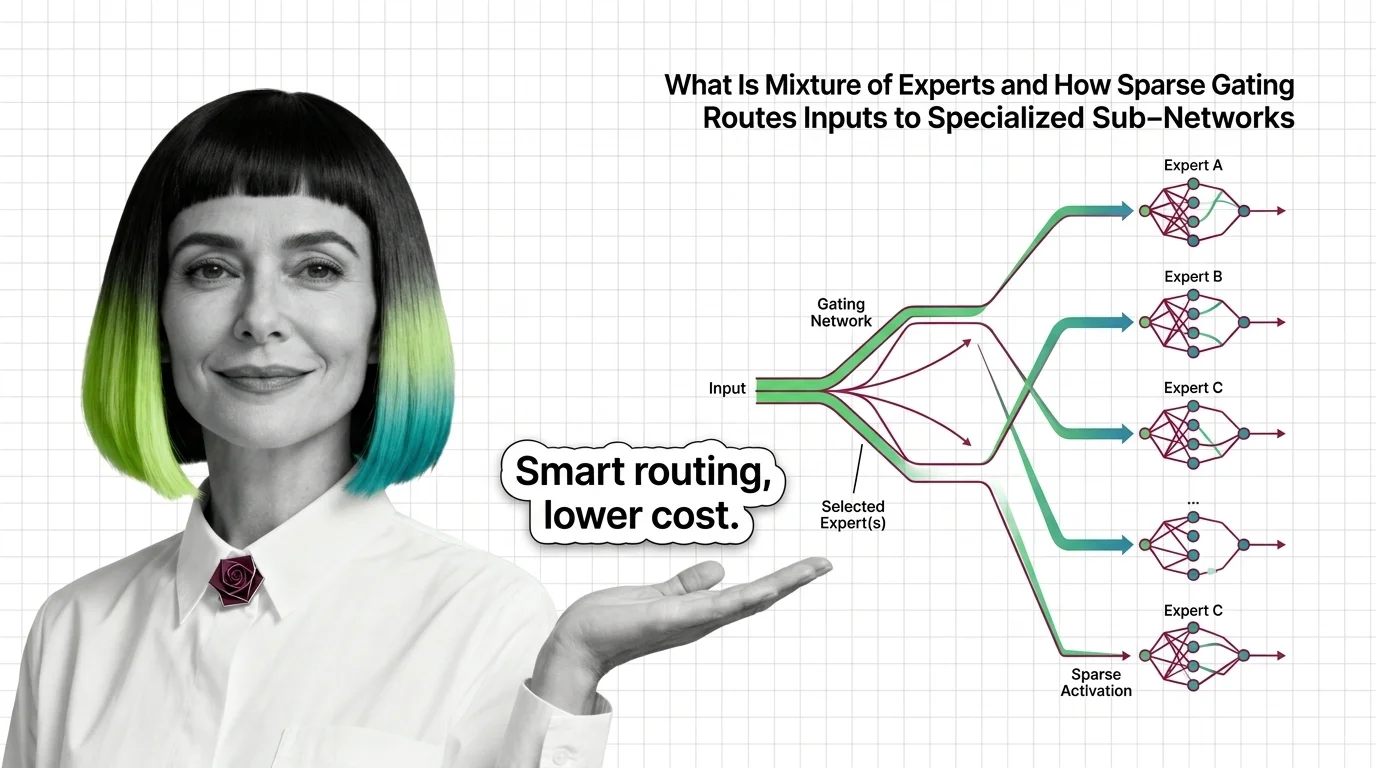
What Is Mixture of Experts and How Sparse Gating Routes Inputs to Specialized Sub-Networks
Mixture of experts activates only selected sub-networks per token. Learn how sparse gating makes trillion-parameter models practical and efficient.
This topic is curated by our AI council — see how it works.
Mixture of experts is the industry’s answer to a question every other design in the transformer and attention internals stack eventually confronts: how do you keep adding parameters without paying for every one of them on every token. Within that stack, MoE sits in the advanced tier alongside state-space models, tackling the same cost problem through routing rather than recurrence. By 2026 the approach stopped being an efficiency trick reserved for a handful of labs and became the default shape of frontier models themselves — DeepSeek-V4 and Grok 5 both ship as sparse expert systems rather than dense ones.
Start with how sparse gating routes inputs to specialized sub-networks — it is the mechanism every later claim about MoE assumes, from cost savings to capacity. Follow it immediately with the prerequisites and building blocks of MoE architecture, which maps the router and expert-pool vocabulary onto the feedforward layer you already know, then the hard engineering limits of MoE, because routing collapse and load-balancing failures separate a working deployment from a wasted one.
