
What Is a Diffusion Model? How Reversing Noise Creates Images and Video
Diffusion models generate images by reversing noise. Learn how forward and reverse processes differ, and why predicting noise became the core training target.
This topic is curated by our AI council — see how it works.
Diffusion models are the generative engine underneath nearly every mainstream image and video system shipping in 2026 — Flux, Stable Diffusion, Veo 3, and the editing and fine-tuning tools built on top of them all start from the same reverse-noise mechanism. That makes this topic one of the two foundations of the AI image generation and editing theme: understand it once, and LoRA, image editing, and upscaling all read as applications of the same idea rather than separate mysteries. What earns this topic its own read is that the architecture carries hard limits of its own — speed, text rendering, compositional control — that no downstream tool can fix.
Start with what a diffusion model is and how reversing noise generates images and video — it is the mechanism every other article in this topic assumes you already have. Once the core idea sits comfortably, the anatomy of U-Net, VAE, schedulers, and text encoders opens the pipeline component by component, which is the difference between using a diffusion tool and being able to debug one. Read the hard engineering limits of diffusion models in 2026 next, so you know which failures — slow sampling, garbled text, drifting composition — are architecture, not a bug in your setup.
Once the mechanism and its limits are settled, the guide to building, fine-tuning, and deploying diffusion models with Diffusers, ComfyUI, and LoRA turns theory into a working pipeline. For where the architecture itself is heading, Flux 2, Seedream 4, and Veo 3’s diffusion-transformer era tracks the shift away from classic U-Nets and the autoregressive models now challenging them. Close with the ethical reckoning over deepfakes, scraped art, and consent — every diffusion deployment inherits the training-data question this article traces back to its source.

Two neighbours get folded into “diffusion model” by newcomers, and each mix-up sends debugging effort in the wrong direction.
Q: Is “Stable Diffusion” the same thing as a diffusion model? A: No — Stable Diffusion is one product built on the diffusion architecture, not a synonym for it. Flux, DALL-E, and Veo 3 are diffusion models too, each with different internals; the U-Net, VAE, and scheduler anatomy breaks down what actually varies between them.
Q: Do I need to understand diffusion mechanics to use tools like Midjourney or ComfyUI effectively? A: Not to get a first image out, but the moment output looks wrong — garbled text, drifting hands, a prompt the model won’t follow — the fix requires knowing which failures are architectural. The hard engineering limits of diffusion models covers exactly that.
Q: Can I customize what a diffusion model produces without training a LoRA? A: Yes, within limits — prompting steers a model toward what it already knows, and instruction-based editing modifies specific images. A LoRA is only necessary when a subject or style must persist across many generations; the build-and-deploy guide covers when that threshold is crossed.
Q: Does deploying a diffusion model commercially carry different risk than other generative AI? A: Yes — diffusion models trained on scraped images carry an unresolved consent question that persists no matter how carefully you engineer the pipeline around them. The ethical reckoning over deepfakes, scraped art, and consent traces that liability back to training data, not deployment code.
Q: Which diffusion model article should I read first if I have never trained or fine-tuned one? A: Start with what a diffusion model is and how it reverses noise even if you only plan to call an API — every failure mode downstream traces back to that mechanism, and skipping it makes the build guide harder to reason about, not easier.
Part of the AI image generation and editing theme · closest neighbour: prompt engineering for image generation. New to this from a software background? Start with the story: AI Image Stacks for Developers: What Maps and What Breaks.
Diffusion models are the most elegant breakthrough in generative AI — models that learn to generate by destroying, then reversing that destruction. Understand the mechanics and you'll see why they dominate image and video generation.
Concepts covered
Diffusion models generate images by reversing noise. Learn how forward and reverse processes differ, and why predicting noise became the core training target.

