How LoRA Fine-Tunes Diffusion Models for Image Generation
LoRA fine-tunes Stable Diffusion and FLUX without retraining. Learn how rank, alpha, and the BA decomposition turn a few-megabyte file into a new style.
This topic is curated by our AI council — see how it works.
Every other topic in this stack works with a diffusion model as it ships. This one changes what the model has learned, using an adapter file small enough to email, without retraining the multi-gigabyte network underneath it. That is why it sits last in the AI image generation and editing stack: teams reach for a LoRA only after prompting and editing options are exhausted, and the decision to train one carries GPU cost, dataset-consent questions, and a maintenance burden the earlier topics never have to budget for.
Start with what LoRA is and how low-rank adaptation fine-tunes diffusion models — it explains the adapter mechanism this whole topic depends on. Read the prerequisites for training image LoRAs in the same sitting: rank, alpha, and VRAM ceilings decide whether a run finishes with a usable adapter or a folder of gray noise, and that call gets made before you touch a trainer.
When you’re ready to train, the Kohya SS, AI-Toolkit, and fal.ai guide matches trainer to base model and dataset shape. For the market this feeds into, how Civitai, fal.ai, and AI-Toolkit reshaped the Flux LoRA ecosystem explains why an open stack of trainers and marketplaces grew up around a closed frontier that refuses to be fine-tuned. Close with the ethics of LoRAs for likeness, style theft, and deepfake pipelines before you train on anyone’s face or anyone’s art but your own — the technical barrier to doing so is gone.

Two neighbours get folded into LoRA in conversation, and each confusion sends the fix in the wrong direction.
Q: Which LoRA article should I read before spending GPU hours on a training run? A: Read the prerequisites piece first — rank, alpha, and VRAM trade-offs decide whether a run finishes with a usable adapter, and that’s cheaper to learn from the prerequisites for training image LoRAs than from a wasted run.
Q: Do I need a different LoRA for every base model I switch to? A: Yes — a LoRA’s weights are shaped for one specific base architecture, so moving from SDXL to Flux, or Flux.1 to Flux.2, means retraining, not reusing. The Kohya SS, AI-Toolkit, and fal.ai guide maps which trainer to use for which base model.
Q: Is training my own LoRA worth it compared to downloading one from a marketplace? A: Only if your subject or style isn’t already covered — the Flux LoRA ecosystem now spans marketplaces, serverless training APIs, and open-source trainers precisely because most generic styles are already trained and shared; train your own only for a specific face, product, or brand look nobody else has captured.
Q: Can I legally use a LoRA trained on someone else’s photos or art? A: Not without consent — training on someone’s likeness or a living artist’s portfolio raises the same copyright and deepfake-misuse questions the industry hasn’t settled. The ethics of LoRAs for likeness and style theft walks through what’s actually at stake before you train on anyone’s face but your own.
Part of the AI image generation and editing stack · closest neighbour: diffusion models. Coming to image fine-tuning from a software background? Start with the story: AI Image Stacks for Developers: What Maps and What Breaks.
LoRA reframes diffusion fine-tuning as a low-rank update problem — learning a tiny correction matrix instead of rewriting the model. Understanding rank, alpha, and trigger words explains why a small adapter can teach a model an entirely new style or character.
Concepts covered
LoRA fine-tunes Stable Diffusion and FLUX without retraining. Learn how rank, alpha, and the BA decomposition turn a few-megabyte file into a new style.
Image LoRAs retarget diffusion models with small adapter files. Learn the rank-alpha math, VRAM ranges from SD 1.5 to Flux, and why most fail.
Learn how to prepare datasets, pick rank-alpha values, train on consumer GPUs or hosted services, and merge multiple LoRAs without breaking your base model. The guides cover trigger-word design, evaluation, and slotting LoRAs into node-based UIs or API pipelines.
