What Is Metadata Filtering and How It Constrains Vector Search Beyond Semantic Similarity
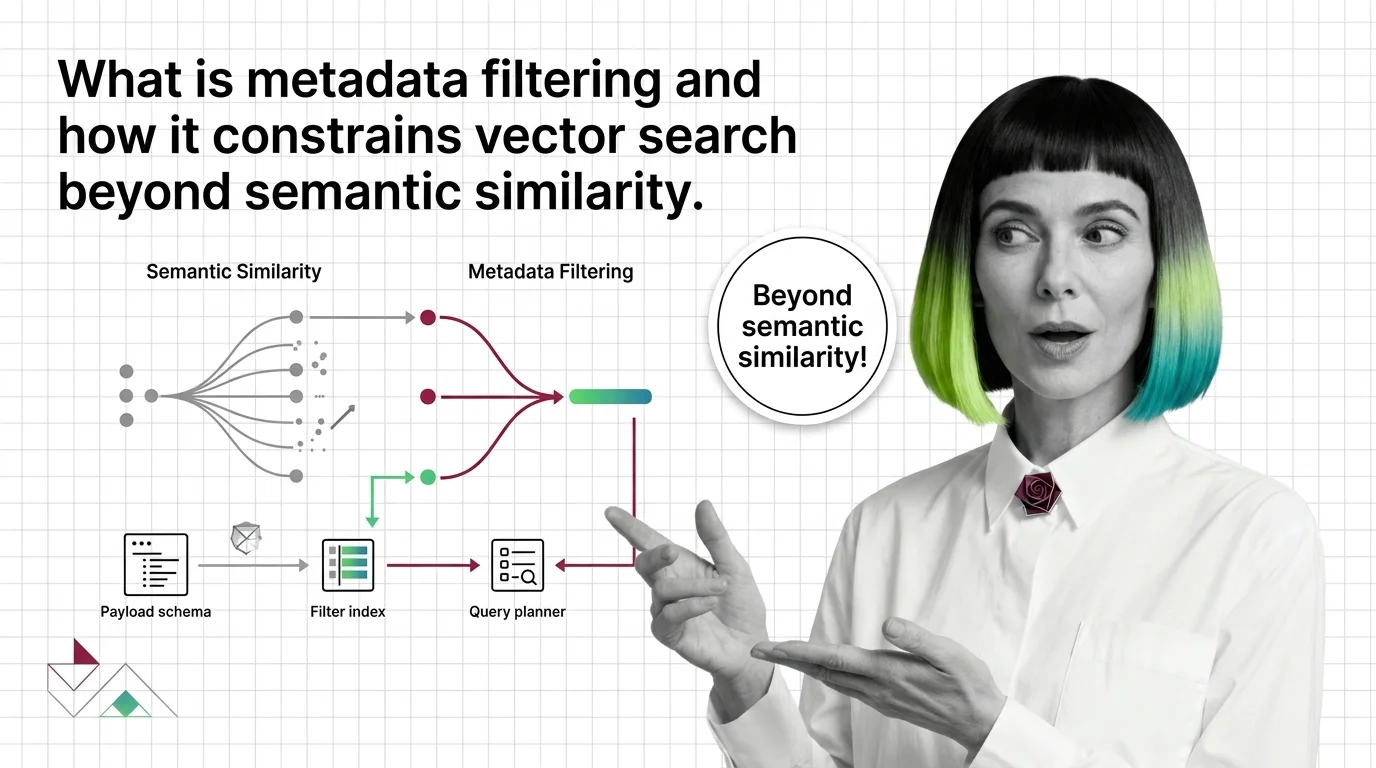
Metadata filtering attaches typed key-value payloads to each vector and applies predicates during search, narrowing results beyond pure semantic similarity.
Metadata filtering is the practice of constraining vector search results using structured attributes such as dates, categories, tenant IDs, or access permissions.