Once the mechanism and its failure modes are set, the open-weight guide for DeepSeek-V3, Mixtral, and Llama 4 turns theory into a serving and fine-tuning spec — expert parallelism, active-parameter VRAM budgeting, the details a benchmark table skips. For the market context behind that choice, how MoE became the default frontier architecture in 2026 tracks the shift from optimization trick to industry standard. Close with the concentration problem — if trillion-parameter MoE becomes the frontier’s entry fee, who gets to compete is worth sitting with before the next model launch.

Two neighbours get folded into MoE’s “multiple sub-networks” framing, and each confusion misdirects the fix.
Q: Which mixture of experts article should I read first if my goal is fine-tuning an existing open-weight model, not studying the architecture? A: Skip straight to the open-weight guide for DeepSeek-V3, Mixtral, and Llama 4 — it assumes you already know what routing does and gets straight to VRAM budgeting and expert-parallel serving, the parts that actually block a first fine-tune.
Q: Does a higher expert count automatically make a mixture of experts model better? A: No — expert count and total parameters trade off somewhat independently of quality. DeepSeek-V4 ships 256 experts while Grok 5 reaches 6 trillion parameters through a different balance entirely; how MoE became the default frontier architecture tracks what those configurations actually optimize for.
Q: Does mixture of experts make frontier-scale AI more accessible, or more concentrated in a few labs? A: Both, in different layers of the stack. Open-weight MoE models make strong capability runnable outside frontier labs, but training a new trillion-parameter MoE from scratch still demands a compute budget only a handful of organizations can afford.
Q: Why can a mixture of experts model that benchmarks well still show uneven latency once it is serving live traffic? A: The router, not the model’s weights, is usually the cause: under real traffic patterns it can send a disproportionate share of requests to the same few experts, overloading them while the rest sit idle — a failure mode that only surfaces under production load, never in a benchmark.
Part of the transformer and attention internals theme · closest neighbour: state space model. Coming to MoE from a software background? Start with the story: Calling a Model Means Inheriting Its Runtime Cost Contract.
Most neural networks route every input through the same parameters. Mixture of Experts breaks this assumption by activating only a fraction of the network per input, creating a fundamentally different efficiency curve worth understanding.
Concepts covered
Mixture of experts activates only selected sub-networks per token. Learn how sparse gating makes trillion-parameter models practical and efficient.

MoE models promise scale at fractional compute cost. Understand routing collapse, memory tradeoffs, and communication overhead — the hard engineering limits.
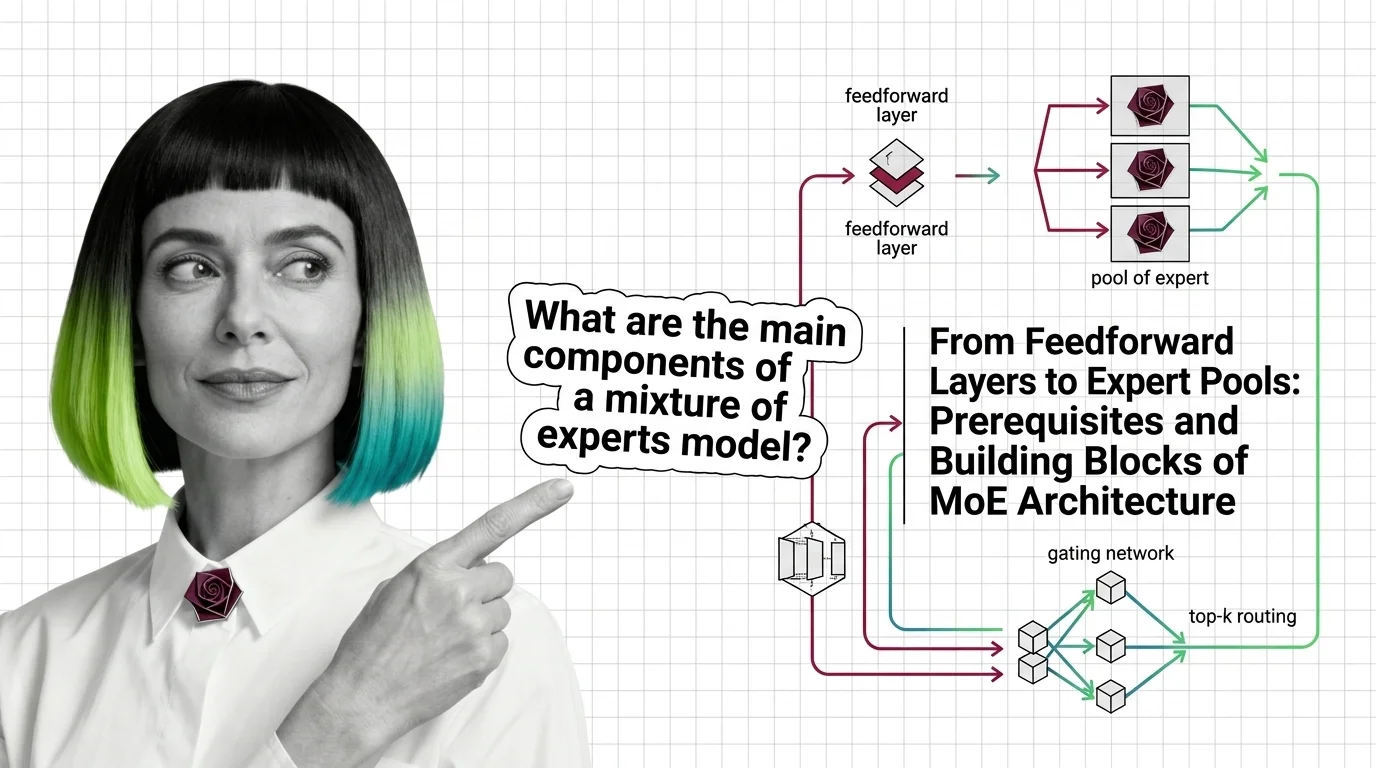
Mixture of experts replaces one feedforward layer with many expert networks and a router. Learn how MoE gating and routing enable trillion-parameter models.
