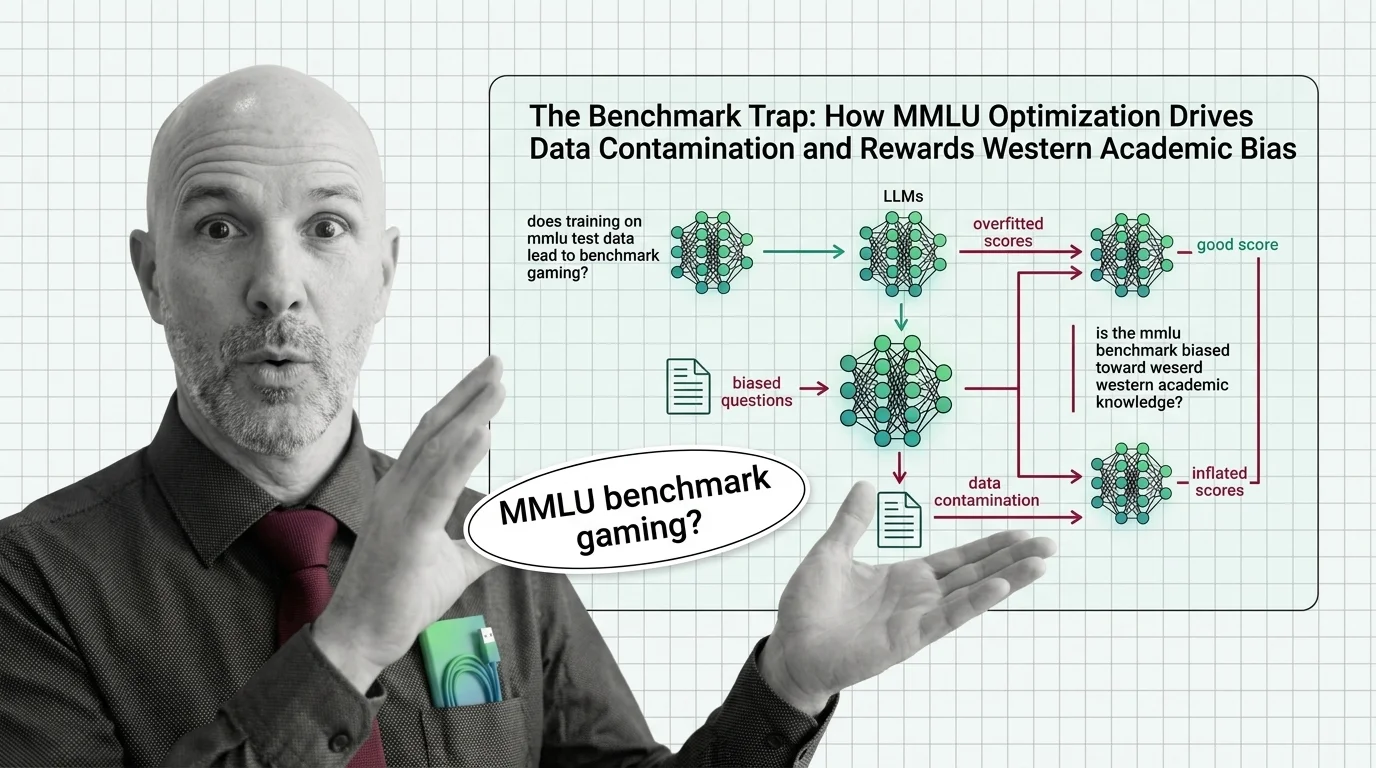
MMLU Benchmark
MMLU (Massive Multitask Language Understanding) is a benchmark that evaluates large language models across dozens of academic subjects, from history and law to physics and computer science. Scores reflect how well a model handles factual knowledge and reasoning across disciplines, making MMLU one of the most-cited metrics in AI model comparisons. Also known as: MMLU
Understand the Fundamentals
MMLU measures how well a language model recalls and reasons across academic disciplines. Understanding what the benchmark tests — and what it leaves out — is key to interpreting the scores that dominate AI leaderboards.

