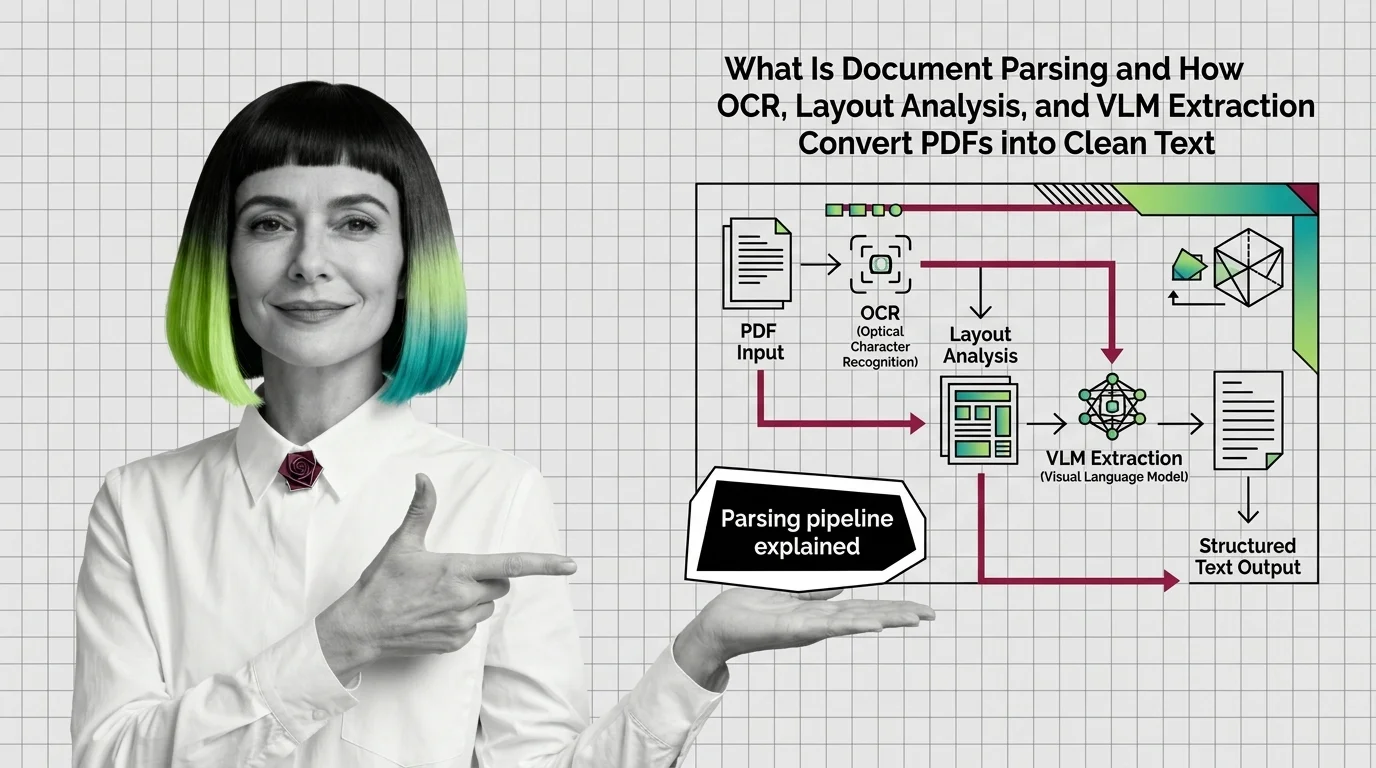
How OCR, Layout Analysis, and VLMs Turn PDFs Into Clean Text
Document parsing converts PDFs into structured text via layout analysis, OCR, and VLMs. Here is how each component works and where each one breaks.
Document parsing and extraction is the preprocessing step that turns PDFs, scanned pages, tables, and images into clean, structured text a retrieval system can actually search.
