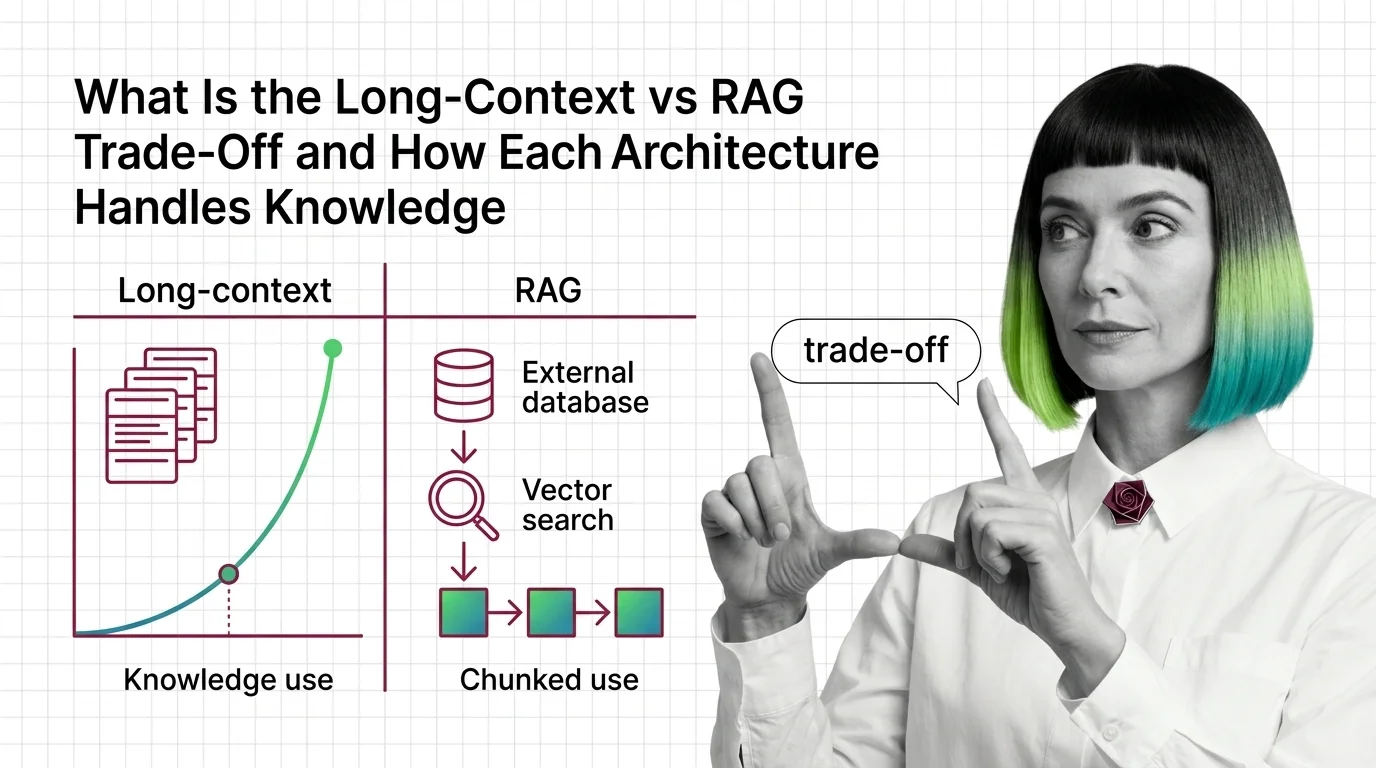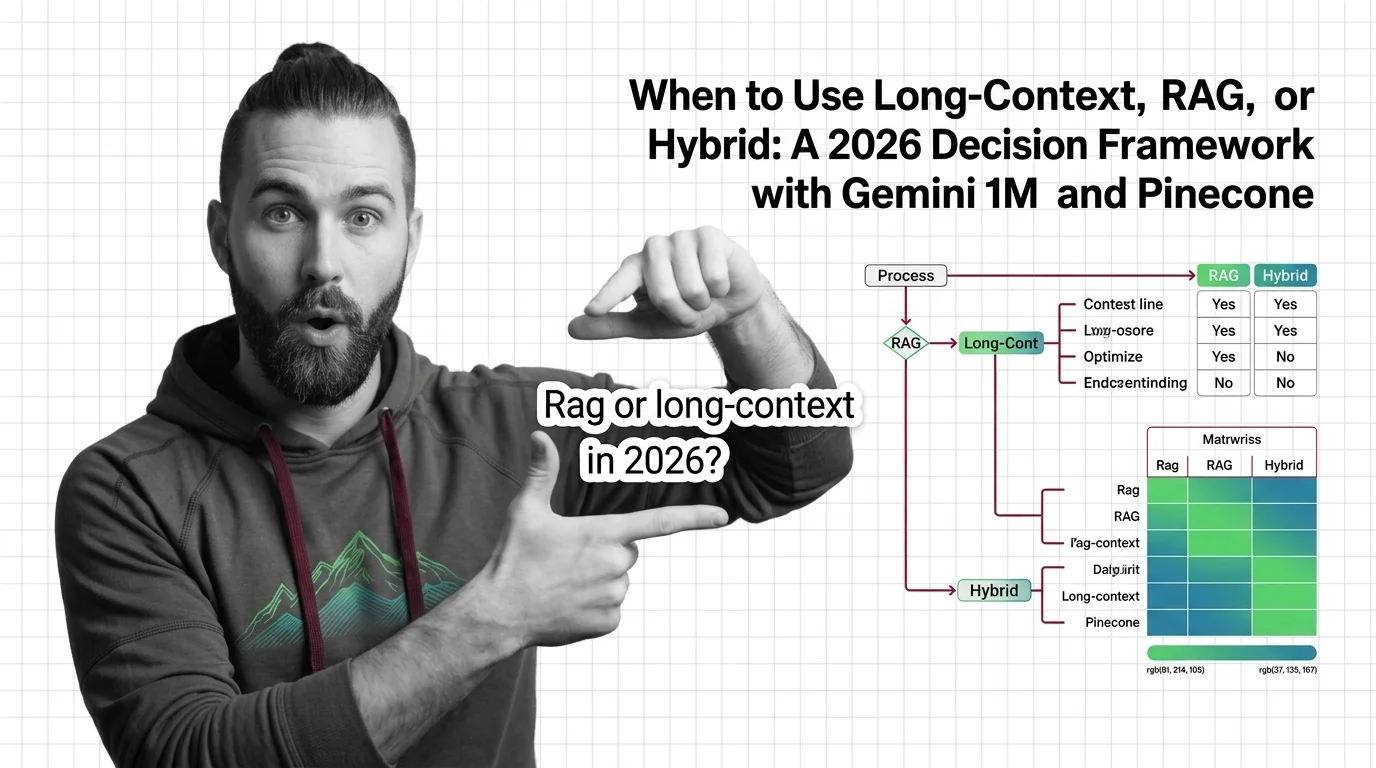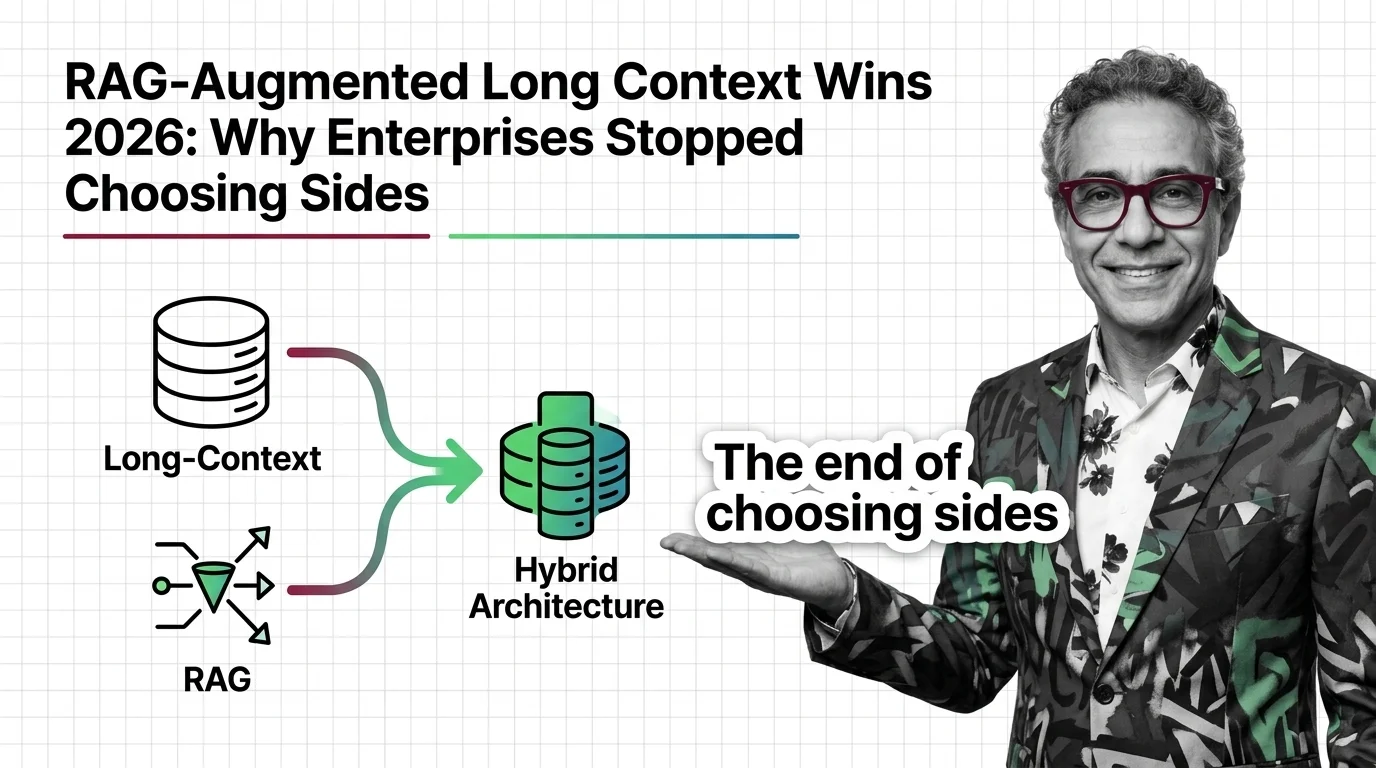