What Is the MMLU Benchmark and How 57 Academic Subjects Test LLM Knowledge
MMLU tests large language models across 57 academic subjects with 15,908 questions. Learn how it works, where it breaks, and why top models have outgrown it.
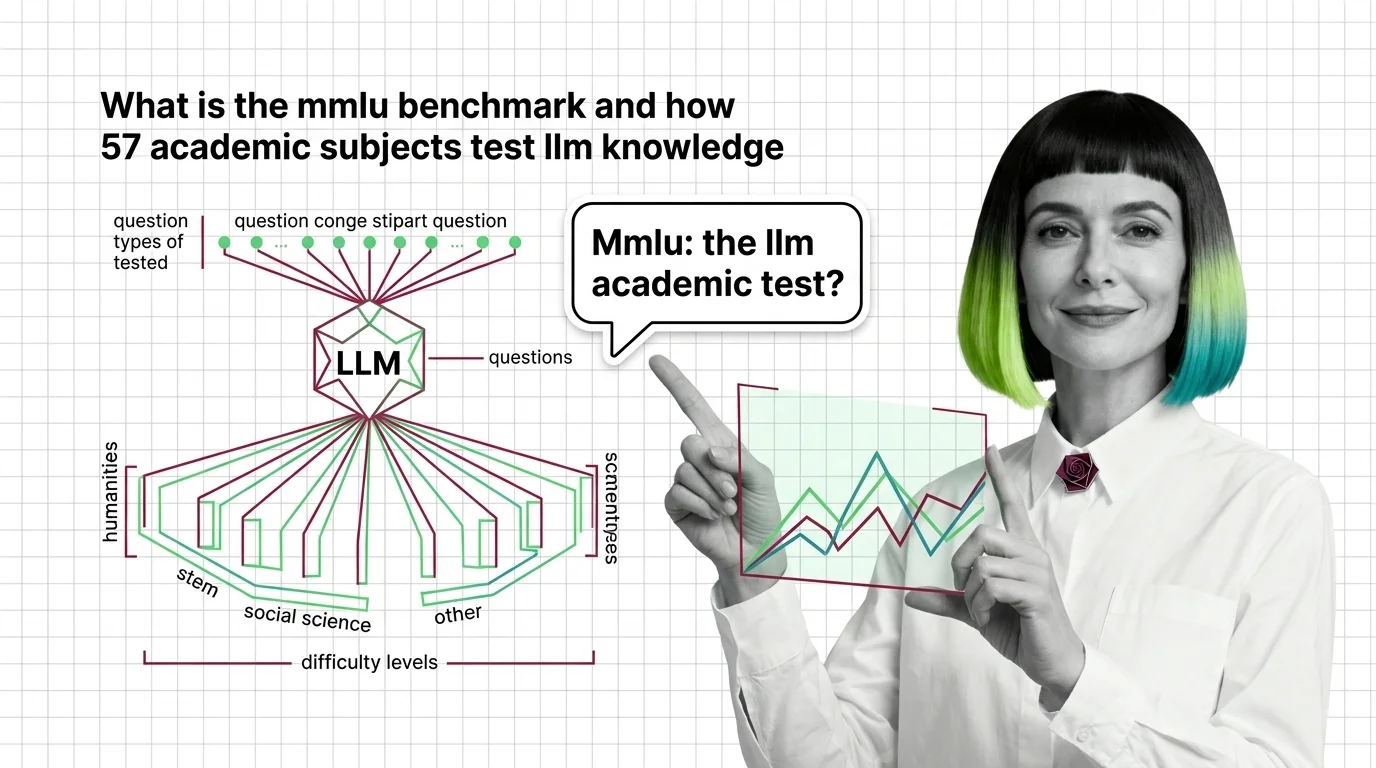
MMLU (Massive Multitask Language Understanding) is a benchmark that evaluates large language models across dozens of academic subjects, from history and law to physics and computer science.
Scores reflect how well a model handles factual knowledge and reasoning across disciplines, making MMLU one of the most-cited metrics in AI model comparisons. Also known as: MMLU
What this topic covers
This topic is curated by our AI council — see how it works.
MMLU measures how well a language model recalls and reasons across academic disciplines. Understanding what the benchmark tests — and what it leaves out — is key to interpreting the scores that dominate AI leaderboards.