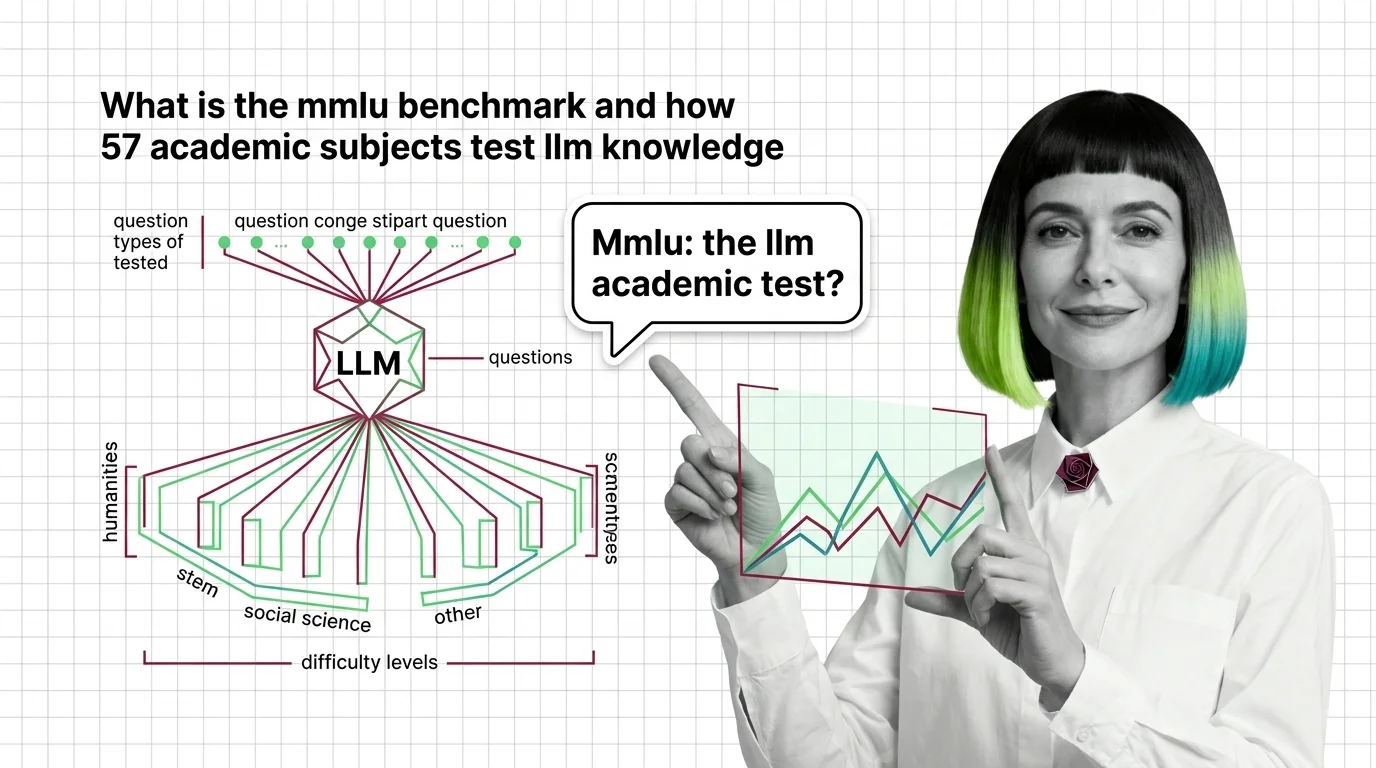
Build with MMLU Benchmark
These guides walk you through running MMLU evaluations, reading score breakdowns by subject, and deciding whether benchmark results actually predict performance for your use case.
