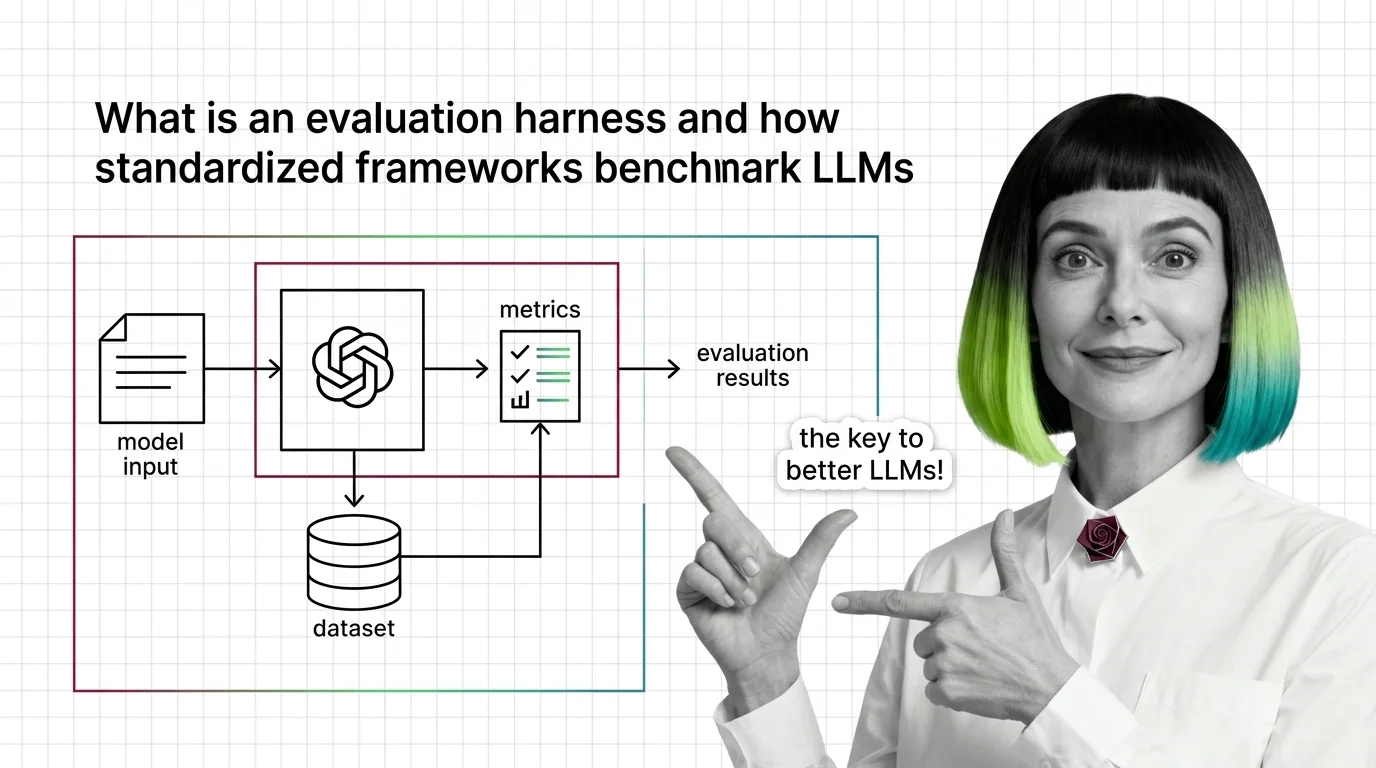
Evaluation Harness
An evaluation harness is a standardized software framework that runs language models through curated suites of benchmarks using reproducible methodology. Tools like lm-evaluation-harness, HELM, and OpenCompass automate test execution, scoring, and reporting, enabling researchers and engineers to make fair, apples-to-apples comparisons of model capabilities across tasks. Also known as: LM Eval Harness, Evaluation Framework, HELM.
Understand the Fundamentals
Evaluation harnesses turn subjective model impressions into quantifiable evidence. Understanding how these frameworks standardize testing reveals both the power and the hidden assumptions behind every leaderboard score.

