Every later stage of a machine learning pipeline inherits whatever preprocessing decided to keep, rescale, or discard — a column scaled on the wrong slice of data doesn’t throw an error, it just quietly caps how well the model downstream can learn. That is why preprocessing anchors the training data quality and curation theme as one of its two foundational layers, and why the order you do things in matters as much as the transforms themselves.
Split before you transform: fitting a scaler or encoder on the full dataset before separating train and test data leaks test information into training and inflates the accuracy score you trust.
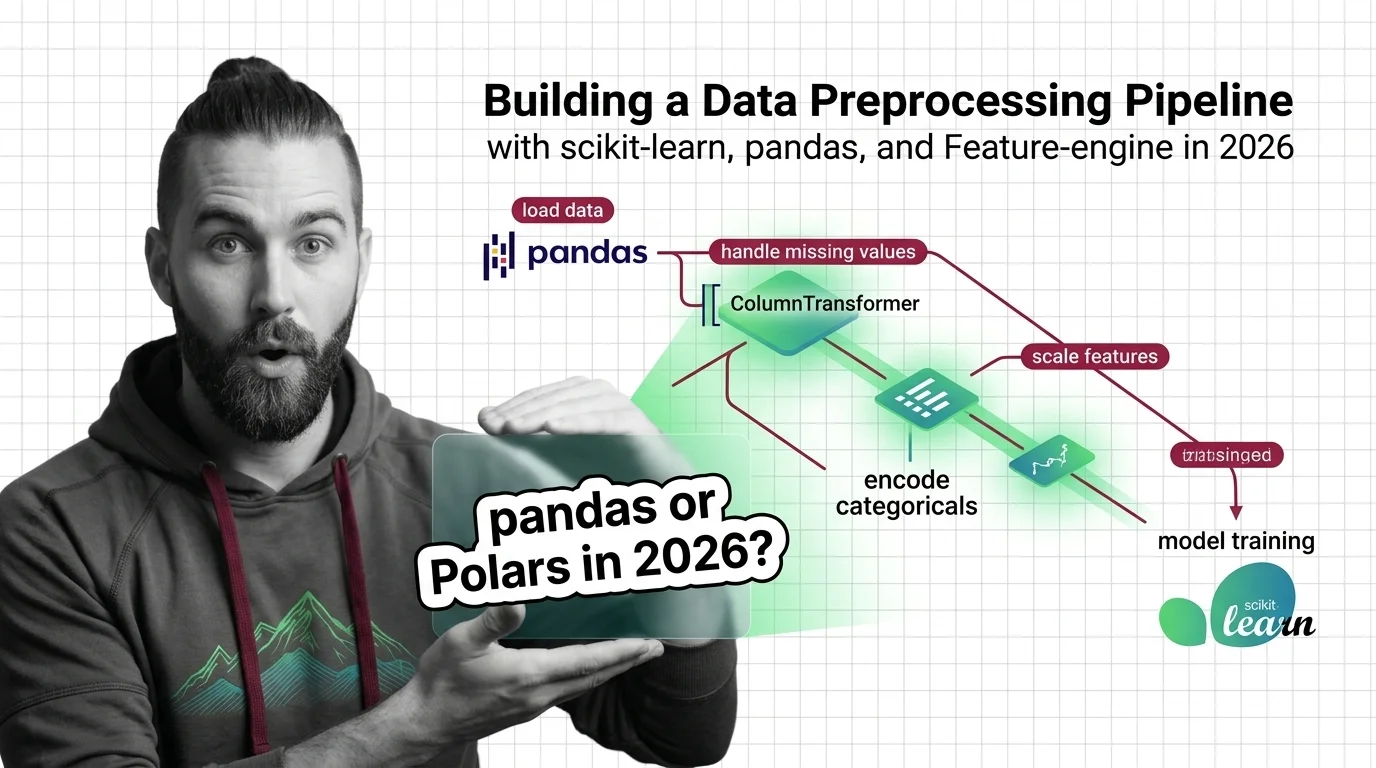
Numeric and categorical columns need separate treatment — scaling one, encoding the other — routed through their own branch of a single pipeline object, not one undifferentiated block.
