Encoder-Decoder Architecture
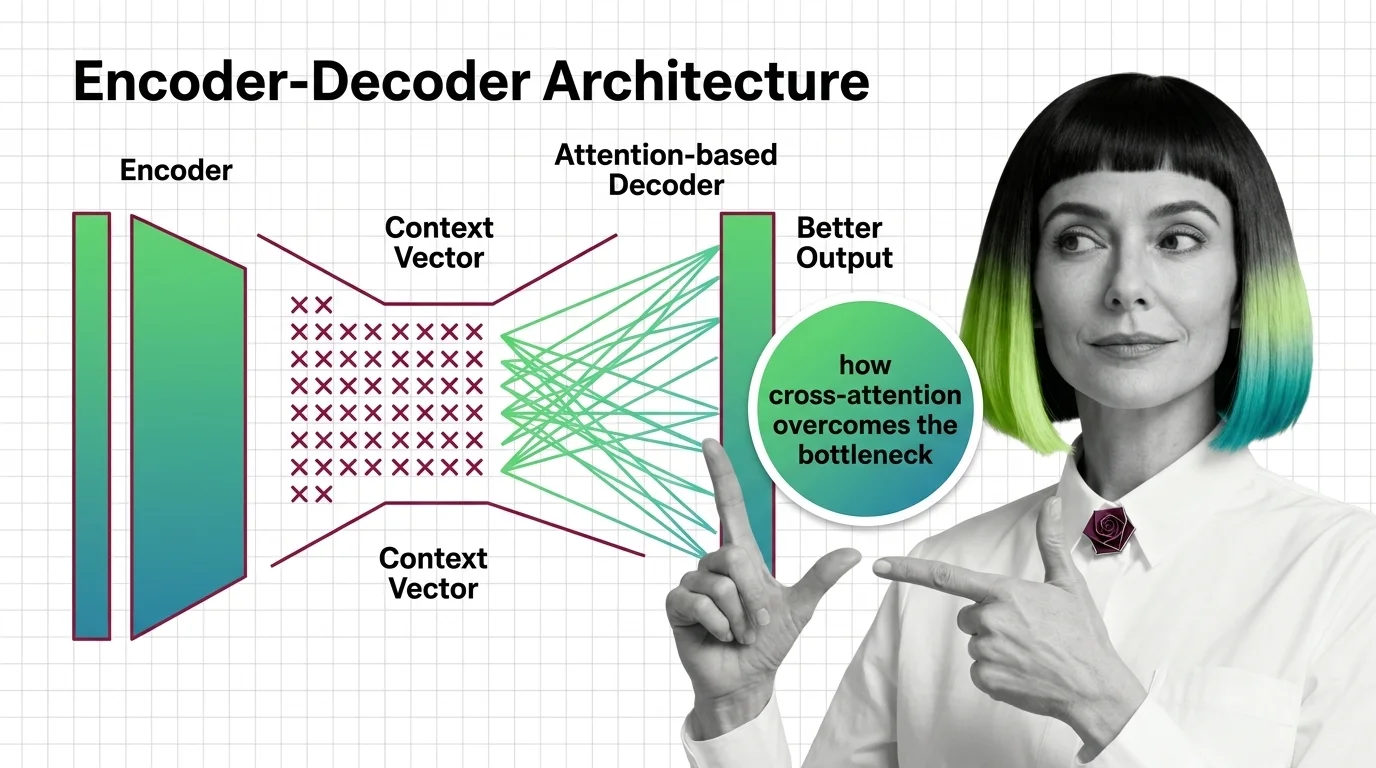
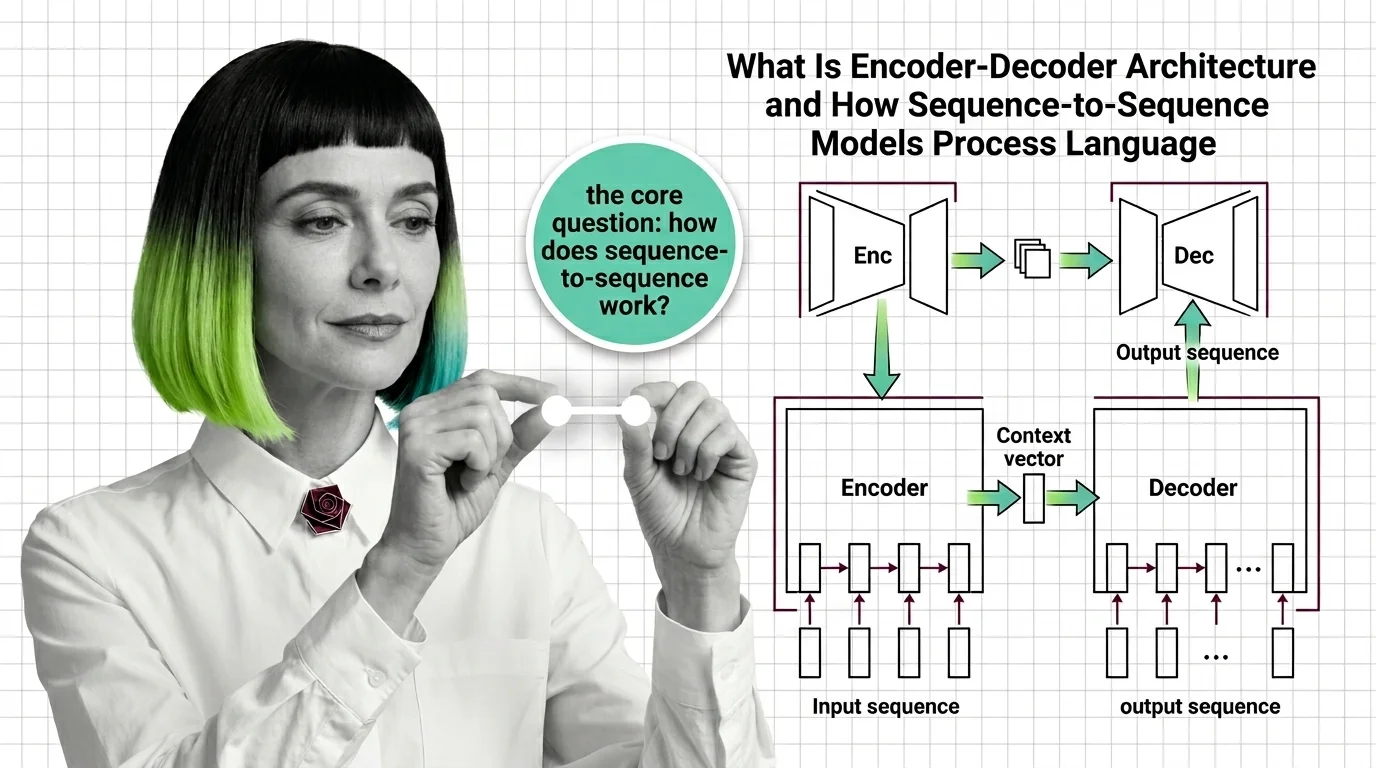
Encoder-decoder architecture is a neural network design pattern where an encoder network compresses an input sequence into a dense internal representation, and a decoder network generates an output sequence from that representation. Originally developed for machine translation, this pattern powers models like T5, BART, and Whisper across tasks including summarization, speech recognition, and question answering. Cross-attention between the two components allows the decoder to selectively focus on relevant parts of the input. Also known as: Seq2Seq, Sequence-to-Sequence.
Understand the Fundamentals
Encoder-decoder architecture splits language processing into compression and generation, a division that enables the model to transform one sequence into another while preserving meaning across radically different structures.
Build with Encoder-Decoder Architecture
The guides here walk through choosing between encoder-decoder and decoder-only designs, covering the practical trade-offs in latency, memory, and task-specific accuracy that shape real deployment decisions.
What's Changing in 2026
Encoder-decoder models are staging a quiet comeback as specialized tasks demand architectures that decoder-only scaling alone cannot efficiently solve. Knowing where the field is heading keeps your stack relevant.
Updated March 2026
Risks and Considerations
When encoder-decoder systems handle translation or summarization at scale, they can silently amplify biases, erase minority dialects, and concentrate linguistic power in ways that demand careful oversight.
