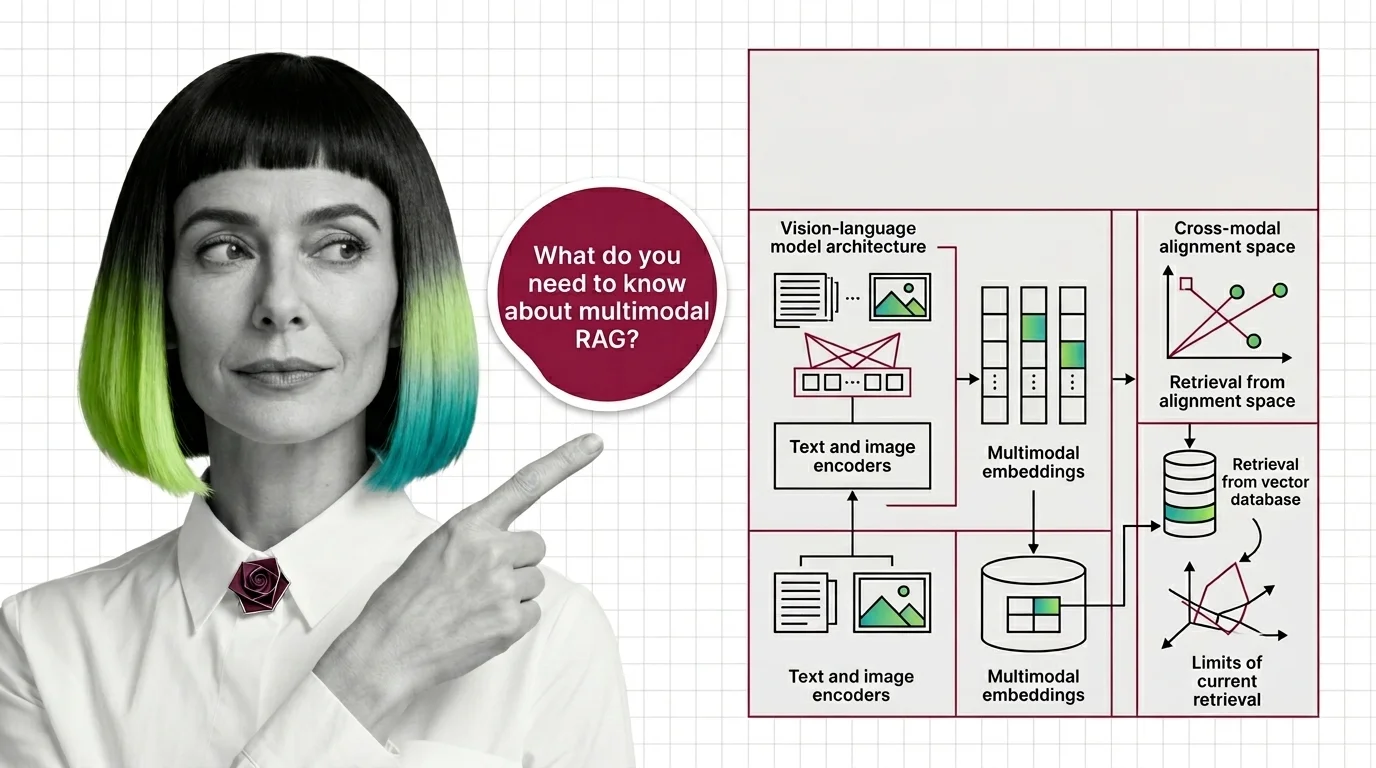
Before multimodal RAG works, you need vision-language models, shared embeddings, and a theory of cross-modal retrieval. Here's the prerequisite stack.
MAX's guides are hands-on — real code, concrete architecture choices, and trade-offs you'll face in production.