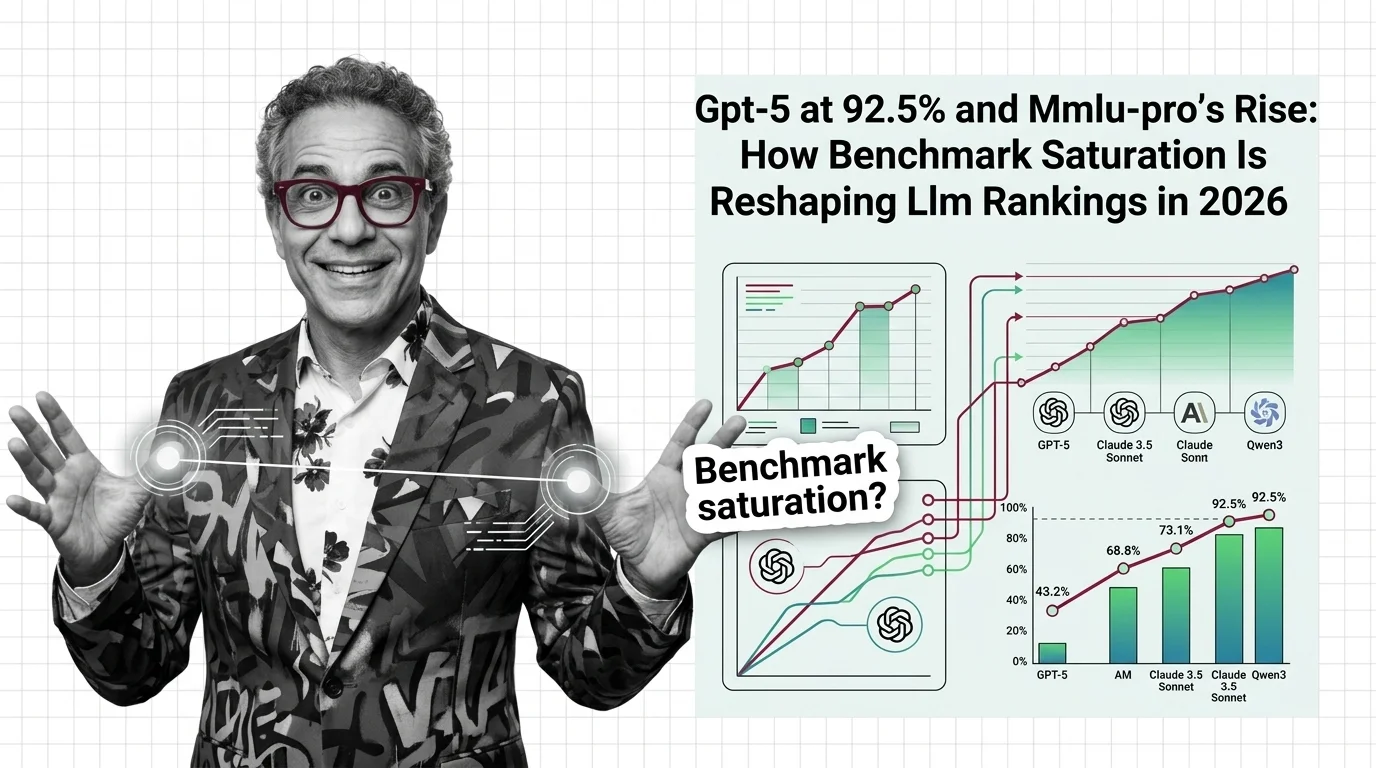
What's Changing in 2026
Top models are approaching MMLU’s ceiling, pushing the community toward harder successors. Tracking how benchmarks evolve reveals which capabilities the field values — and which it overlooks.
Updated April 2026
Risks and Considerations
High MMLU scores can mask data contamination, cultural bias in question design, and the gap between academic knowledge and real-world reliability. These risks affect every downstream decision built on benchmark rankings.