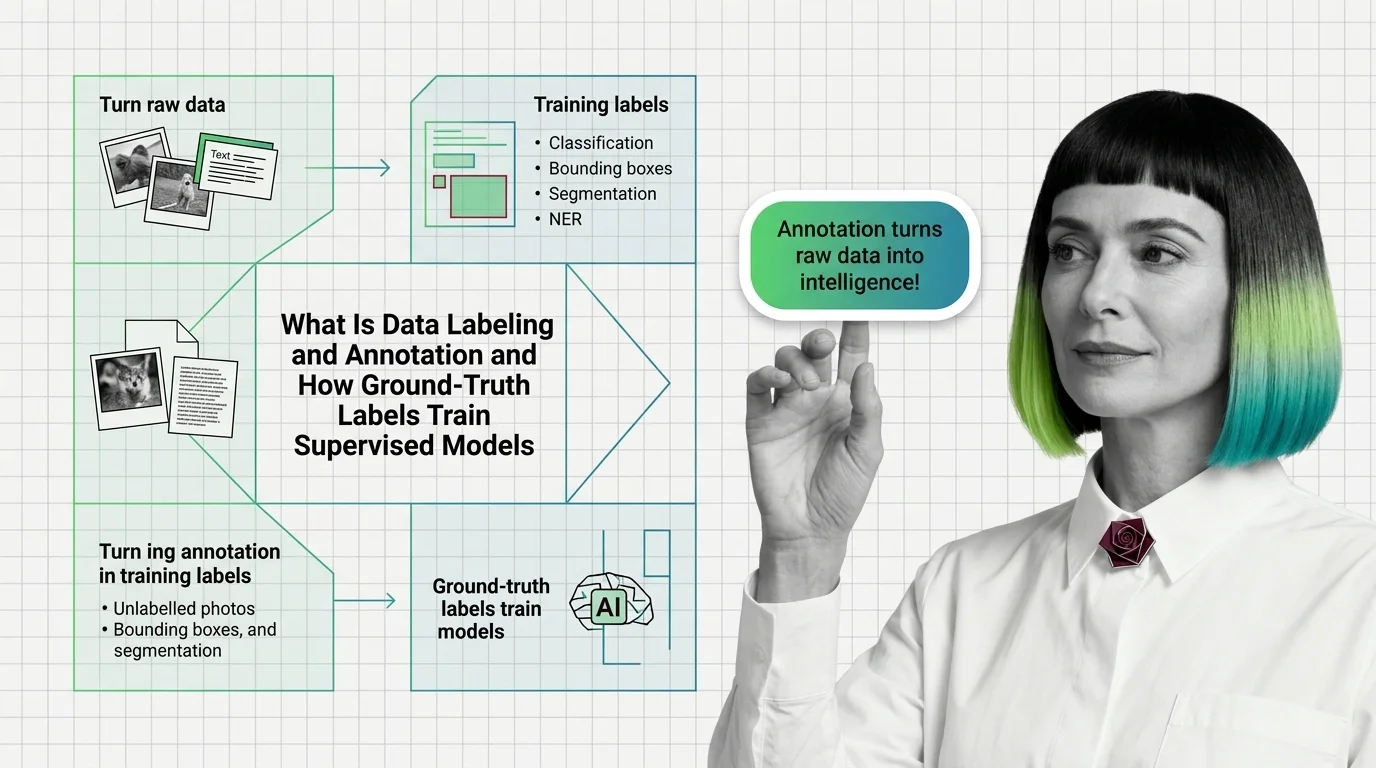
What Is Data Labeling and Annotation, and How Ground-Truth Labels Train Supervised Models
Data labeling assigns ground-truth labels to raw data so supervised models learn a mapping. Label noise propagates into model errors geometrically.
This topic is curated by our AI council — see how it works.
Every supervised model’s ceiling is set by the answer key it was trained on, and that answer key is data labeling and annotation — one human judgment at a time, usually the single largest line item in a machine learning project’s budget. Inside training data quality and curation, labeling is the lever that adds ground truth rather than reshaping or trimming what already exists, which is why its failures are the hardest to see: a labeling mistake does not throw an error, it just teaches the model something false with total confidence.
Start with how ground-truth labels train supervised models — it explains what a label actually is and why the model treats it as truth it never questions. Read inter-annotator agreement and the building blocks of a labeling project next: it is the instrumentation that tells you whether your annotators are actually agreeing or just each guessing the same wrong way. Then label noise, annotator bias, and the technical limits of human annotation names the two failure modes those metrics cannot fully catch on their own.
Once the concepts are in place, the Label Studio, Labelbox, and active-learning pipeline guide turns them into a working system with a sampler, an interface, and a quality layer. For the market context behind that tooling choice, the Scale AI–Meta deal and the rise of programmatic labeling explains why the labeling industry suddenly looks like an infrastructure fight, not a back-office cost. Close with the ethical cost of the data labeling industry — the guidelines and tooling above are built on labor whose conditions this topic does not let you ignore.

Three practices get folded into “labeling” that are actually separate jobs, each owned by a different topic.
Labeling and training data quality sound like the same discipline but run in opposite directions: labeling creates the ground truth, while training data quality is the later audit that catches label errors, noise, and bias after they already exist in the dataset. A project can pass every inter-annotator-agreement check and still fail a quality audit months later, because agreement measures whether annotators agree with each other, not whether they are right.
Labeling and active learning are not competing options — active learning is a targeting layer that sits in front of labeling, deciding which examples reach an annotator at all. Treating them as alternatives (“should we label, or should we do active learning”) misreads the relationship: a mature pipeline runs active learning to select, then labeling to execute, on the same examples.
