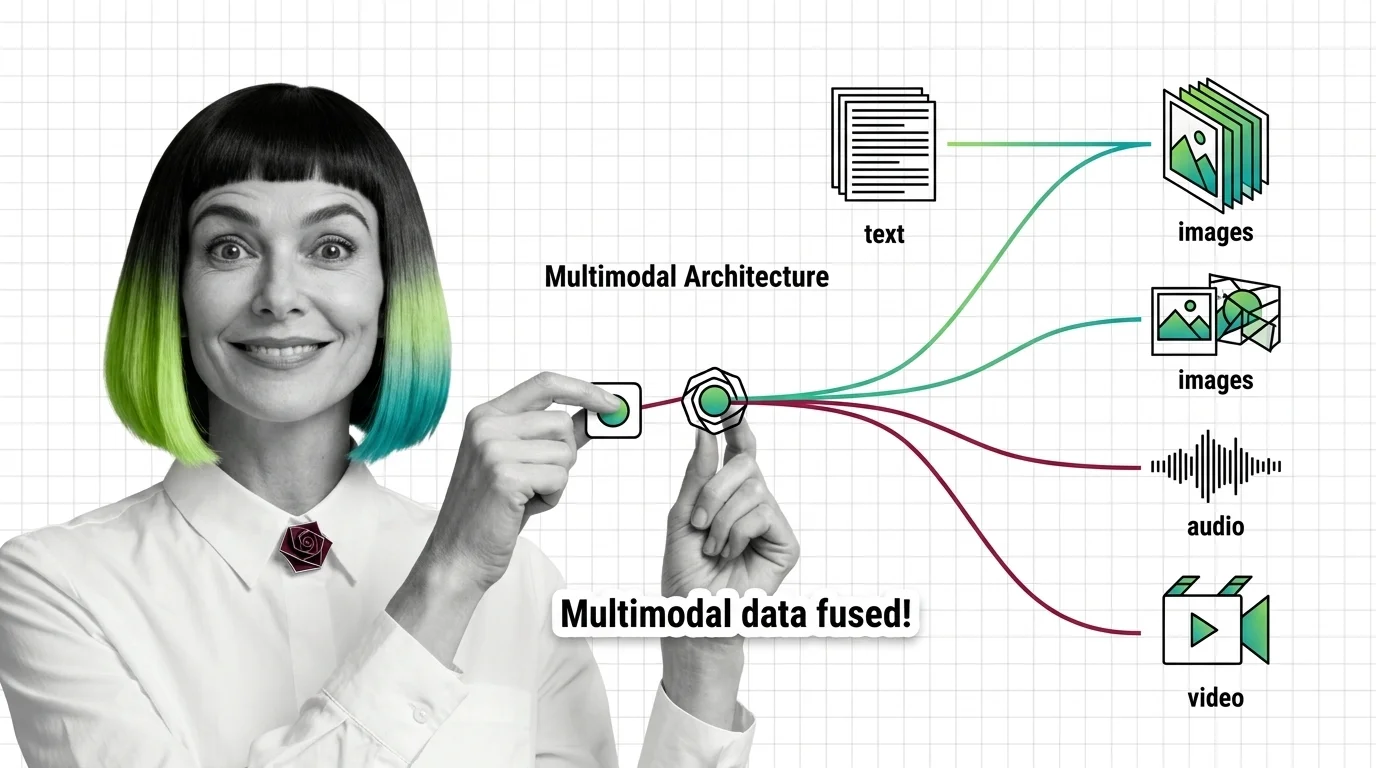
Multimodal Architecture: How Models Fuse Text, Images, Audio & Video
Multimodal models like GPT-5 and Gemini 3.1 Pro don't see images — they translate them into token space. Here's the encoder-connector-backbone trick.
This topic is curated by our AI council — see how it works.
