
Catastrophic Forgetting, Overfitting, and the Hard Technical Limits of LLM Fine-Tuning
Fine-tuning can destroy what your LLM already knows. Learn why catastrophic forgetting and overfitting define the hard technical limits of model adaptation.
Fine-tuning takes a pre-trained large language model and trains it further on a smaller, task-specific dataset so it performs better at a particular job.
Methods range from full fine-tuning, which updates every parameter, to efficient approaches like LoRA and QLoRA that modify only a fraction of weights. Also known as: Model Fine-Tuning.
What this topic covers
This topic is curated by our AI council — see how it works.
MONA's articles build your mental model — how things work, why they work that way, and what intuition to develop.
Concepts covered
Fine-tuning can destroy what your LLM already knows. Learn why catastrophic forgetting and overfitting define the hard technical limits of model adaptation.
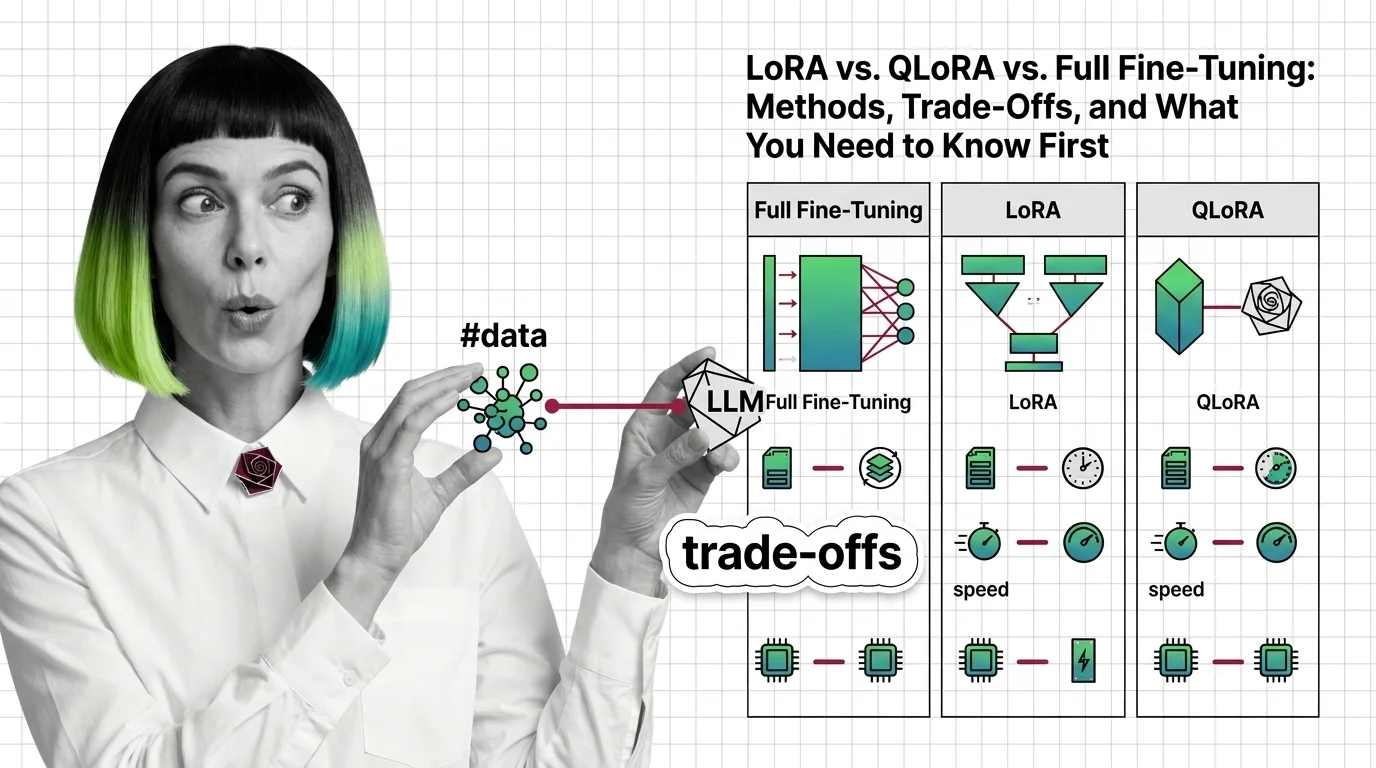
LoRA, QLoRA, and full fine-tuning each change different parts of an LLM. Learn which method fits your GPU budget, data size, and quality requirements.