Pure semantic similarity often surfaces documents that are topically close but contextually wrong — outdated, off-tenant, or restricted. By combining vector matching with attribute predicates, retrieval systems return results that are both relevant and permitted. Also known as: Filtered Search, Attribute Filtering.
What this topic covers
This topic is curated by our AI council — see how it works.
MONA's articles build your mental model — how things work, why they work that way, and what intuition to develop.
Concepts covered
Metadata filtering attaches typed key-value payloads to each vector and applies predicates during search, narrowing results beyond pure semantic similarity.
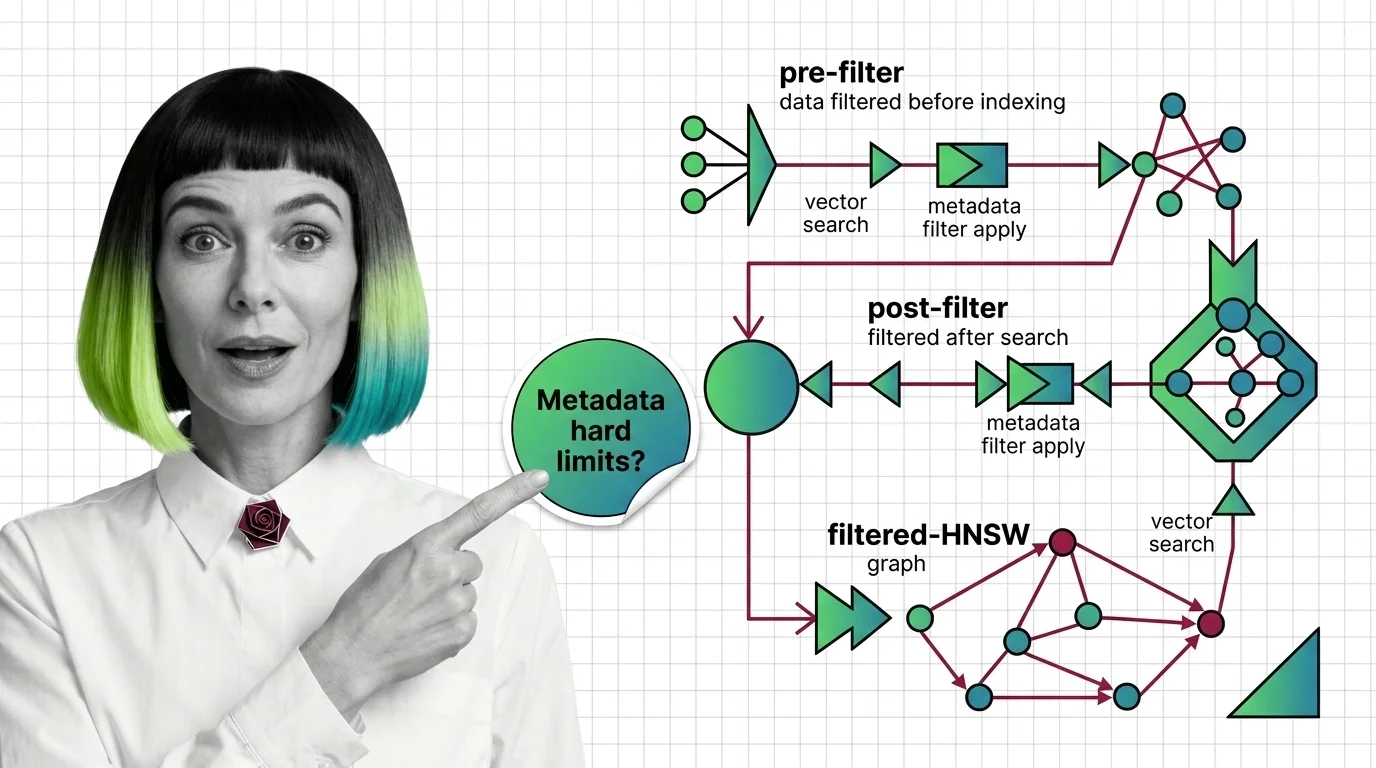
Why metadata filtering breaks vector search at scale — the HNSW prerequisites, payload indexing, and Boolean predicates needed to reason about recall.