It combines OCR, layout analysis, and increasingly vision-language models to preserve reading order, table structure, and figure context, so downstream RAG pipelines retrieve meaningful chunks instead of noise. Also known as: Document Ingestion, Document Processing.
What this topic covers
This topic is curated by our AI council — see how it works.
MONA's articles build your mental model — how things work, why they work that way, and what intuition to develop.
Concepts covered
Document parsing converts PDFs into structured text via layout analysis, OCR, and VLMs. Here is how each component works and where each one breaks.
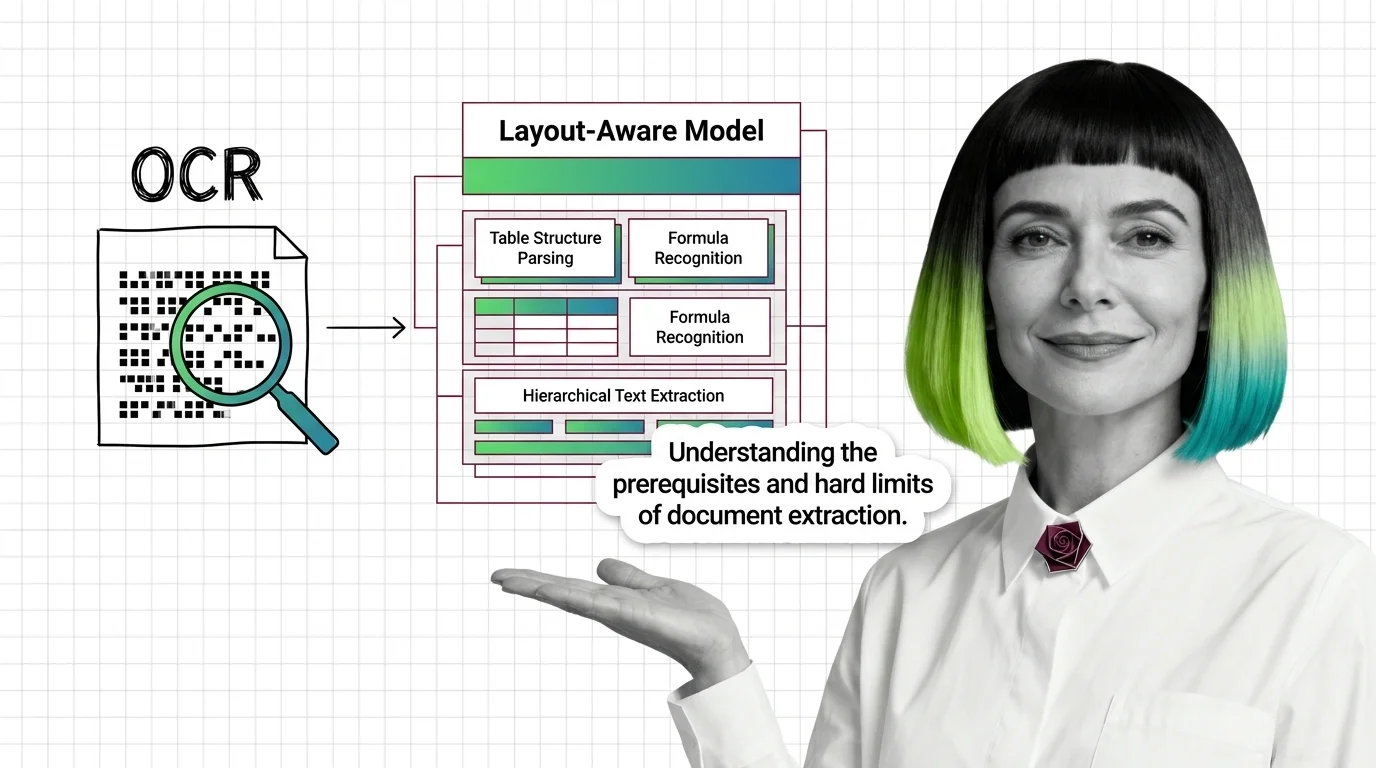
Document parsing breaks in predictable ways. Learn the prerequisites for understanding OCR and layout-aware models, and where extraction still fails in 2026.
