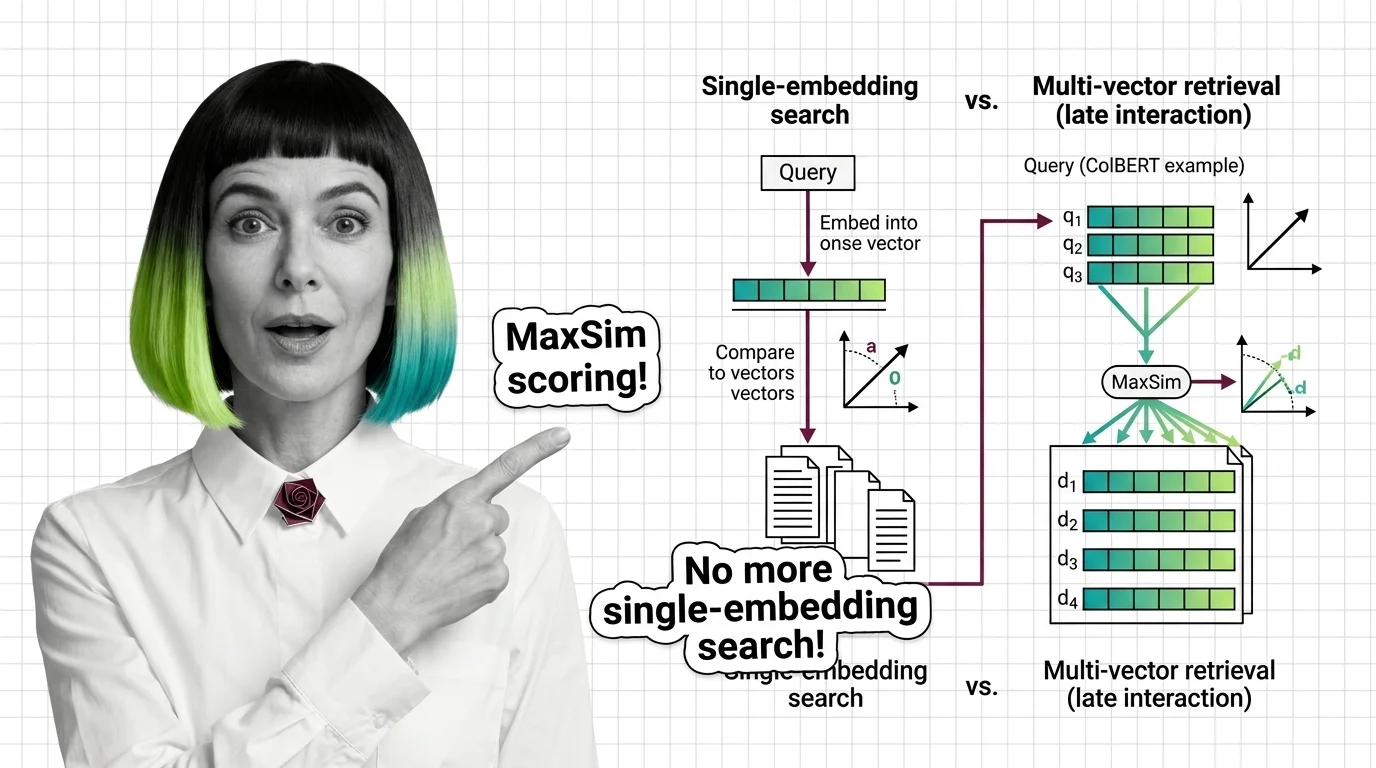
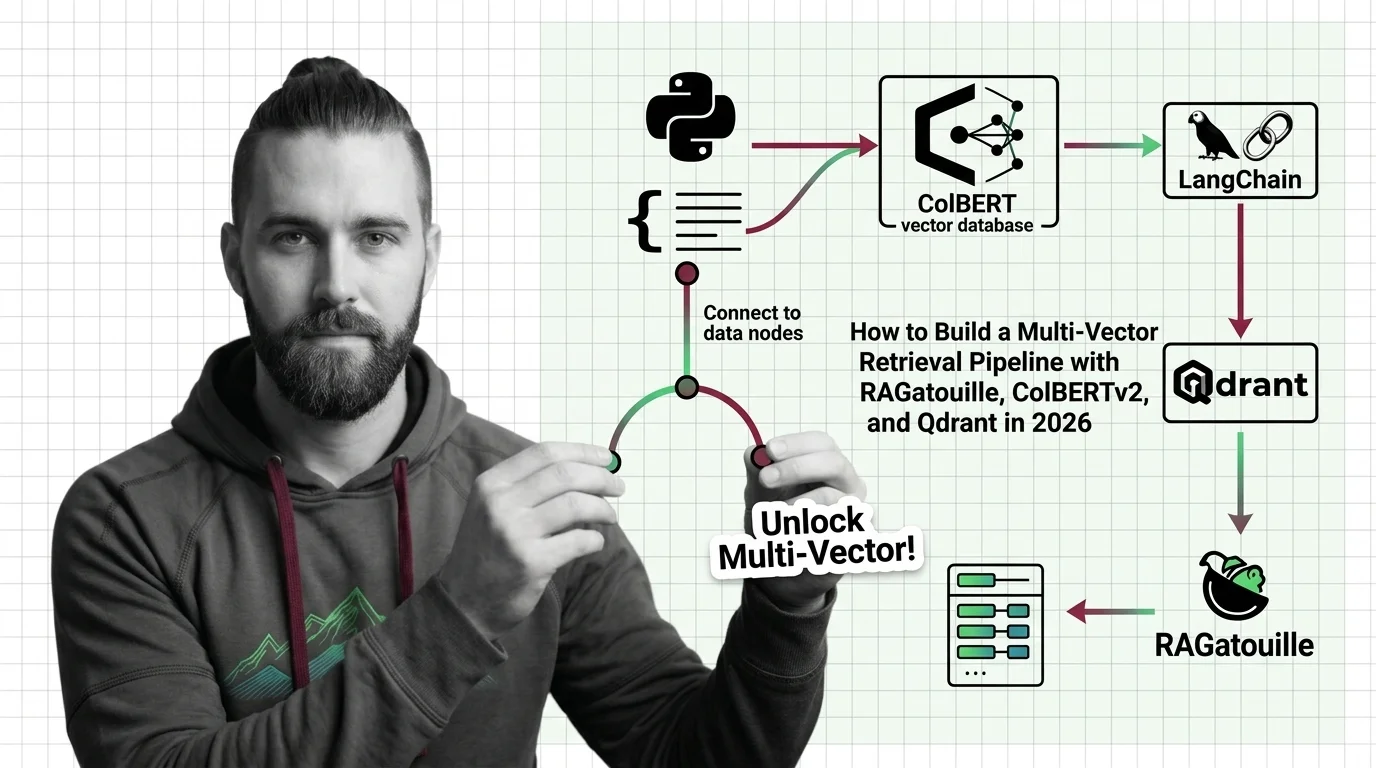
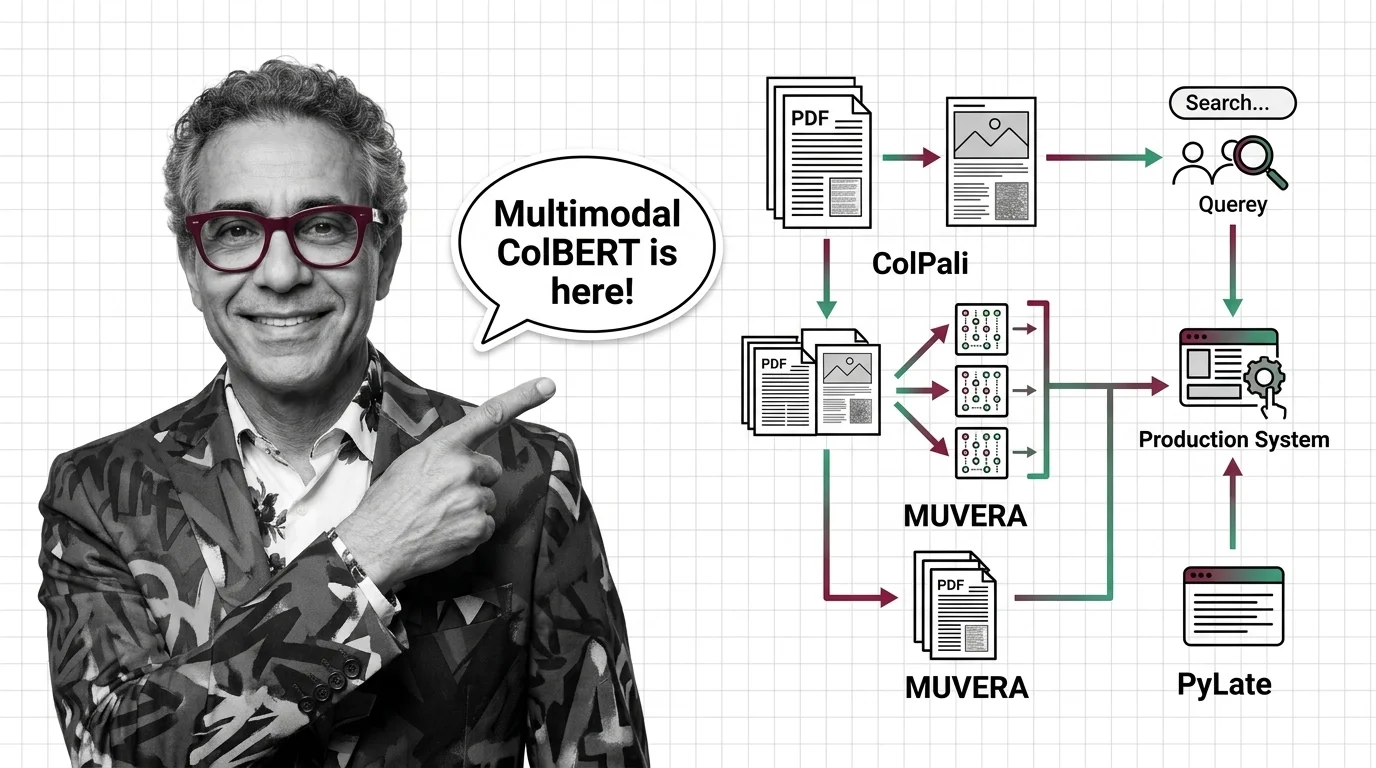
From Embeddings to Token-Level Matching: Prerequisites and Hard Limits of Multi-Vector Search
Multi-vector retrieval trades storage and latency for token-level precision. Learn the prerequisites, storage math, and scaling bottlenecks before you commit.