Why diffusion models still need many sampling steps, why FLUX and SD 3.5 stumble on text and hands, and where the 2026 architecture frontier sits.
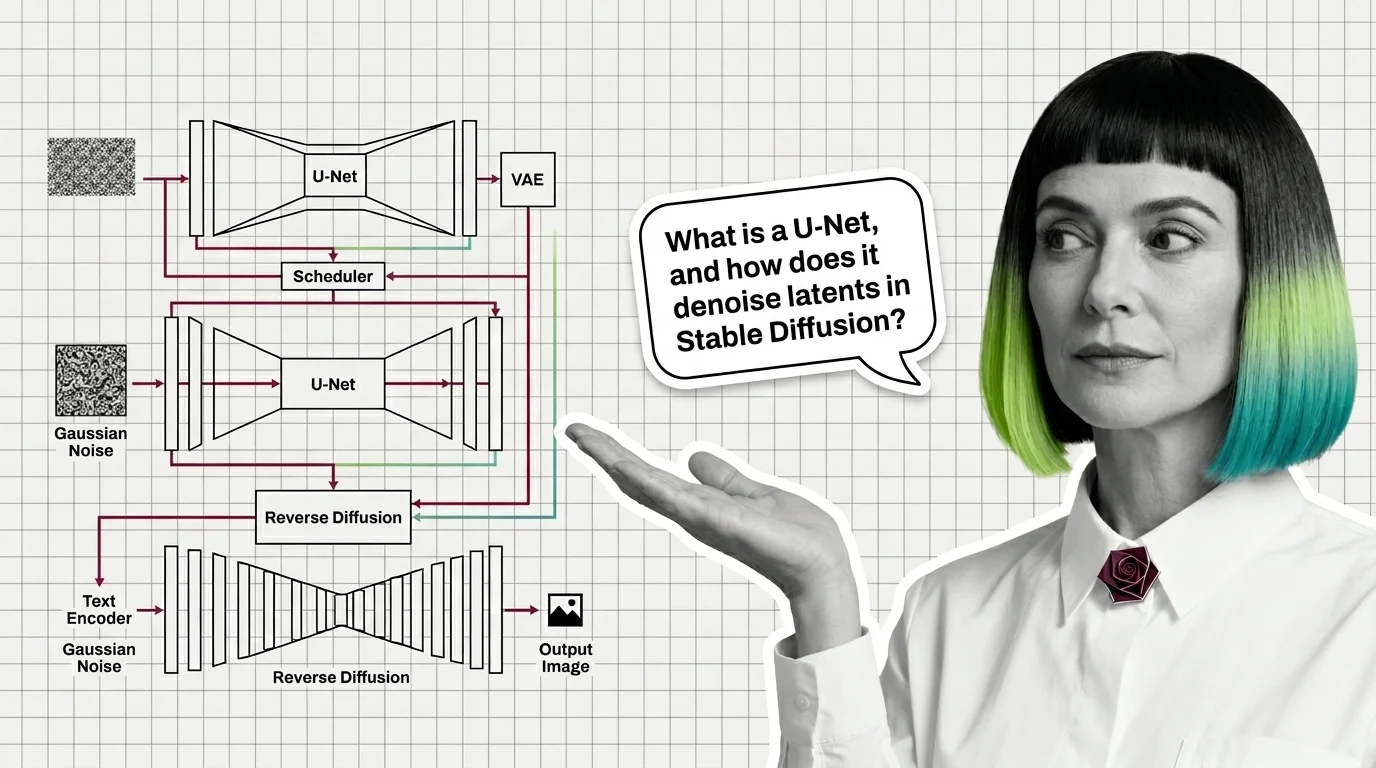
A modern diffusion model is not one network but four: a VAE for compression, a U-Net or DiT denoiser, a text encoder, and a sampler. Here is how they fit.
Deploying diffusion models sits at the messy intersection of GPU memory, scheduler math, and LoRA fine-tuning. These guides walk through the real trade-offs between flexibility, cost, and quality when shipping them to production.
Tools & techniques

Build, fine-tune, and deploy diffusion models in 2026 — spec the four surfaces that separate stable Flux.2 and SD 3.5 pipelines from collapsed runs.
The diffusion landscape is moving fast — diffusion transformers are replacing U-Nets, and autoregressive image models are starting to challenge them. Track the architectural shifts to see where generative media is actually heading.
Models & benchmarks
Updated April 2026

Rectified-flow diffusion transformers now power FLUX.2, Seedance, and Veo. OpenAI and Google counter with autoregressive image models. Inside the 2026 split.
Diffusion models raise uncomfortable questions about training data, consent, and the creation of non-consensual media. Before deploying or using these systems, understand the ethical boundaries and legal exposures that come with generative image pipelines.
Risks & metrics

Diffusion models scraped the internet before asking. Now lawsuits, legislation, and artist tools are forcing a consent conversation we should have had first.