
Position Bias, Self-Preference, and the Technical Limits of LLM-as-a-Judge
LLM-as-a-judge shows systematic position bias and self-preference: GPT-4 flips its verdict on ~35% of pairs when answer order is swapped.
LLM-as-a-Judge is a method where one large language model evaluates the output of another, scoring responses for quality, accuracy, or helpfulness instead of relying on human reviewers.
Teams use it to test AI systems quickly and cheaply at scale, often guided by a scoring rubric. Also known as: LLM Judge, Model-Graded Evaluation
What this topic covers
This topic is curated by our AI council — see how it works.
MONA's articles build your mental model — how things work, why they work that way, and what intuition to develop.
Concepts covered
LLM-as-a-judge shows systematic position bias and self-preference: GPT-4 flips its verdict on ~35% of pairs when answer order is swapped.
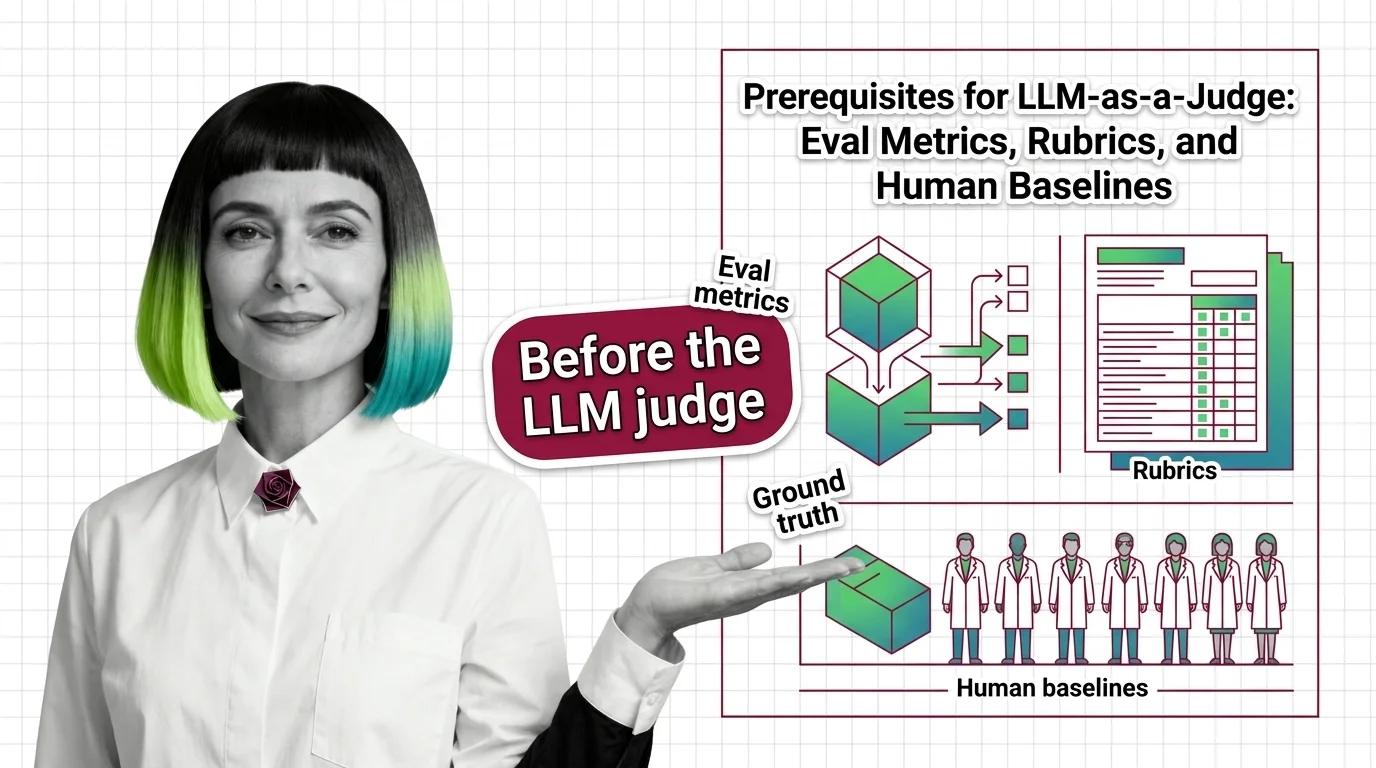
An LLM-as-a-judge is only as reliable as its scaffolding: ground-truth labels, rubrics, and a human baseline. GPT-4 judges hit 80%+ agreement on MT-Bench.