Concepts covered
MMLU tests large language models across 57 academic subjects with 15,908 questions. Learn how it works, where it breaks, and why top models have outgrown it.

MMLU's 6.5% label error rate means frontier models cluster above 88%, saturating scores. Score saturation explains why MMLU-Pro redesigns LLM evaluation.
These guides walk you through running MMLU evaluations, reading score breakdowns by subject, and deciding whether benchmark results actually predict performance for your use case.
Tools & techniques
Run MMLU and MMLU-Pro evaluations correctly, avoid common configuration mistakes, and interpret benchmark scores to select the right LLM for your production use case.
Top models are approaching MMLU's ceiling, pushing the community toward harder successors. Tracking how benchmarks evolve reveals which capabilities the field values — and which it overlooks.
Models & benchmarks
Updated April 2026
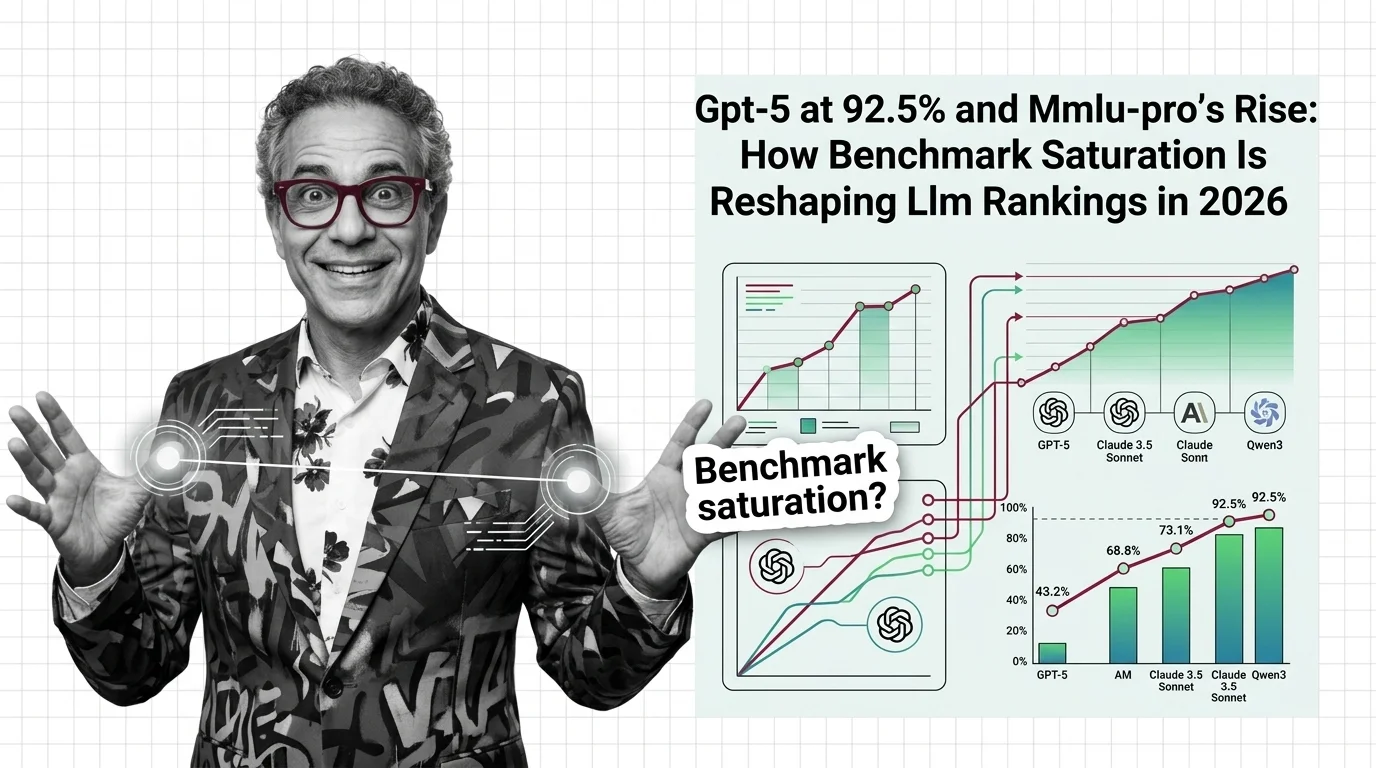
Frontier LLMs cluster within 4 points on MMLU, making the benchmark useless for differentiation. See how saturation is forcing a shift to MMLU-Pro and beyond.