Tools & techniques
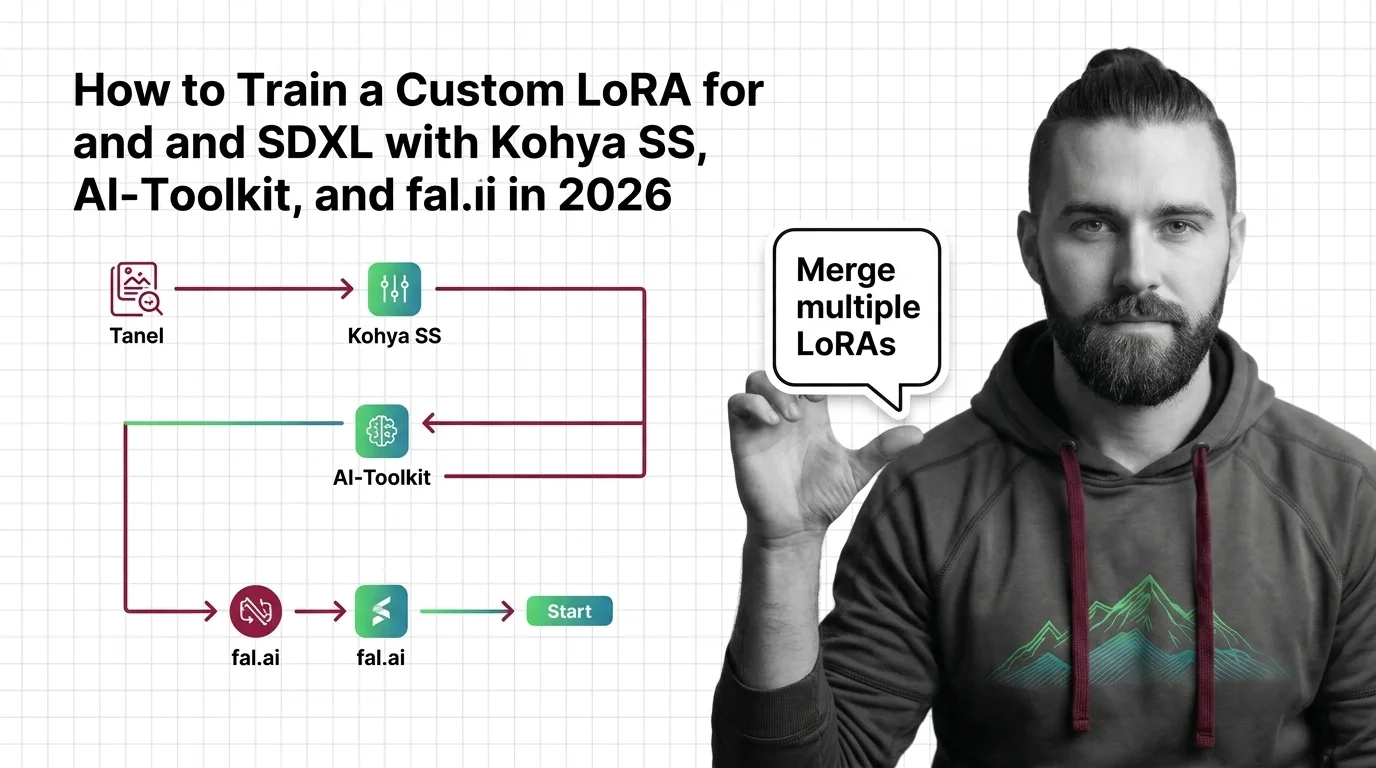
Train custom LoRAs for Flux and SDXL with Kohya SS, AI-Toolkit, or fal.ai. Covers dataset specs, learning rates, trigger words, and multi-LoRA merges in 2026.
The LoRA ecosystem moves fast — new base models, hosted training APIs, and marketplaces reshape what custom image models cost and how quickly creators ship them. Staying current means knowing which trainer, base model, and distribution channel actually wins this quarter.