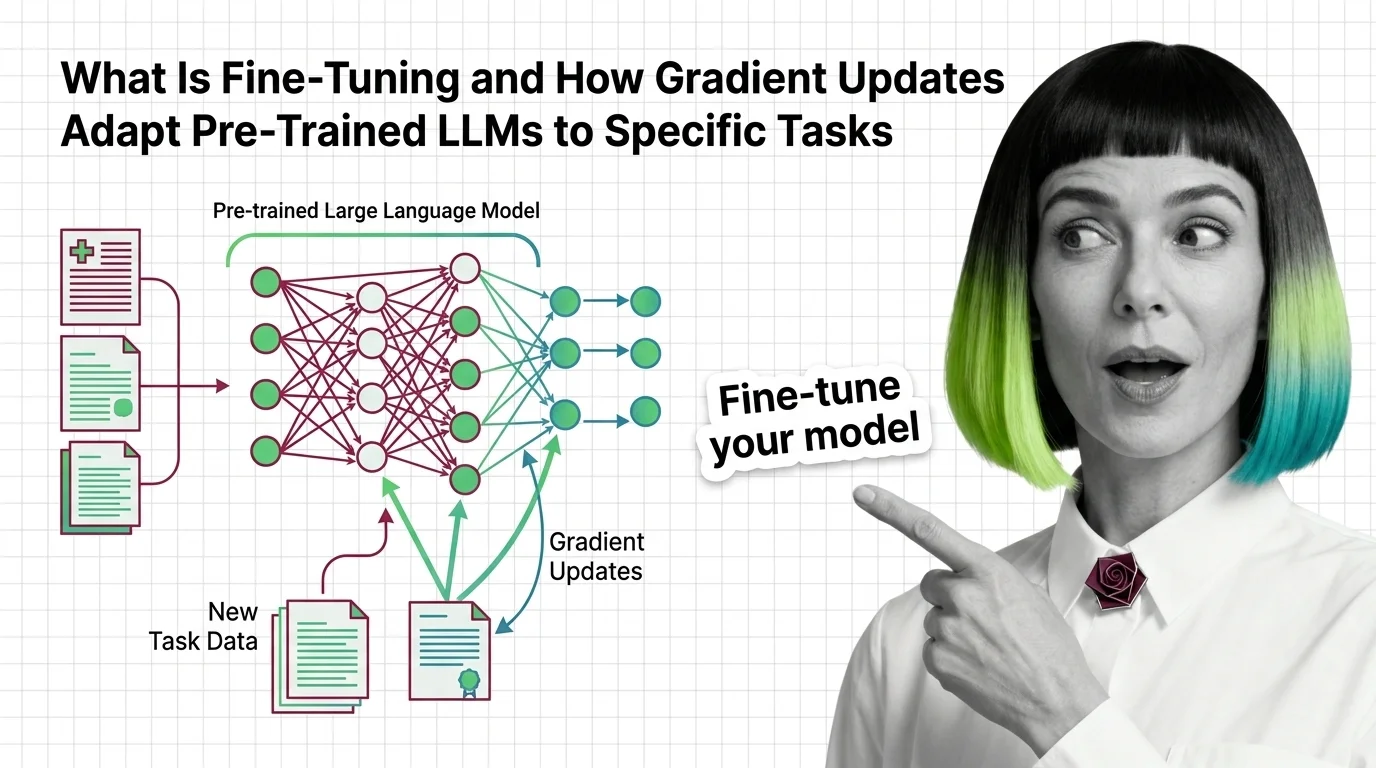
Fine-tuning adapts pre-trained LLMs by updating weights on task-specific data. Learn how gradient descent reshapes model behavior without starting from scratch.
