Multi-Vector Retrieval
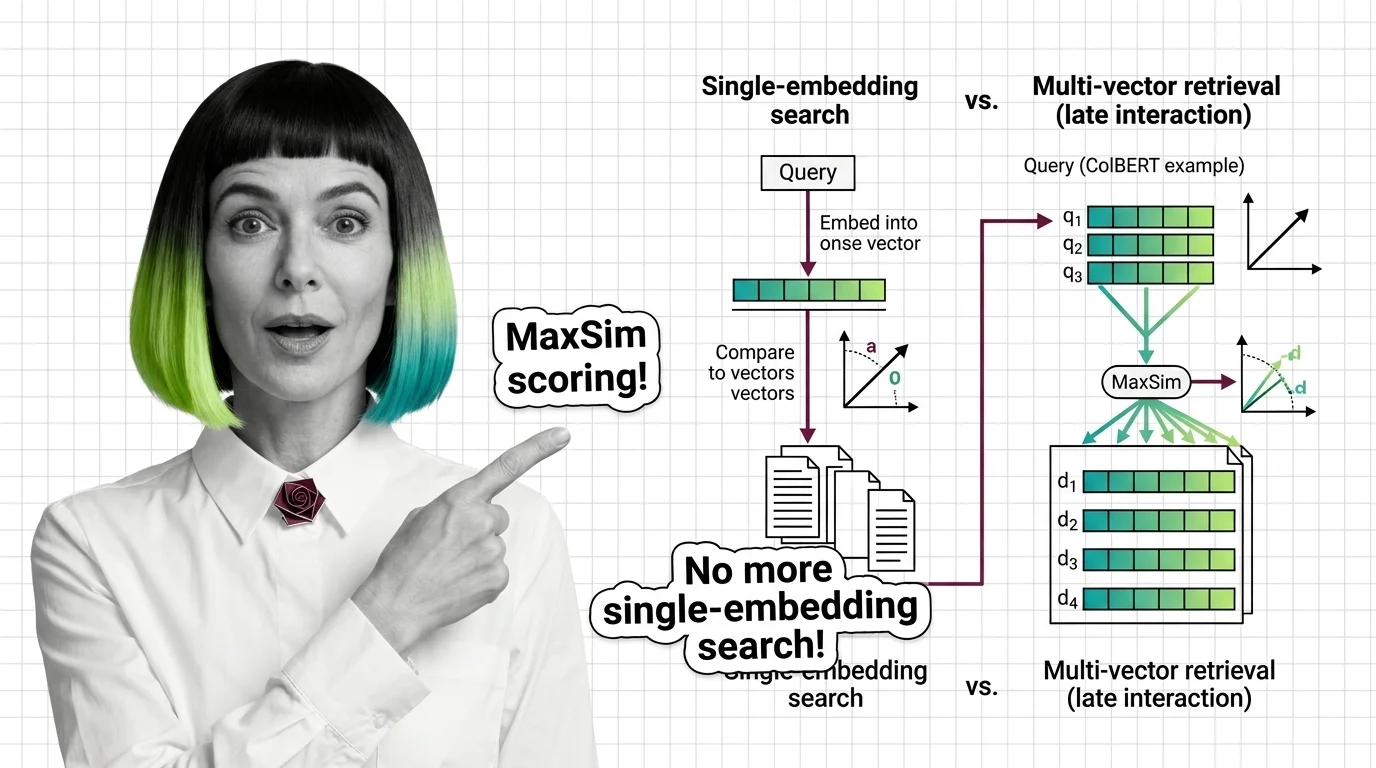
Multi-vector retrieval is a search approach that represents each document as multiple vectors rather than a single embedding. By assigning separate vectors to individual tokens or passages, techniques like late interaction compute fine-grained similarity between queries and documents at retrieval time. This produces more accurate matches than single-vector search, especially for complex queries where meaning varies across different parts of the text. Also known as: ColBERT, Late Interaction
Understand the Fundamentals
Multi-vector retrieval decomposes documents into token-level representations, enabling similarity matching at a granularity single-embedding models cannot reach. Understanding how late interaction works reveals why retrieval accuracy and computational cost trade off differently here.