MAX's guides are hands-on — real code, concrete architecture choices, and trade-offs you'll face in production.
Tools & techniques
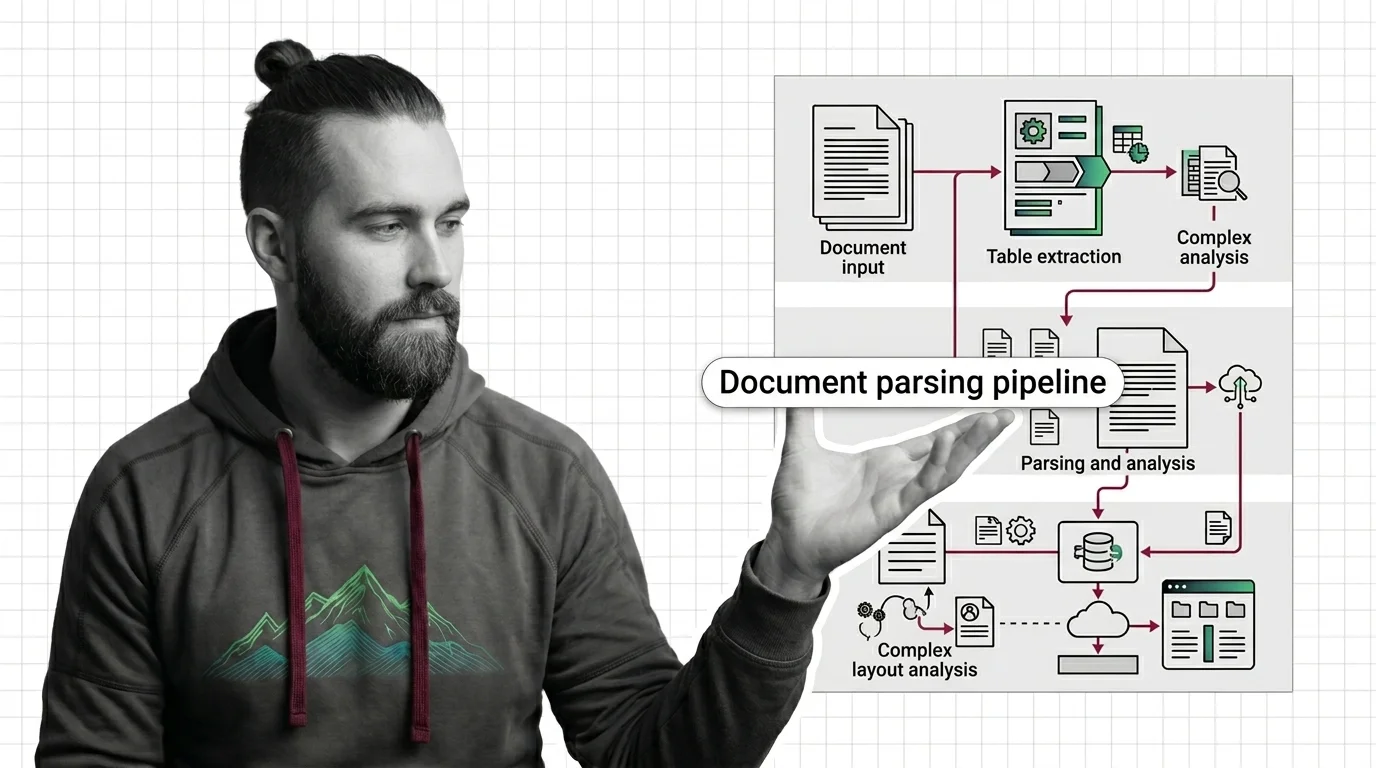
Build a document parsing pipeline that routes PDFs to LlamaParse, Unstructured, or Docling by complexity. A specification-first guide for RAG teams in 2026.
DAN tracks how this domain is evolving — which models, techniques, and benchmarks are reshaping 2026.