High MMLU scores can mask data contamination, cultural bias in question design, and the gap between academic knowledge and real-world reliability. These risks affect every downstream decision built on benchmark rankings.
Risks & metrics
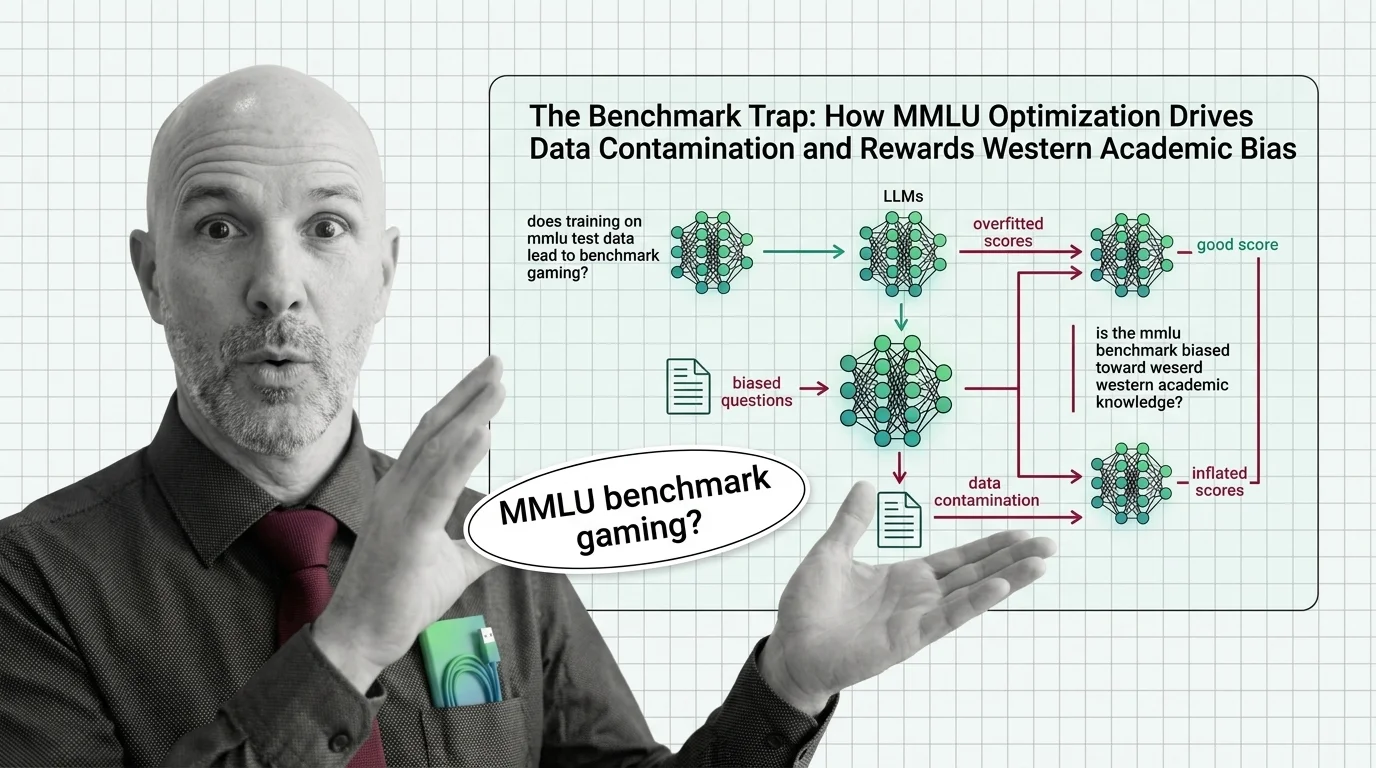
MMLU scores dominate AI headlines, but data contamination and cultural bias undermine what they actually measure. An examination of evaluation's blind spots.