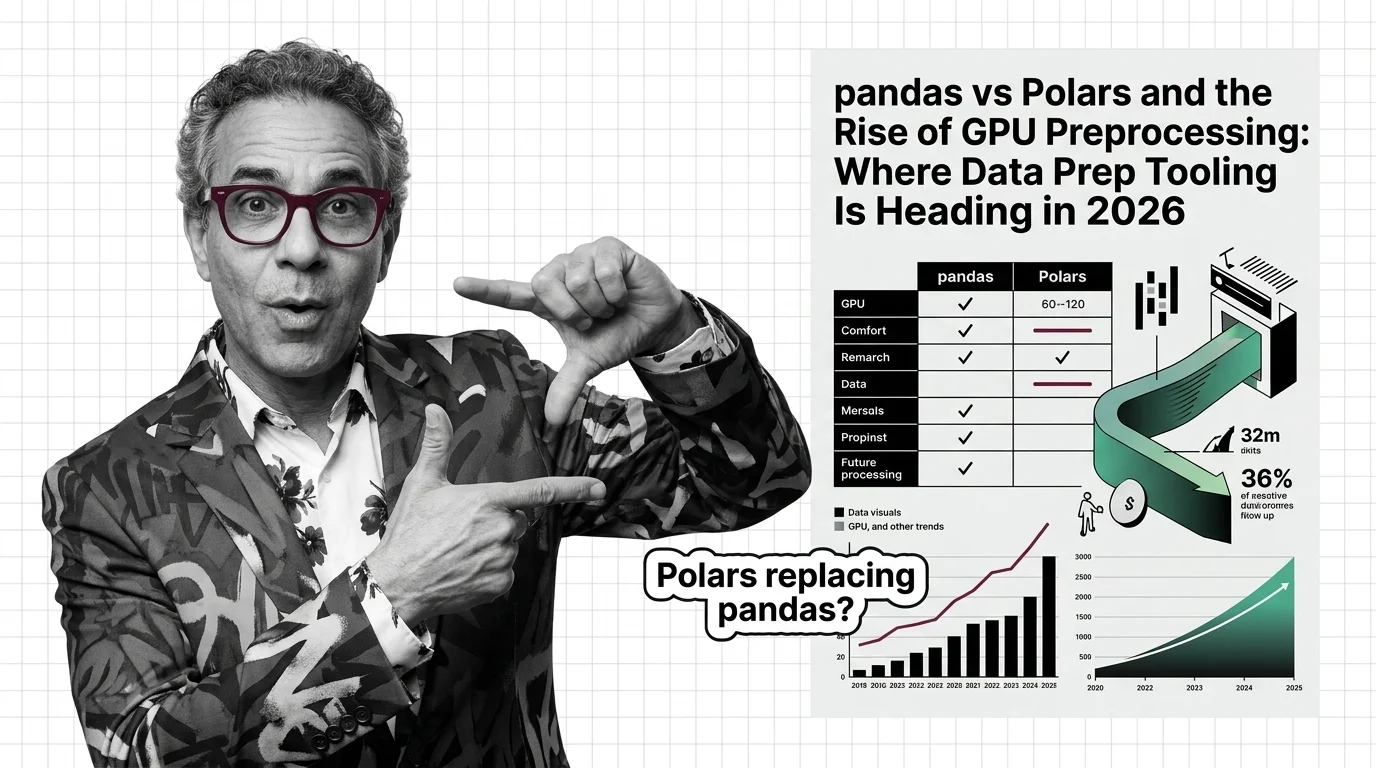
The tooling question is largely settled: pandas, Polars, and GPU engines now interoperate through the Apache Arrow format, so the framework you pick matters less than whether the pipeline is leakage-safe.
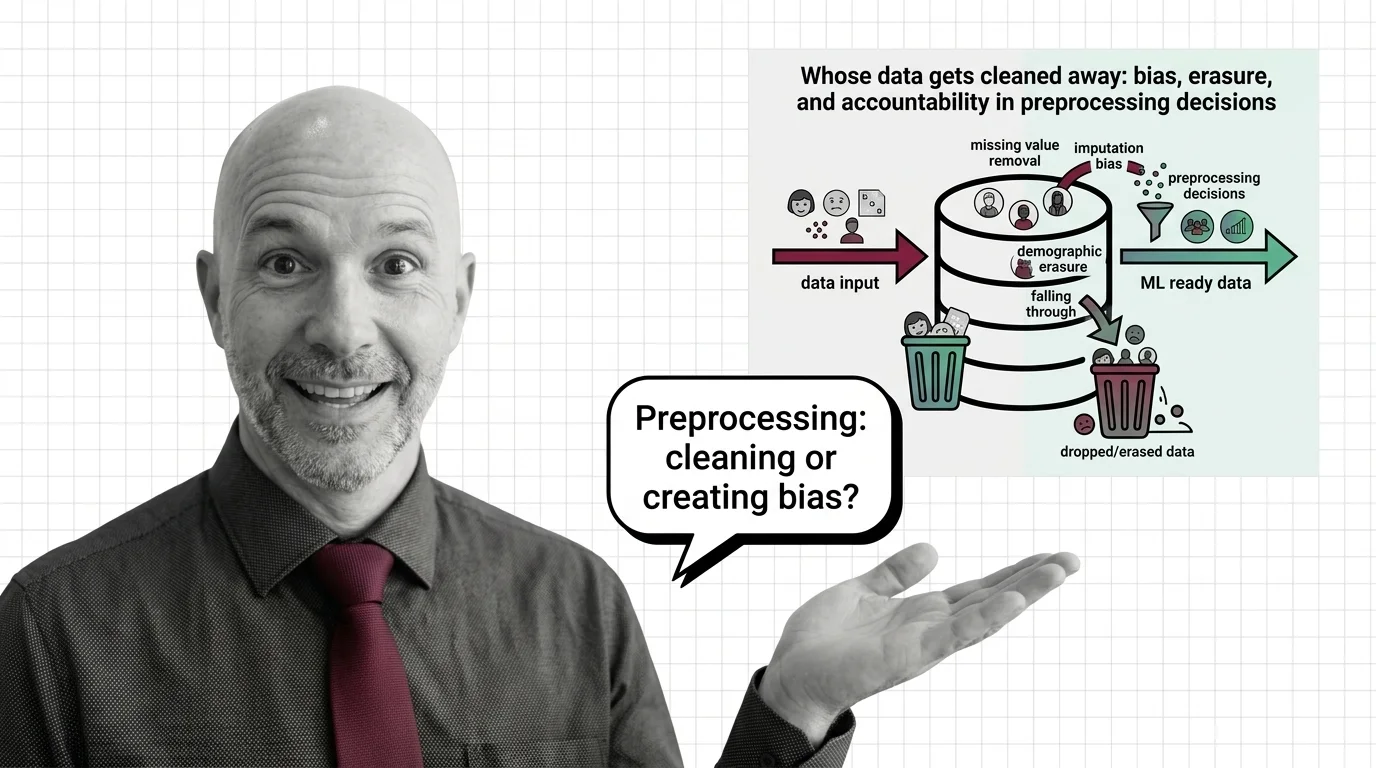
Every rule for what counts as “dirty” data is also a judgment about whose records get dropped — that decision deserves as much scrutiny as the transform itself.
Reading this topic in the order that prevents leakage
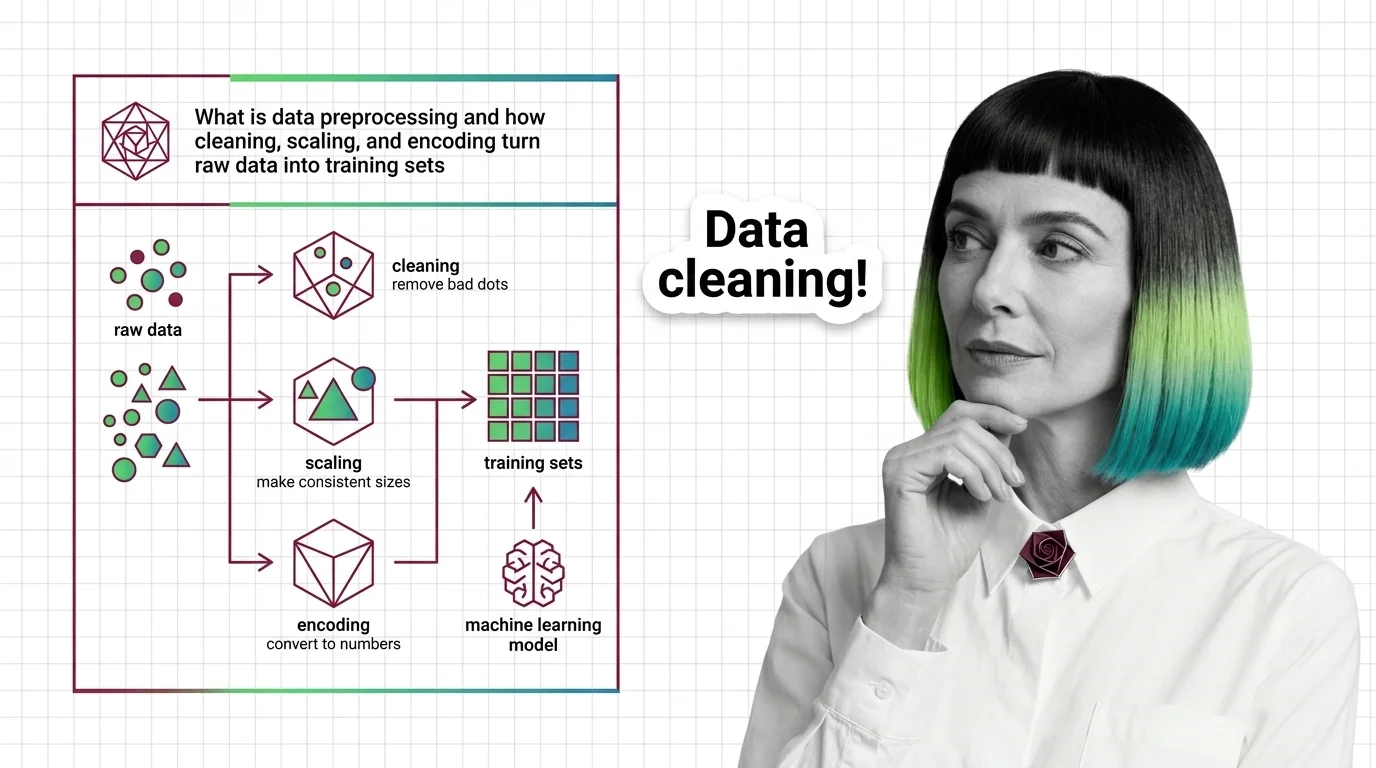
Start with how cleaning, scaling, and encoding turn raw data into training sets for the vocabulary the rest of this topic assumes — cleaning, scaling, and encoding are three separate jobs, and most of the confusion below starts from treating them as one. Read before you preprocess in the same sitting: it settles the type, distribution, and train-test split questions you must answer before any transform runs, because getting the split order wrong is the most common way a pipeline quietly breaks a model.