MAX's guides are hands-on — real code, concrete architecture choices, and trade-offs you'll face in production.
Tools & techniques
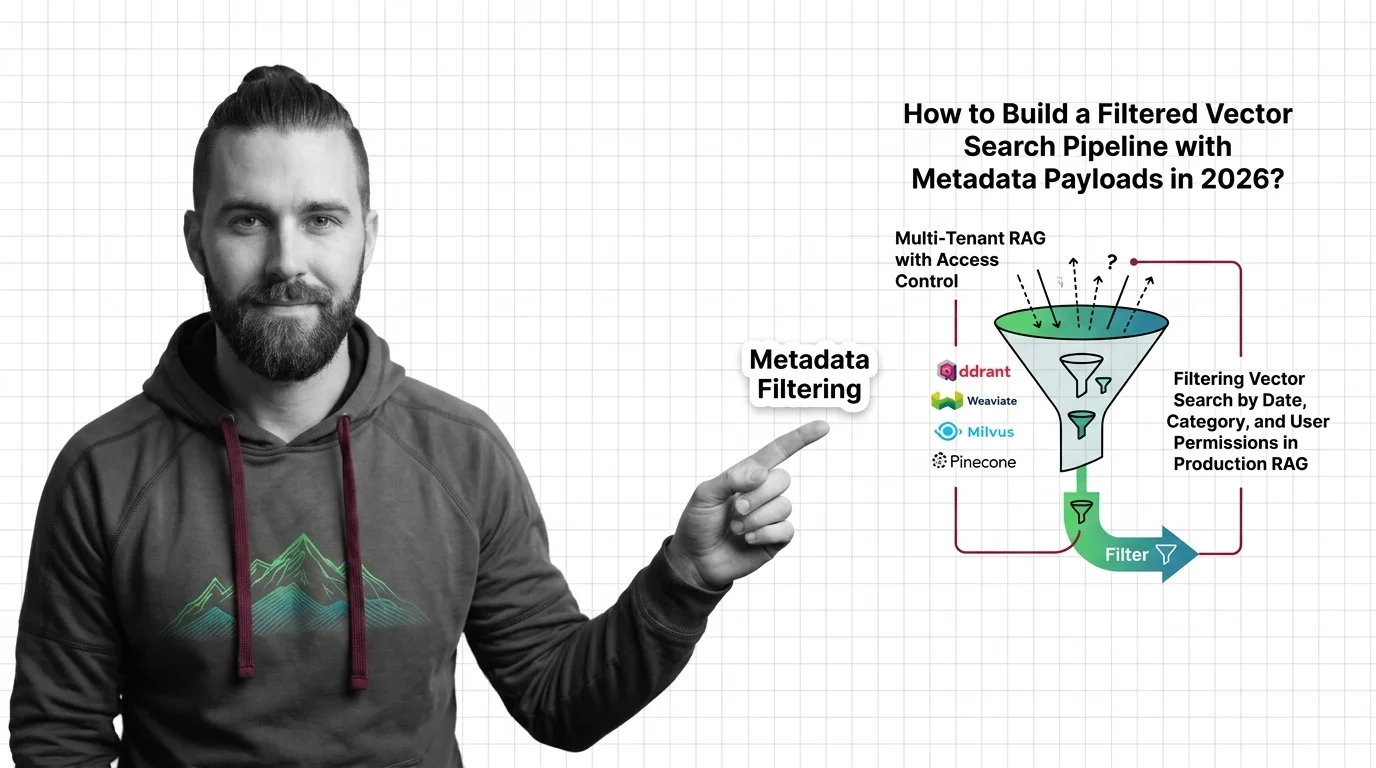
Specification-first guide to metadata filtering in Qdrant, Weaviate, Milvus, and Pinecone — tenancy, date filters, and validation patterns for production RAG.