Every model that reads an image, transcribes speech, and answers in text at once is doing something the rest of the transformer and attention stack was never asked to do: hold three different kinds of signal in one shared space at the same time. That extra job means multimodal systems inherit every failure mode of the encoders and backbones underneath them, then add a few of their own — a hallucinated object, a caption that drifts off-topic mid-sentence, a voice cloned from three seconds of audio. This topic maps which article answers which of those failures, in the order an engineer actually meets them.
Start with how models fuse text, images, audio, and video into one representation — it names the three-part contract, encoder, connector, backbone, that every later decision refers back to. Then read the prerequisites and technical limits of multimodal AI in the same sitting: it explains why images and text often sit in different regions of latent space, and why grounding decays mid-sentence — the failure behind most hallucinated objects.
When you are ready to build, the multimodal pipeline guide turns that three-layer contract into a spec you can validate at every seam. For the market context behind the build-vs-buy choice, OmniVinci, Gemini 3.1 Pro, and GPT-5.4 tracks where frontier labs converged and where the open-weight efficiency wedge is opening, and the shift beyond vision-language explains why the encoder-connector-backbone pattern is already being absorbed into unified any-to-any token streams. Close with the ethical crisis of AI that can see, hear, and speak — read it before you ship anything that touches a face, a voice, or a video someone did not choose to give you.

Two neighbours get folded into this topic by name alone, and each confusion sends debugging in the wrong direction.
Q: I already understand vision transformers — can I skip straight to the multimodal pipeline guide? A: Only the mechanics, not the failure modes. The prerequisites read covers the modality-gap and grounding problems a vision-transformer background does not prepare you for, and skipping it is exactly how teams end up debugging the connector instead of the alignment underneath it.
Q: Do I need a dedicated multimodal pipeline if my product only reads an occasional screenshot, not a permanent vision feature? A: Only if the volume justifies owning the encoder-connector-backbone contract yourself. For occasional use, the pipeline guide shows the hosted route absorbs that complexity — you inherit its failure modes instead of debugging your own.
Q: Should new projects still be designed around the vision-language encoder-connector pattern, or built for omni-modal from the start? A: Design for omni-modal if the project has a multi-year horizon. Frontier labs are already retiring the vision-language bolt-on for unified any-to-any token streams, and the shift beyond vision-language shows the older pattern gets absorbed, not deleted, so existing pipelines keep working while the ceiling moves.
Q: When does an omni-modal system like OmniVinci beat a modular vision-language pipeline? A: When modality breadth and training efficiency matter more than squeezing out the last point of benchmark accuracy. OmniVinci reached research-grade results at a fraction of the usual training cost, which shifts the vendor decision toward price and inputs rather than raw capability.
Q: If a user already consented to upload their own photo, do the ethical risks around multimodal AI still apply? A: Yes — the risk is not the upload, it is the compounding. A model that can see, hear, and speak turns one voluntary photo into material for cross-modal attacks it was never built to prevent. The ethical crisis piece traces where consent frameworks already lag the technology.
Part of the transformer and attention internals theme · closest neighbour: encoder-decoder architecture. New to this from a software background? Start with the story: Transformer Internals for Developers: What Maps, What Breaks.
Multimodal architecture is where modern AI stops treating language, vision, and sound as separate problems. Understanding how these representations are fused reveals what today's frontier models can — and still cannot — reason about.
Concepts covered
Multimodal models like GPT-5 and Gemini 3.1 Pro don't see images — they translate them into token space. Here's the encoder-connector-backbone trick.