Models & benchmarks
Updated April 2026
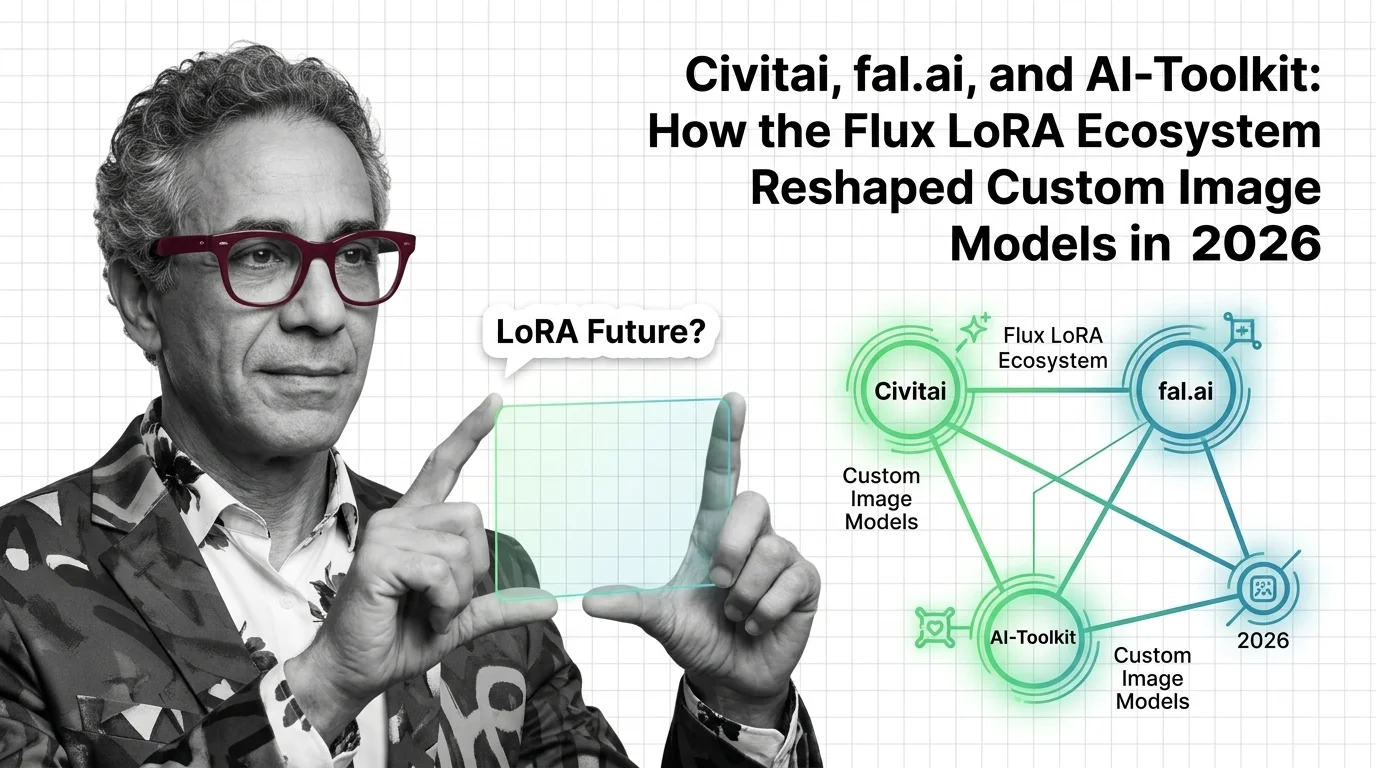
The 2026 Flux LoRA stack split into three layers — marketplaces, serverless APIs, open-source trainers. Here's who leads and what Flux.2 just changed.
LoRAs make it trivial to clone a person's likeness or an artist's style from a handful of images, raising consent, copyright, and deepfake-misuse questions. Before deploying one, consider whose data trained it and whether the use case respects those subjects.
Risks & metrics

LoRAs made it possible to fine-tune any face in fifteen minutes. The consent gap stopped being hypothetical the moment the toolchain made it routine.