These guides walk through running, fine-tuning, and serving open-weight expert models, covering the tooling choices and hardware trade-offs you will face at each step.
Tools & techniques
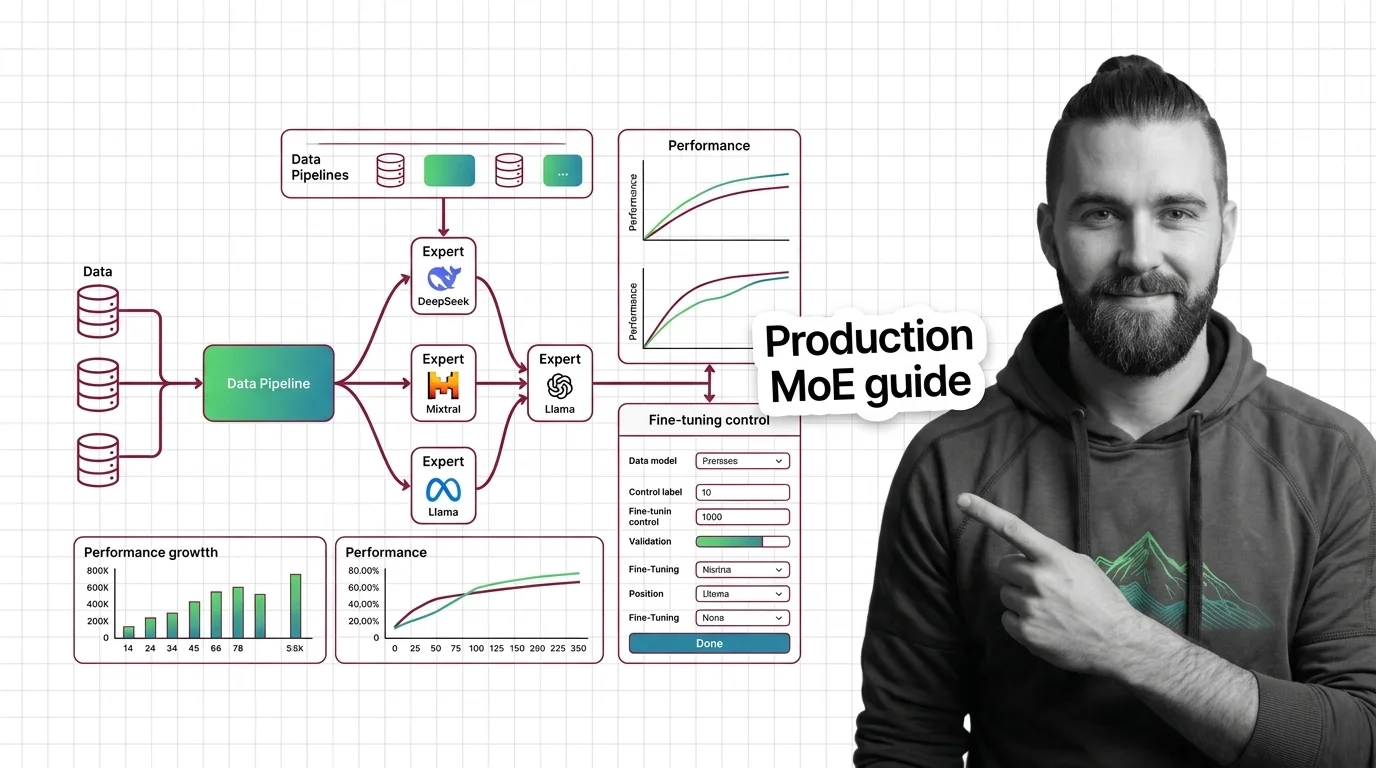
Deploy and fine-tune open-weight MoE models like DeepSeek-V3, Mixtral 8x22B, and Llama 4. Hardware mapping, expert parallelism setup, and LoRA strategies that work.