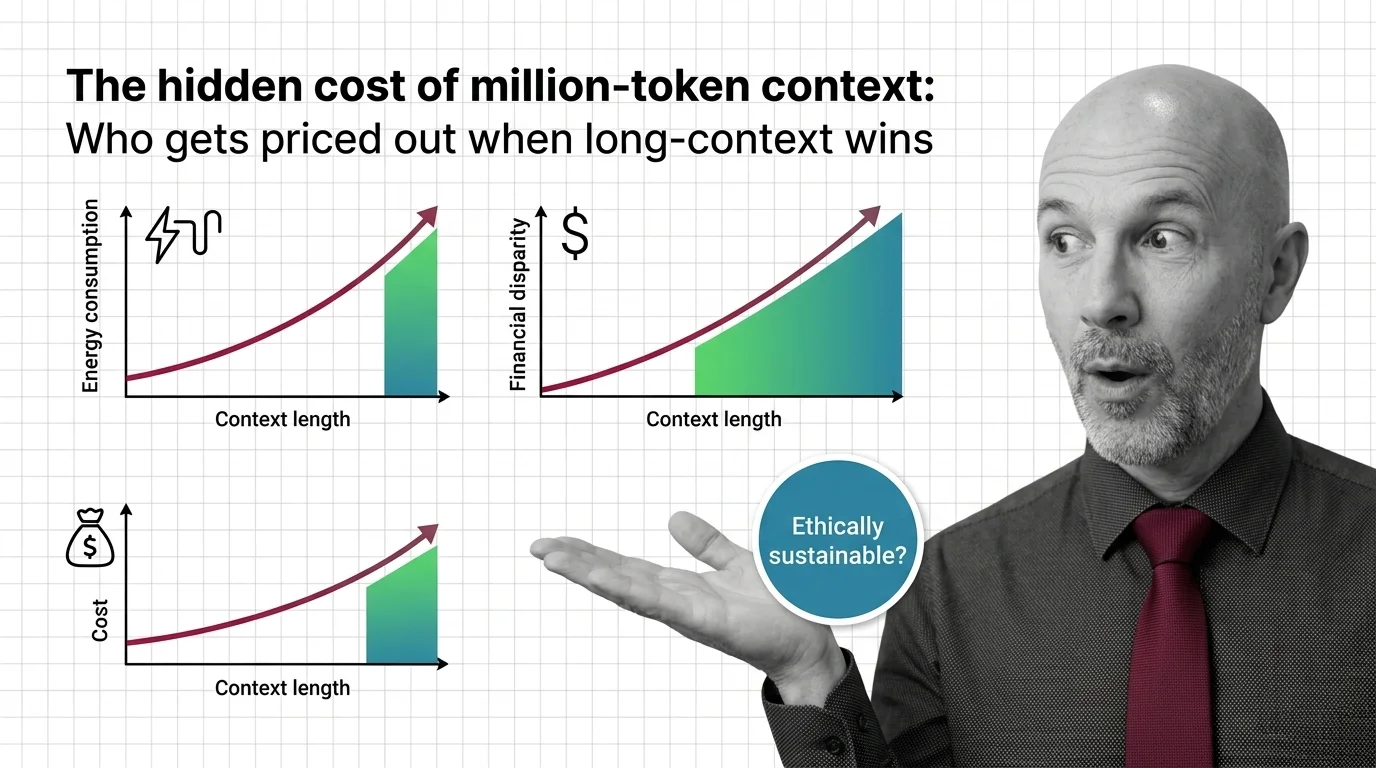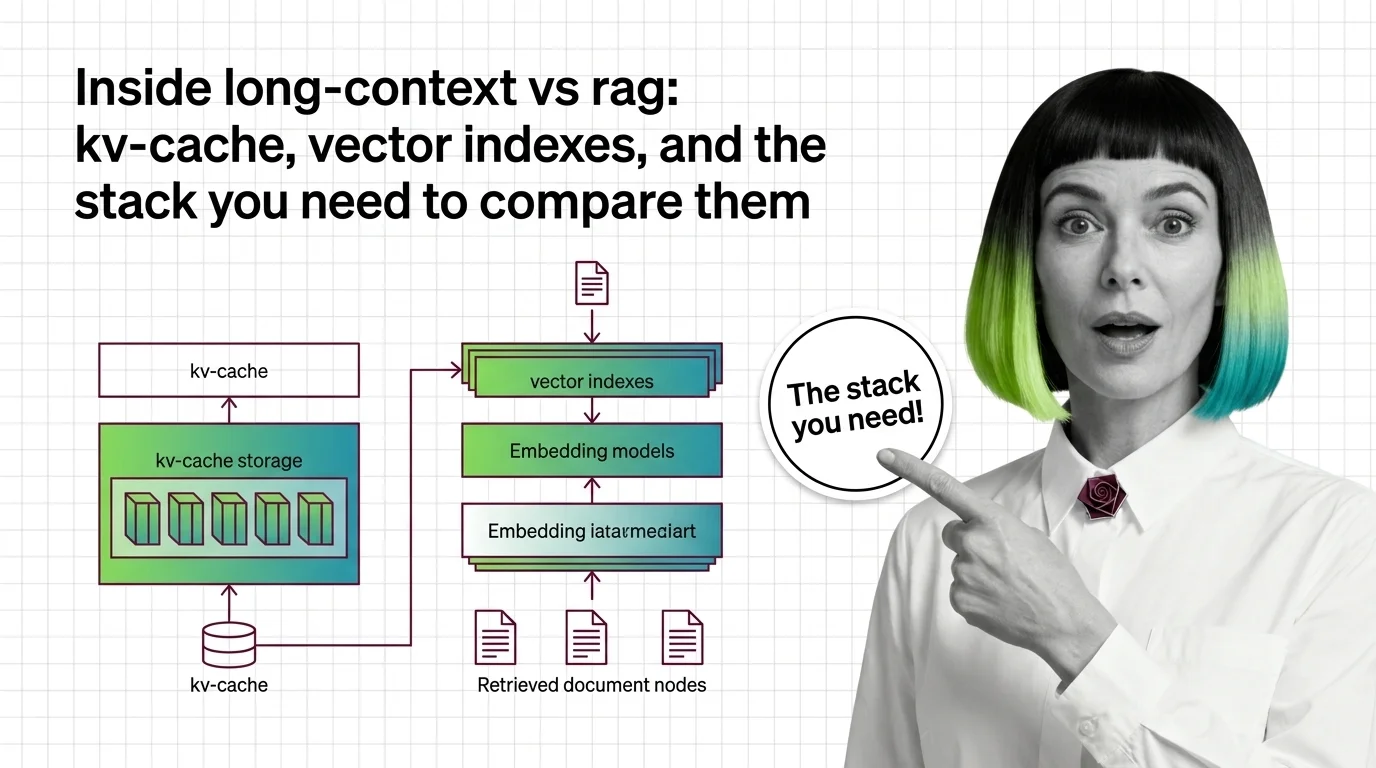
Inside Long-Context vs RAG: KV-Cache, Vector Indexes, and the Stack You Need to Compare Them
Long-context models and RAG pipelines compete for the same job with different parts. A component-by-component map of KV caches, vector indexes, and trade-offs.