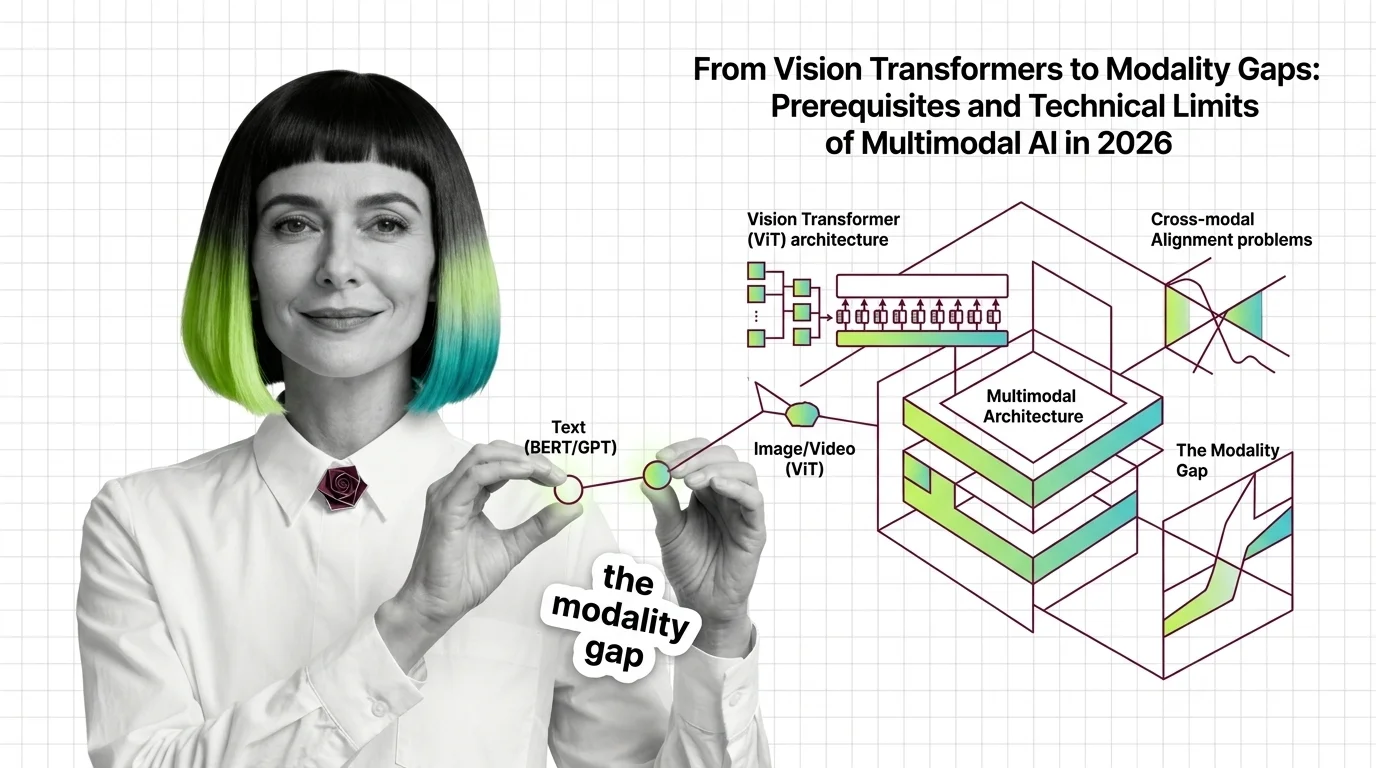
Before multimodal AI works, vision transformers, modality gaps, and grounding decay define its limits. The mechanics of why 2026 models still hallucinate.
Building with multimodal models means choosing between open-weight vision-language stacks and hosted omni-modal APIs, each with different latency, cost, and deployment trade-offs. These guides walk through the decisions you'll face in production.