Build with Multi-Vector Retrieval
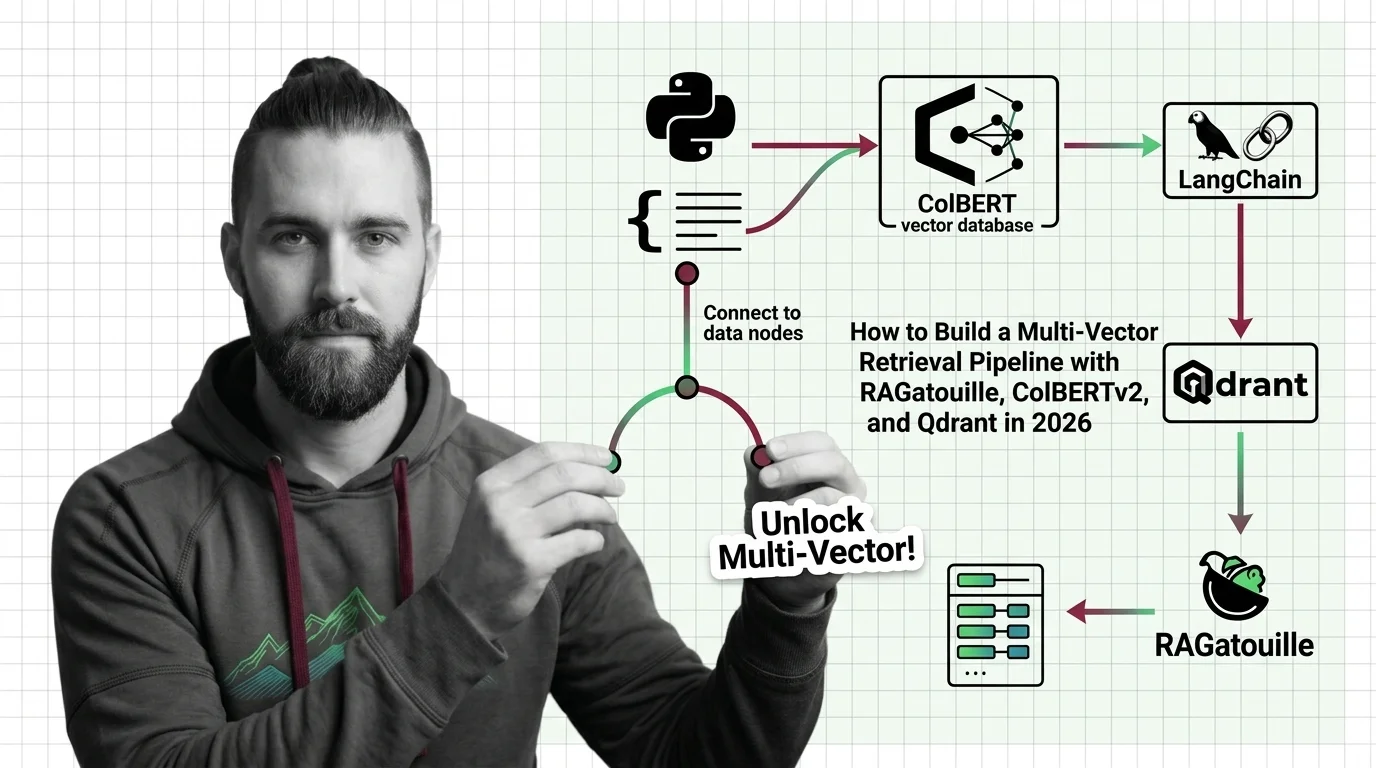
The practical guides walk through building a multi-vector retrieval pipeline end to end, covering indexing strategies, storage trade-offs, and the engineering decisions that determine whether the accuracy gains justify the added infrastructure complexity.