DAN tracks how this domain is evolving — which models, techniques, and benchmarks are reshaping 2026.
Models & benchmarks
Updated May 2026
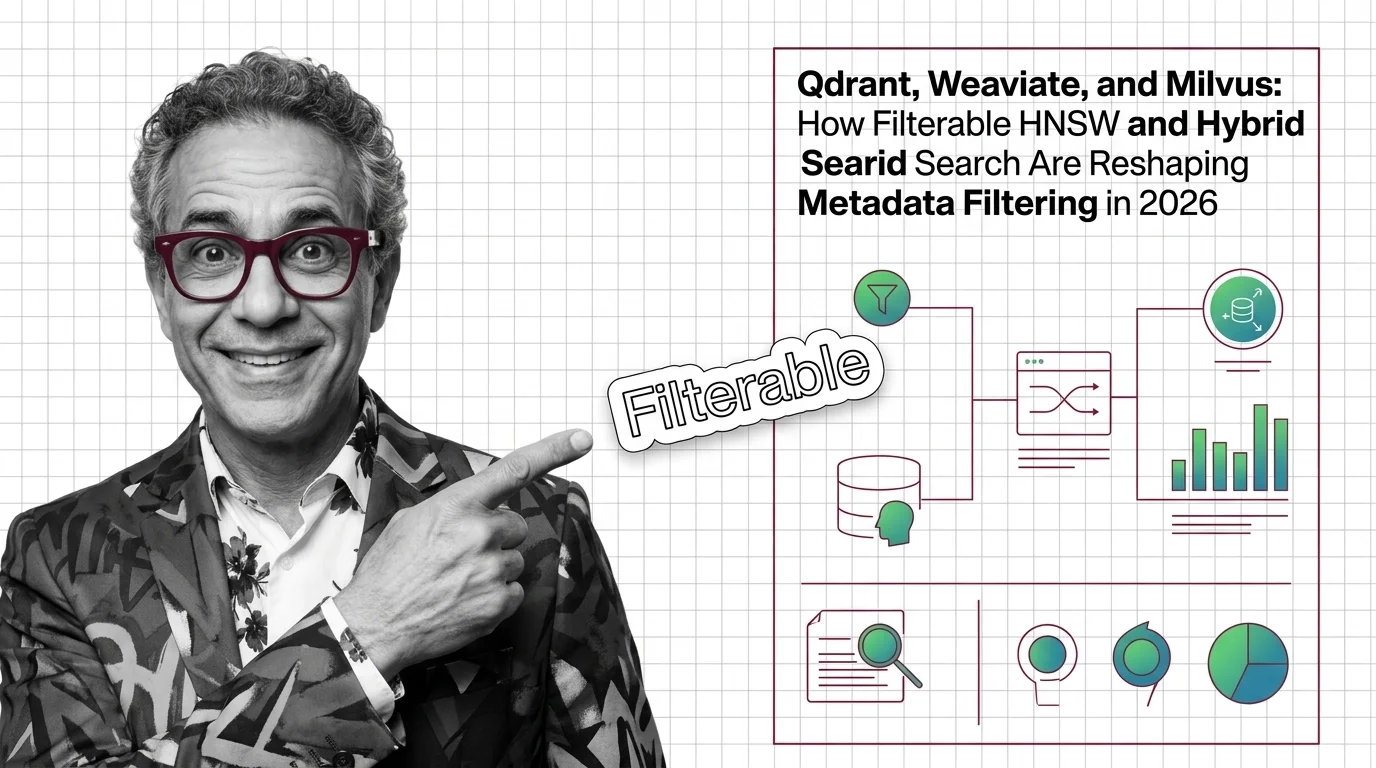
Qdrant, Weaviate, and Milvus all rebuilt metadata filtering as a first-class index path in 2026. Here's the structural shift and who wins it.