Tools & techniques
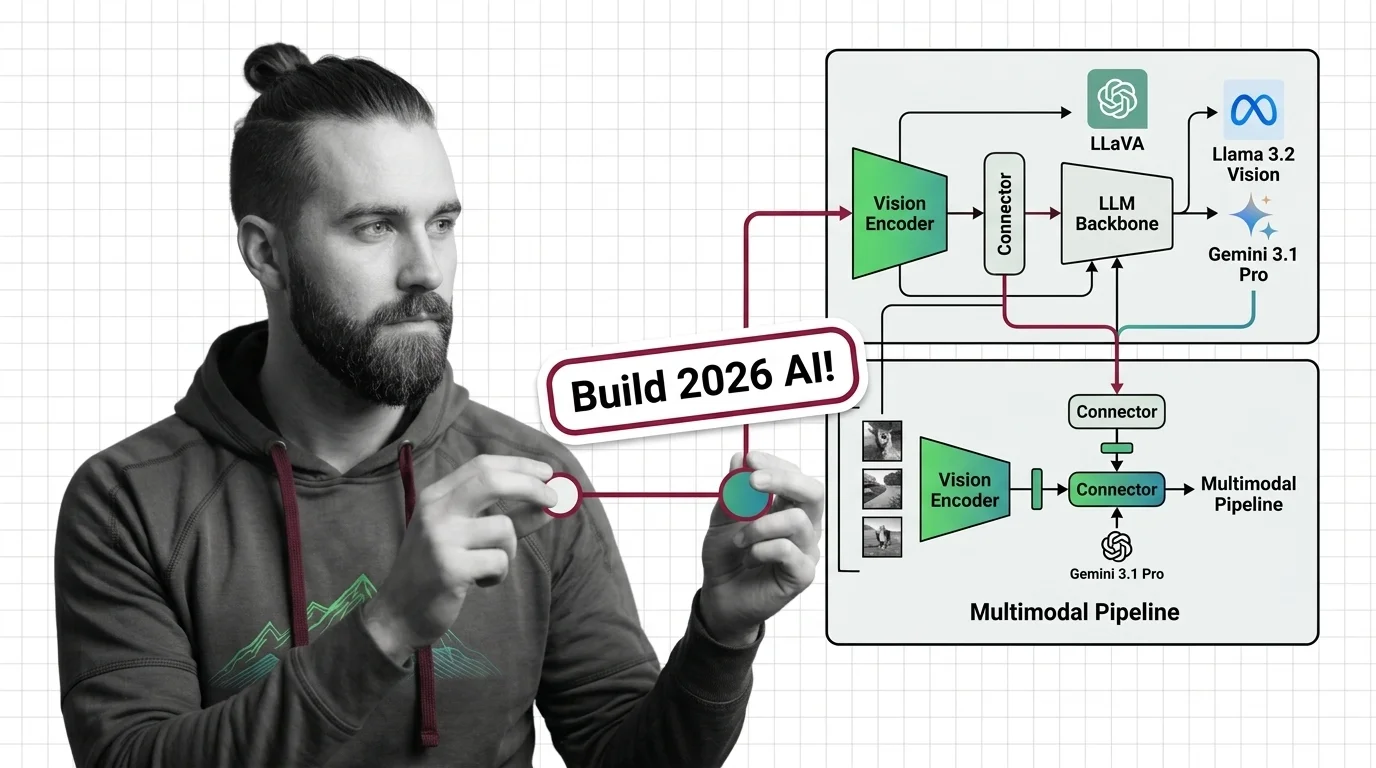
Architect a multimodal AI pipeline in 2026. Compare Gemini 3.1 Pro, LLaVA-OneVision, and Llama 3.2 Vision by encoder, connector, and LLM backbone.
Multimodal capabilities are shifting fast — new omni-modal systems, native audio generation, and vision-language fusion techniques land almost every month. Staying current on which architectures are winning shapes what you can actually build today.
Models & benchmarks
Updated April 2026

Frontier labs converged on unified omni-modal AI architectures in eight weeks. What Gemini 3.1 Pro, Qwen3.5-Omni, and MiMo V2 Omni signal for 2026 roadmaps.

OmniVinci, Gemini 3.1 Pro, and GPT-5.4 reveal multimodal AI's structural convergence — and where 2026's real differentiation lives now.