What's Changing in 2026
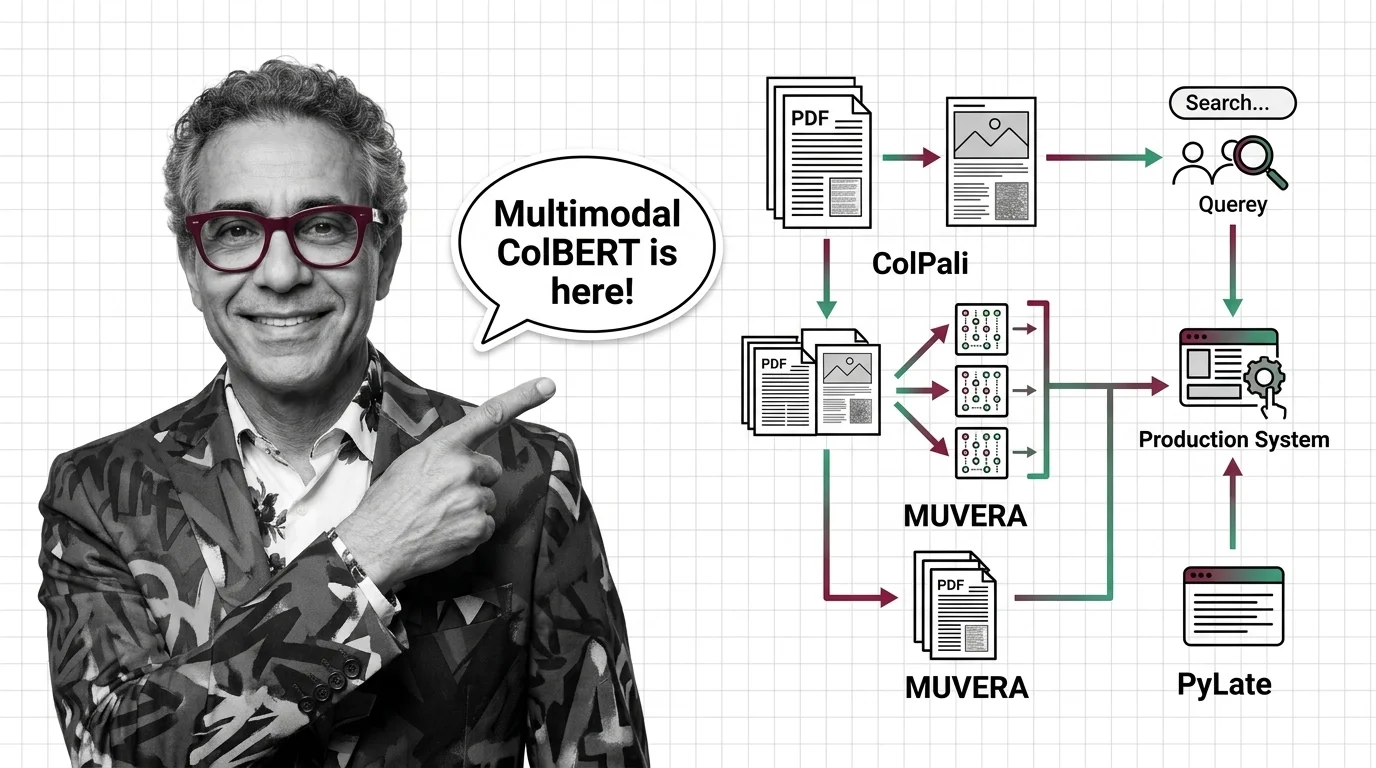
Multi-vector retrieval is expanding beyond text into multimodal search, and the tooling landscape shifts fast. Staying current on new model architectures and library releases matters for anyone building production retrieval systems.
Updated March 2026
Risks and Considerations
Finer-grained matching means larger indexes, higher costs, and more complex failure modes. Before adopting multi-vector retrieval, consider who bears the infrastructure burden and whether the accuracy gains actually reach every user group.