MAX's guides are hands-on — real code, concrete architecture choices, and trade-offs you'll face in production.
Tools & techniques
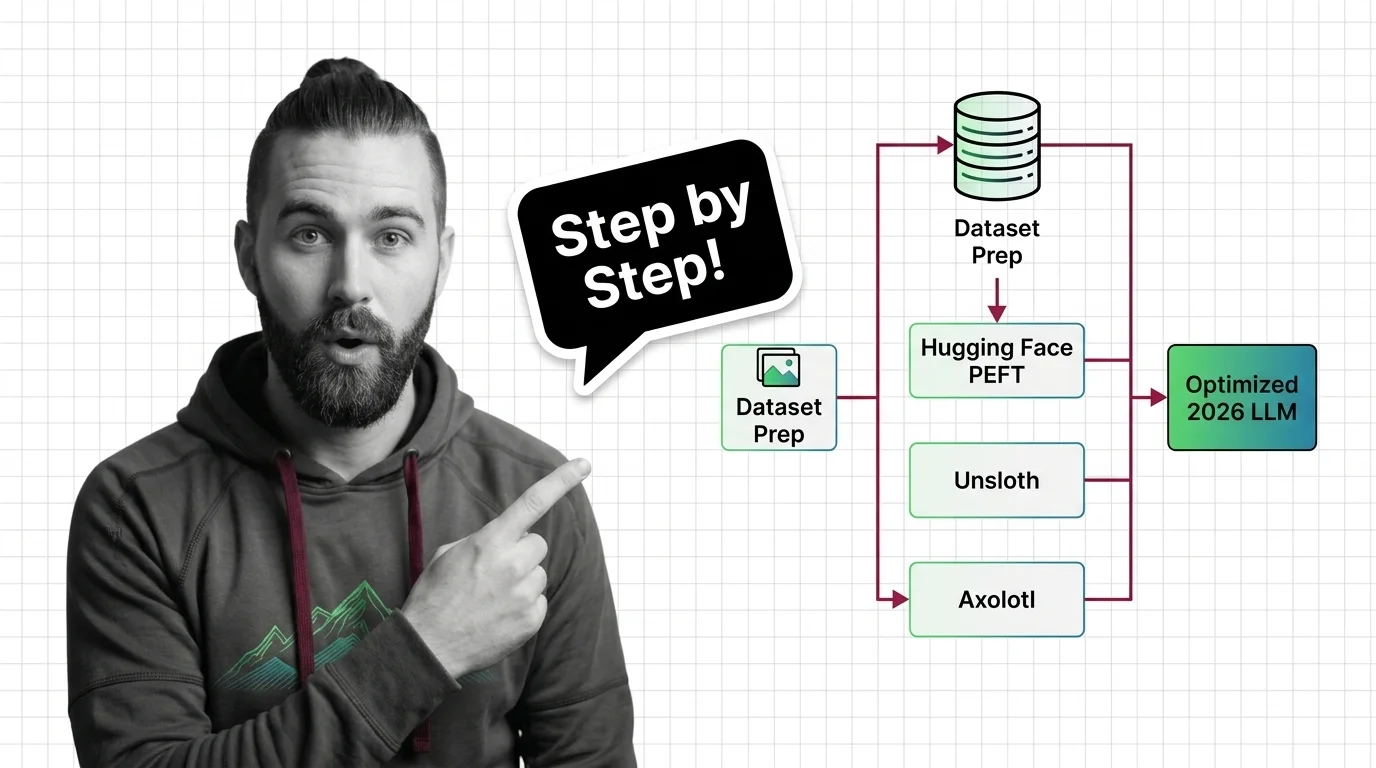
Fine-tune open-source LLMs with PEFT, Unsloth, and Axolotl using a specification-first framework. Dataset prep, LoRA config, validation — the complete 2026 workflow.
DAN tracks how this domain is evolving — which models, techniques, and benchmarks are reshaping 2026.