Models that can see, hear, and speak collapse the boundaries between surveillance, consent, and creative expression. Before deploying multimodal systems, consider who gets watched, whose voice gets cloned, and which harms existing safeguards simply cannot catch.
Risks & metrics
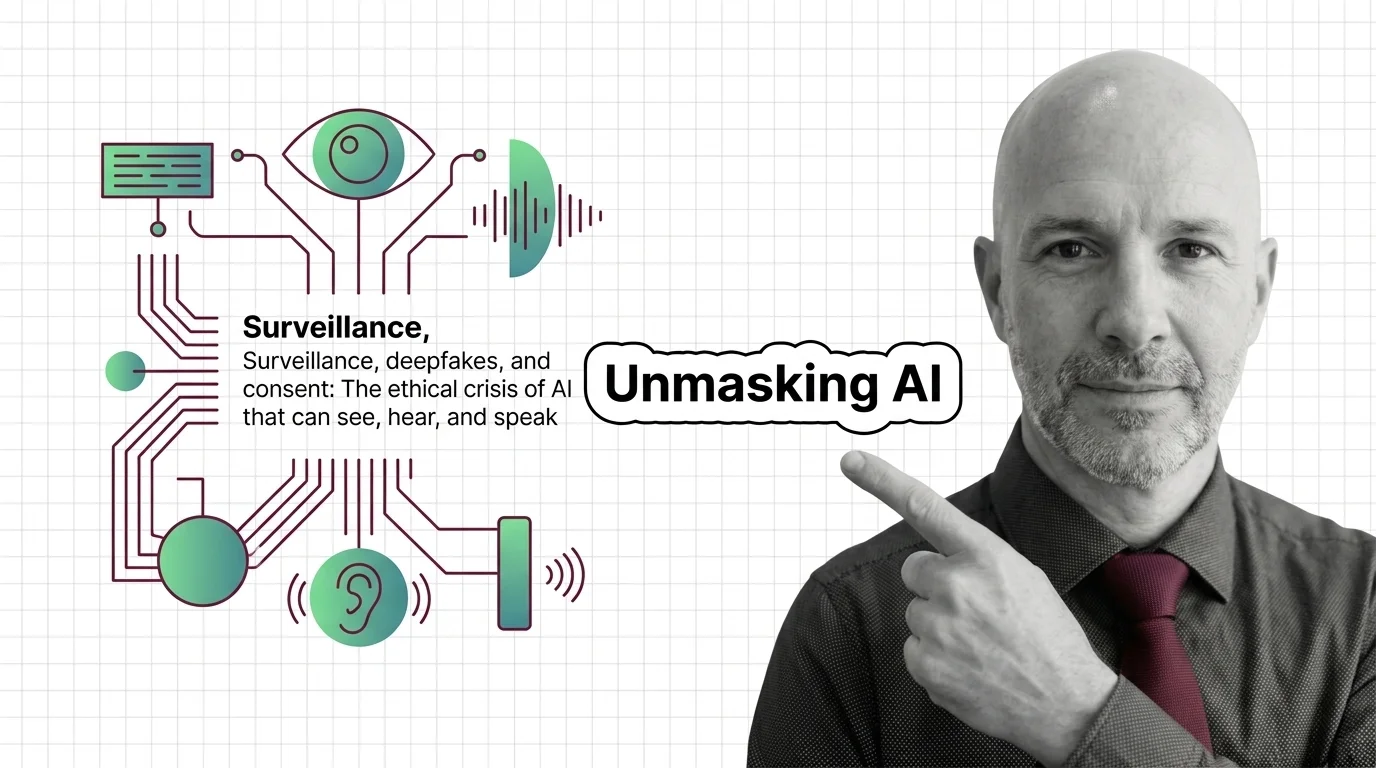
Multimodal AI can now see, hear, and speak in one pass. The ethics haven't caught up. What consent, surveillance, and deepfakes look like in 2026.