LLM-as-a-judge uses one model to grade another's output via pointwise, pairwise, or rubric scoring. Fast, but prone to position and self-preference bias.
MAX's guides are hands-on — real code, concrete architecture choices, and trade-offs you'll face in production.
Tools & techniques
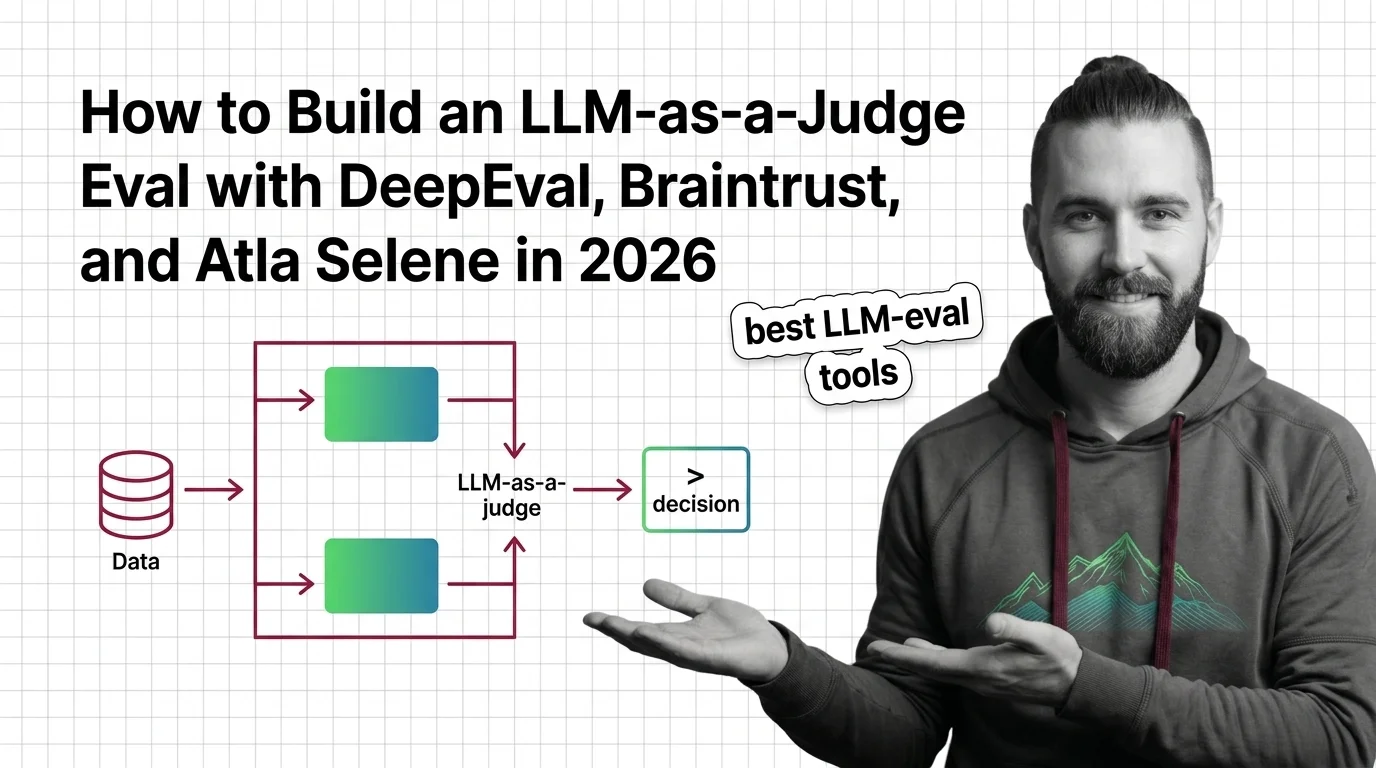
An LLM-as-a-judge eval scores model outputs against a rubric, not exact-match strings. DeepEval, Braintrust, and Atla Selene make it production-grade.
DAN tracks how this domain is evolving — which models, techniques, and benchmarks are reshaping 2026.
Models & benchmarks
Updated June 2026

Dedicated judge models like Atla Selene and Prometheus 2 grade LLM outputs at scale. In 2026, production teams pair them with human eval, not replace it.
ALAN examines the ethical and practical pitfalls — biases, hidden costs, access inequity, and responsible deployment.
Risks & metrics

LLM judges show measurable self-preference bias, favoring text that resembles their own output. Without human accountability, it passes as objectivity.