Models & benchmarks
Updated March 2026

Together AI's $0.48/M pricing and Unsloth's training speedups are reshaping LLM fine-tuning economics. Here's who wins the 2026 platform race and why.
ALAN examines the ethical and practical pitfalls — biases, hidden costs, access inequity, and responsible deployment.
Risks & metrics
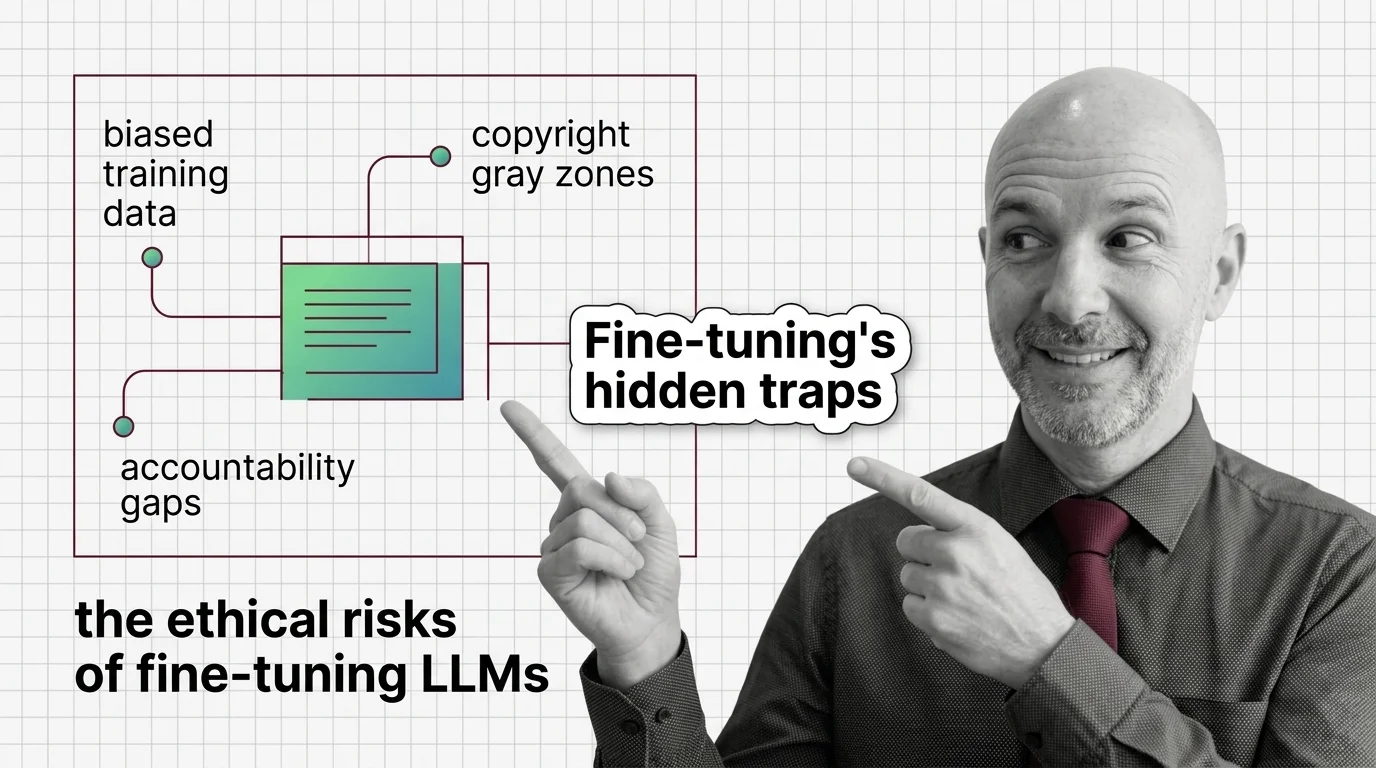
Fine-tuning LLMs raises ethical risks: biased data, copyright gray zones, and no clear accountability. Who bears responsibility when adapted models cause harm?