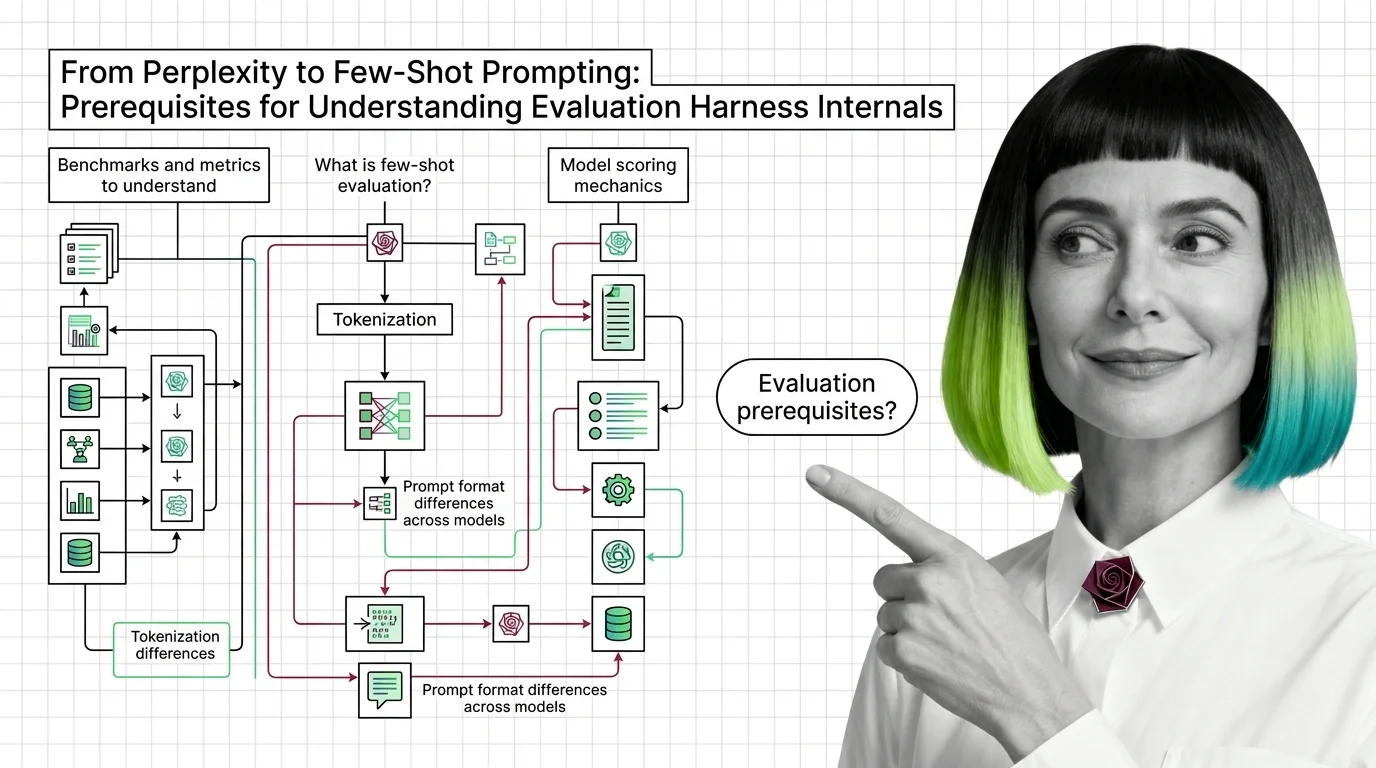
Build with Evaluation Harness
These guides walk through setting up harnesses, configuring benchmark suites, and interpreting results so you can make informed model selection decisions for real workloads.

What's Changing in 2026
The evaluation landscape is shifting fast as new open-source harnesses challenge established frameworks. Staying current means knowing which tools set the standard for credible benchmarking.
Updated April 2026
Risks and Considerations
Standardized evaluation can create false confidence when benchmark selection is narrow or contamination goes undetected. Consider who chooses the tests and what they leave unmeasured.