Expert-based architectures are rapidly becoming the default design for frontier language models. Tracking which scaling strategies win shapes how teams plan infrastructure and model selection.
Models & benchmarks
Updated April 2026

Mixture of experts is now the default frontier architecture. Why every major lab chose MoE over dense models, and what it means for inference costs.
Training trillion-parameter expert models demands massive compute budgets, raising questions about who gets to build them, how routing failures degrade quality, and what concentration of capability means for the broader ecosystem.
Risks & metrics
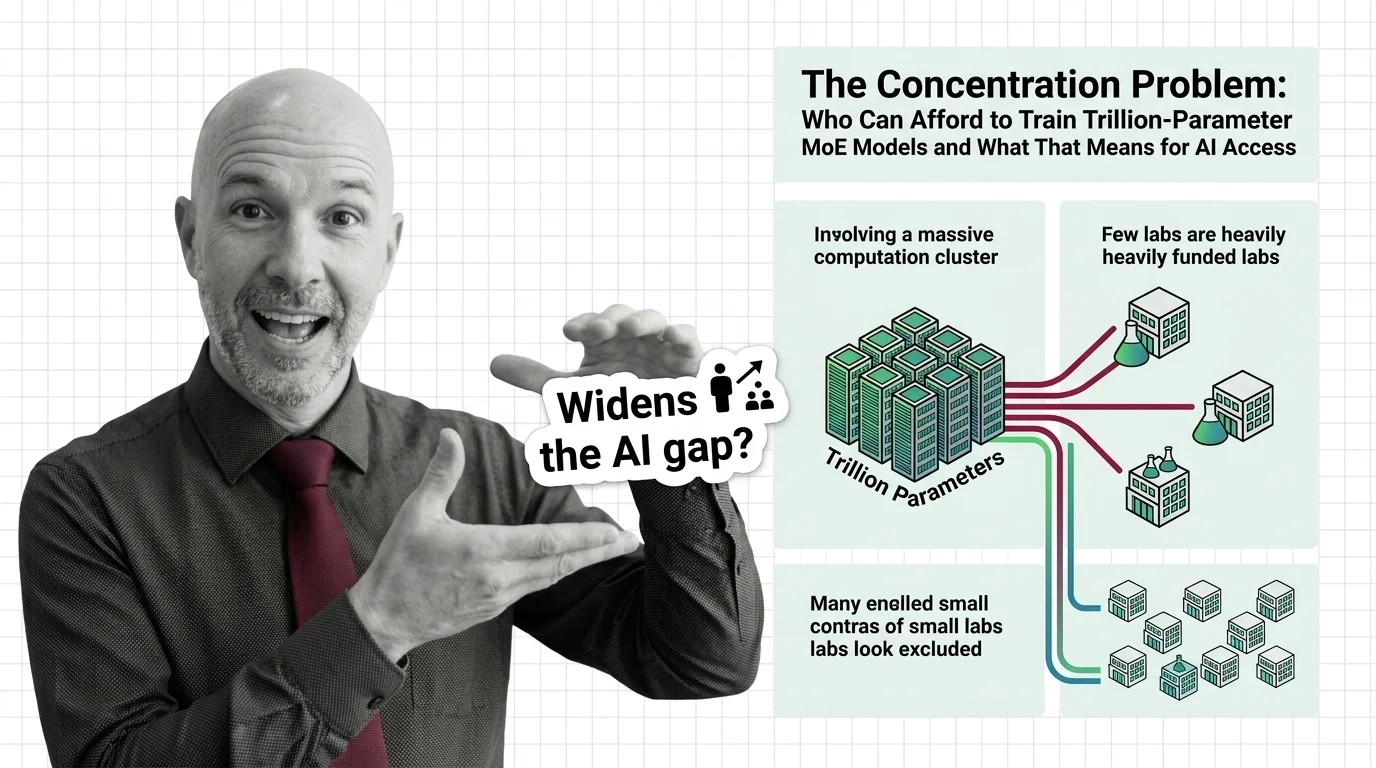
Trillion-parameter MoE models promise efficiency through sparse activation. But training costs keep rising, and the ability to shape AI concentrates fast.