A pipeline can run without a single error and still be leaking information.
How preprocessing differs from augmenting and deduplicating data
Two neighbouring practices get folded into “preprocessing” when they are really pointed in different directions.
Preprocessing does not add anything to a dataset — it reshapes the values already there so a model can consume them, without changing what any example means. Data augmentation does the opposite: it deliberately creates new, altered examples from existing ones to grow the dataset. Confusing the two leads teams to expect a scaling step to fix a data-scarcity problem it was never built to solve.
Deduplication runs on a different scope entirely. Data deduplication removes repeated or near-repeated records from the raw corpus before any single pipeline sees it; preprocessing then transforms whatever records survive that pass. Running deduplication after preprocessing, on already-scaled and encoded data, means re-deriving the raw text or values dedup actually needs to compare — the order is not interchangeable.
Common questions about data preprocessing
Q: Why does a preprocessing pipeline that passes every test still produce a model that underperforms in production?
A: The usual cause is leakage introduced before testing ever runs — a scaler or encoder fit on the full dataset rather than just the training split, so test-set statistics quietly shaped the training data. Data leakage and the technical limits of preprocessing pipelines traces exactly where that mistake enters.
Q: Is it worth adding unseen-category handling to an encoder that already works in testing?
A: Yes — production data eventually contains a category the training set never had, and an encoder without an explicit rule for it will error or silently corrupt the row. The scikit-learn, pandas, and Feature-engine pipeline guide sets that handling as a default part of the spec, not an edge case.
Q: Does moving from pandas to Polars mean rewriting an existing preprocessing pipeline?
A: Increasingly, no — data-prep tooling is consolidating on the Apache Arrow columnar format, so pandas, Polars, and GPU engines move data between each other with less friction than a full rewrite implies. The pandas vs Polars tooling read covers what is converging and what still is not.
Q: Is dropping rows with missing or messy values a purely technical decision?
A: Not entirely — every rule for what counts as bad data also decides whose records get kept, and that judgment is rarely written down or reviewed. Whose data gets cleaned away follows that accountability gap into a real pipeline.
Data preprocessing sits between raw data and a working model, and much of its impact stays invisible. Understanding what each transformation actually does to your data separates a reliable pipeline from a fragile one.
Data preprocessing cleans, scales, and encodes raw data into model-ready features. Fitting transformers before the train-test split causes data leakage.
Split data into train and test sets before preprocessing to prevent data leakage. Fitting scalers on the full dataset inflates accuracy and fails in production.
Data leakage occurs when information unavailable at prediction time enters training, inflating validation accuracy while production performance collapses.
2
Build with Data Preprocessing
These guides walk through assembling a preprocessing pipeline you can maintain—where to clean, how to scale and encode, and which trade-offs keep the same transformations consistent between training and production.
scikit-learn pipelines stop data leakage by fitting transformers on training data only. ColumnTransformer routes numeric and categorical columns separately.
3
What's Changing in 2026
Preprocessing tooling is shifting quickly, and the choices you make today shape how well your pipelines scale tomorrow. Staying current on what is gaining ground helps you avoid betting on the wrong stack.
Data-prep tooling consolidates on Apache Arrow in 2026: pandas 3.0, Polars, and RAPIDS cuDF interoperate zero-copy. Leakage-safe pipelines are now default.
4
Risks and Considerations
Every preprocessing decision quietly keeps some data and discards the rest, and those choices carry consequences. Before you clean, it is worth asking whose data gets erased and who stays accountable for the result.