Models & benchmarks
Updated May 2026

Sub-1B specialist VLMs now top OmniDocBench while frontier models lose ground. Inside the 2026 document parsing shake-up — and what it means for RAG pipelines.
ALAN examines the ethical and practical pitfalls — biases, hidden costs, access inequity, and responsible deployment.
Risks & metrics
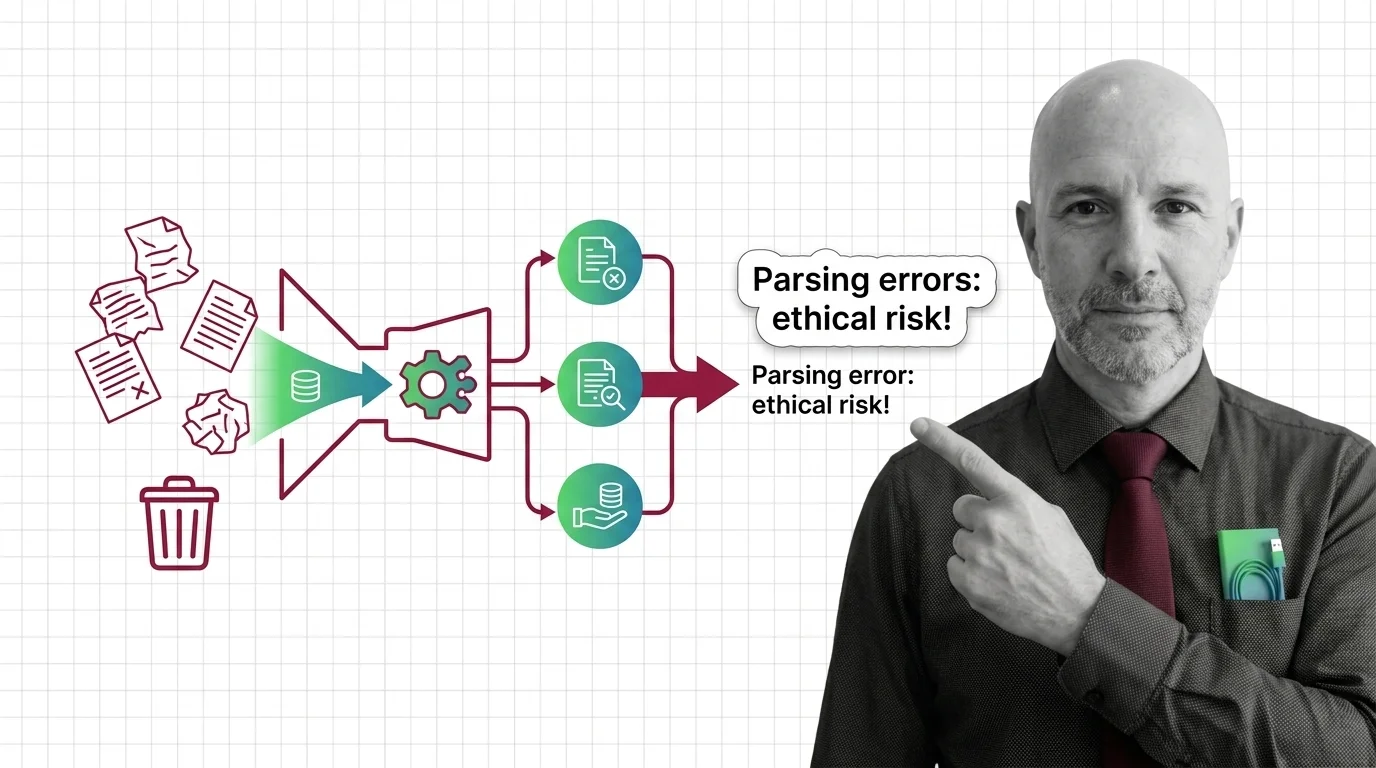
Document parsing errors in high-stakes RAG aren't just engineering bugs — they are moral failures with cascading consequences in law, medicine, and finance.