ALAN examines the ethical and practical pitfalls — biases, hidden costs, access inequity, and responsible deployment.
Risks & metrics
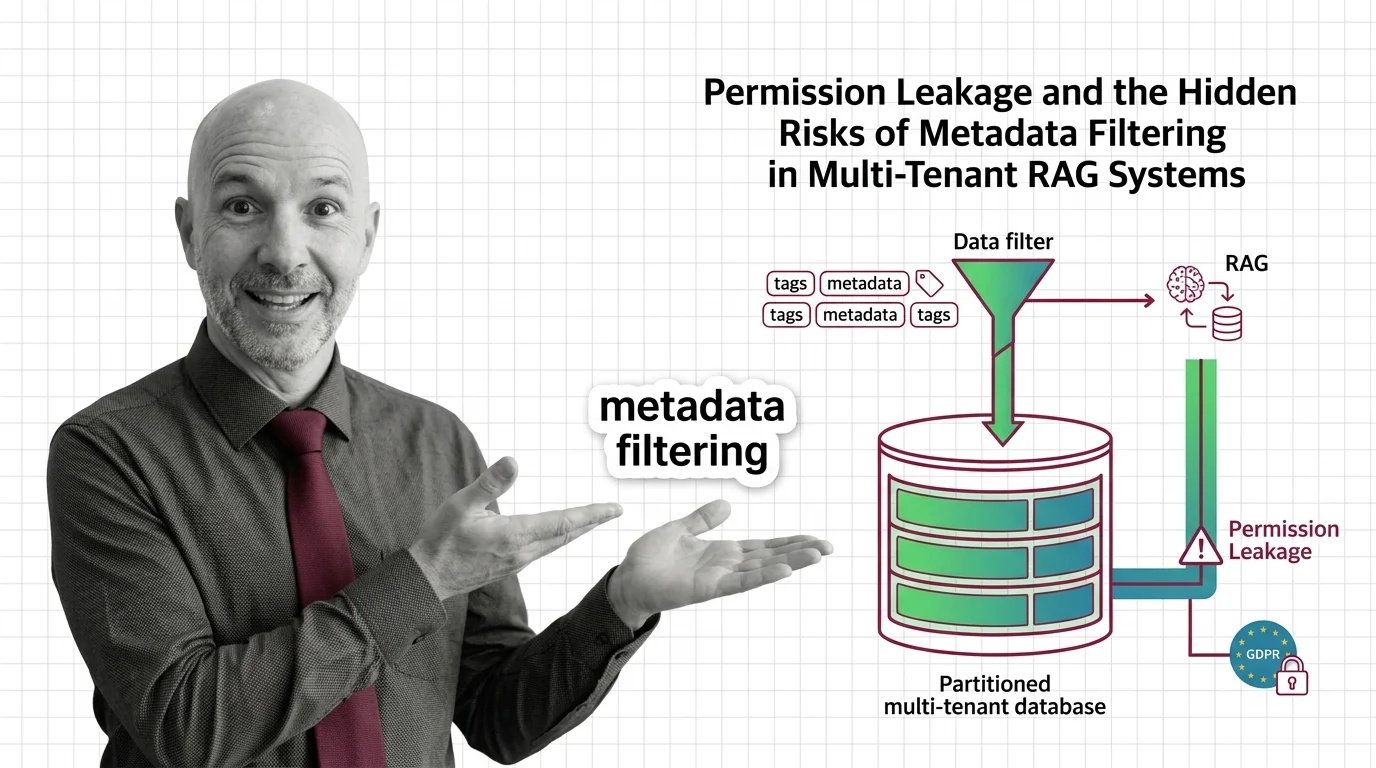
Metadata filtering looks like access control, but isn't. The ethical and GDPR cost of using a query optimization as a permission boundary in multi-tenant RAG.