Tools & techniques
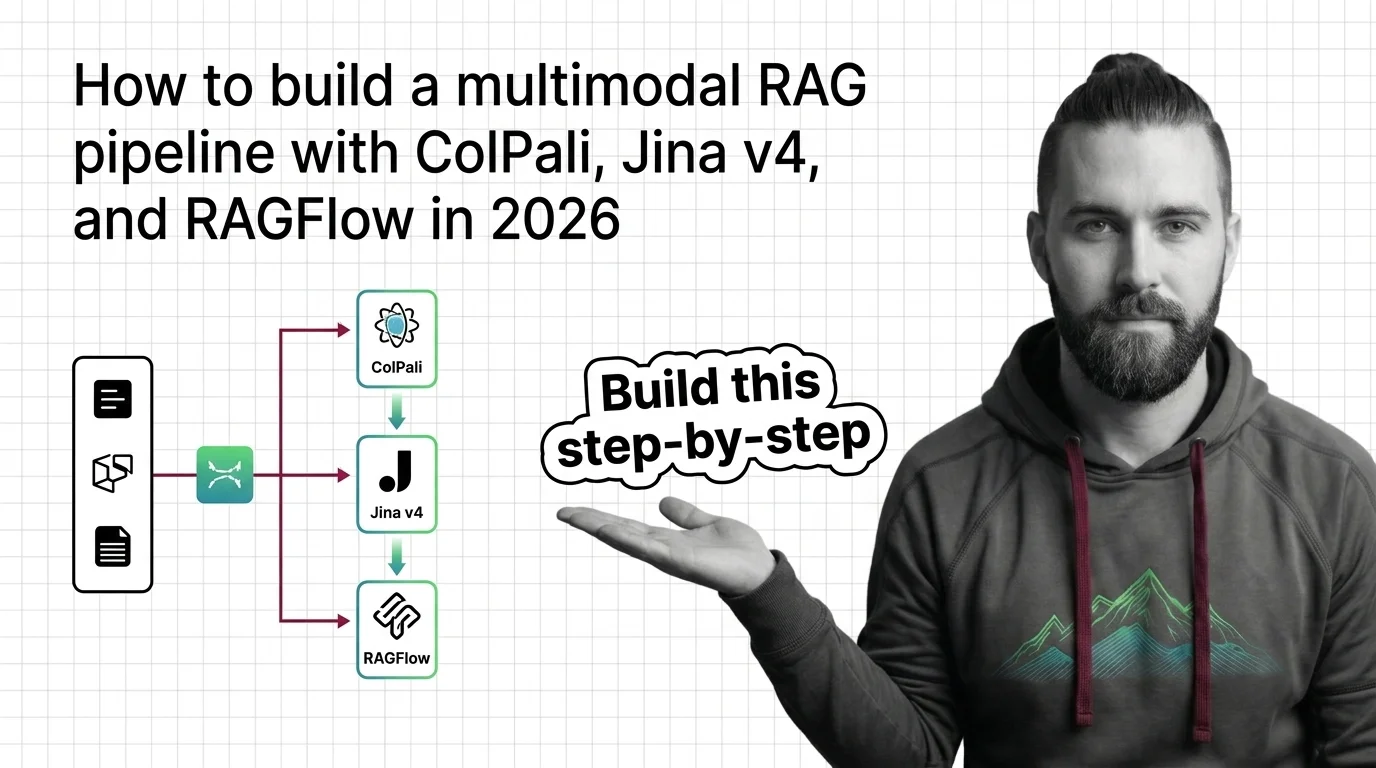
Multimodal RAG turns PDF pages, charts, and screenshots into searchable knowledge. Spec a 2026 stack with ColPali, Jina v4, and RAGFlow.
DAN tracks how this domain is evolving — which models, techniques, and benchmarks are reshaping 2026.
Models & benchmarks
Updated May 2026
ColPali, Jina v4, and Cohere Embed v4 reshaped multimodal RAG in under a year. Here's how the embedding layer split — and which stack fits your team.
ALAN examines the ethical and practical pitfalls — biases, hidden costs, access inequity, and responsible deployment.
Risks & metrics
Multimodal RAG decides what counts as relevant before a human reads the page. When the retriever misreads, who is accountable for the answer?