Labeling and data preprocessing differ in what they touch: preprocessing reshapes formats, scales, and encodings so a model can consume the data at all, while labeling attaches the semantic ground truth the model is supposed to learn. The practical question this raises — clean first or label first — has no universal answer, but skipping deduplication and basic cleaning before a labeling pass wastes annotator time on records that get dropped later anyway.
Q: How do I know if my labeled dataset already has too much label noise to trust? A: Raw disagreement rates are the first signal, but they undercount subtler noise; run a systematic audit rather than spot-checking a sample. The technical limits of human annotation explains why noise stays invisible until you specifically measure for it.
Q: Should I build an in-house annotation team or use a third-party labeling vendor? A: It depends on how sensitive your data is and how concentrated you want your supply chain to be — the market disruption after Scale AI’s Meta deal showed labs the risk of leaning on a single vendor. Multi-vendor and hybrid in-house strategies are becoming the safer default.
Q: Do underpaid annotator conditions mean I should avoid outsourced labeling platforms entirely? A: Not automatically, but it means vendor selection is an ethical decision, not just a cost one. The ethical cost of the data labeling industry lays out what to ask a vendor before signing, not just what to pay them.
Q: Is a high inter-annotator agreement score enough to trust a labeled dataset? A: No — agreement only tells you annotators are consistent with each other, not that they are correct. Inter-annotator agreement and annotation guidelines is necessary but must be paired with a separate check for systematic bias.
Part of training data quality and curation · closest neighbour: training data quality.
Data labeling attaches ground-truth answers to raw examples so a model can learn from them. Understand what makes a label trustworthy, how annotators disagree, and why label quality quietly shapes everything downstream.
Concepts covered
Data labeling assigns ground-truth labels to raw data so supervised models learn a mapping. Label noise propagates into model errors geometrically.
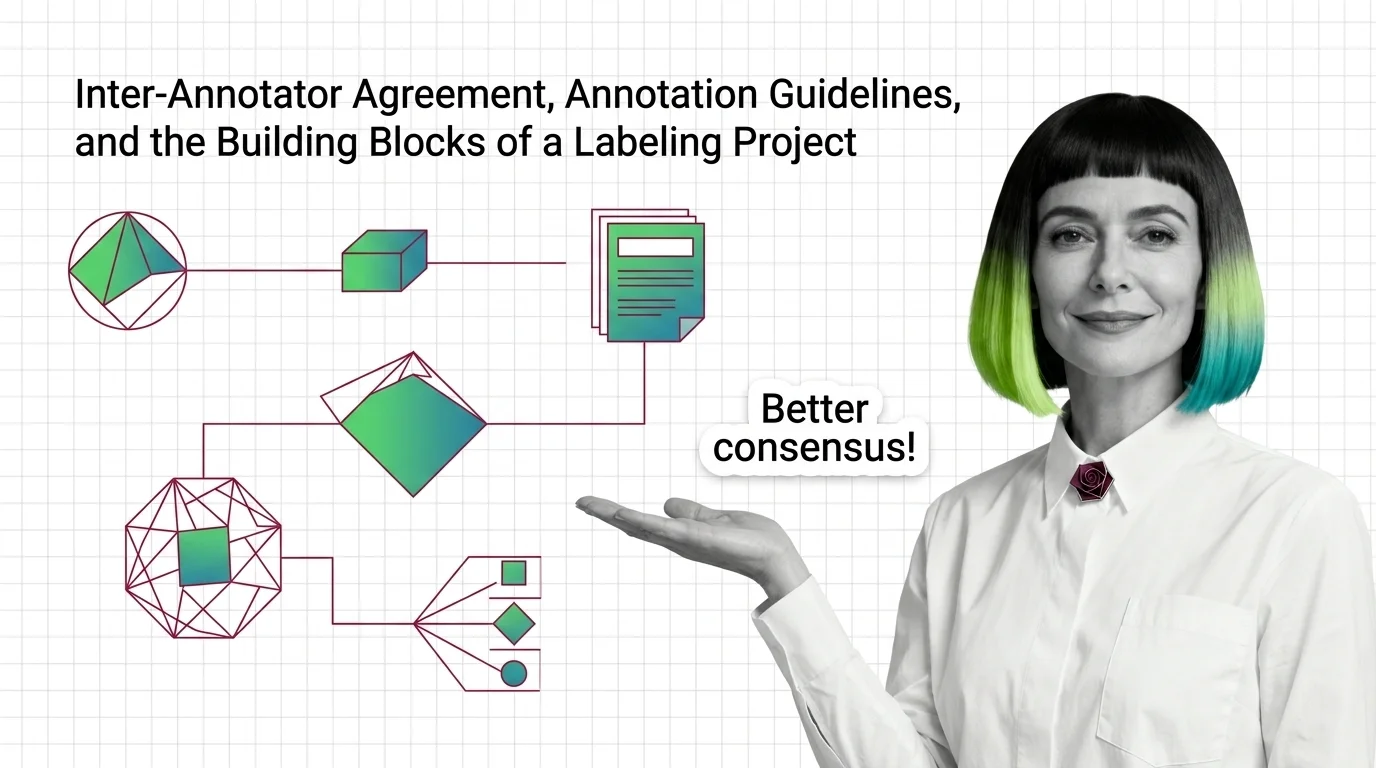
Inter-annotator agreement measures label quality beyond chance. Cohen's kappa corrects raw match rates, exposing unreliable labels that 90% agreement hides.
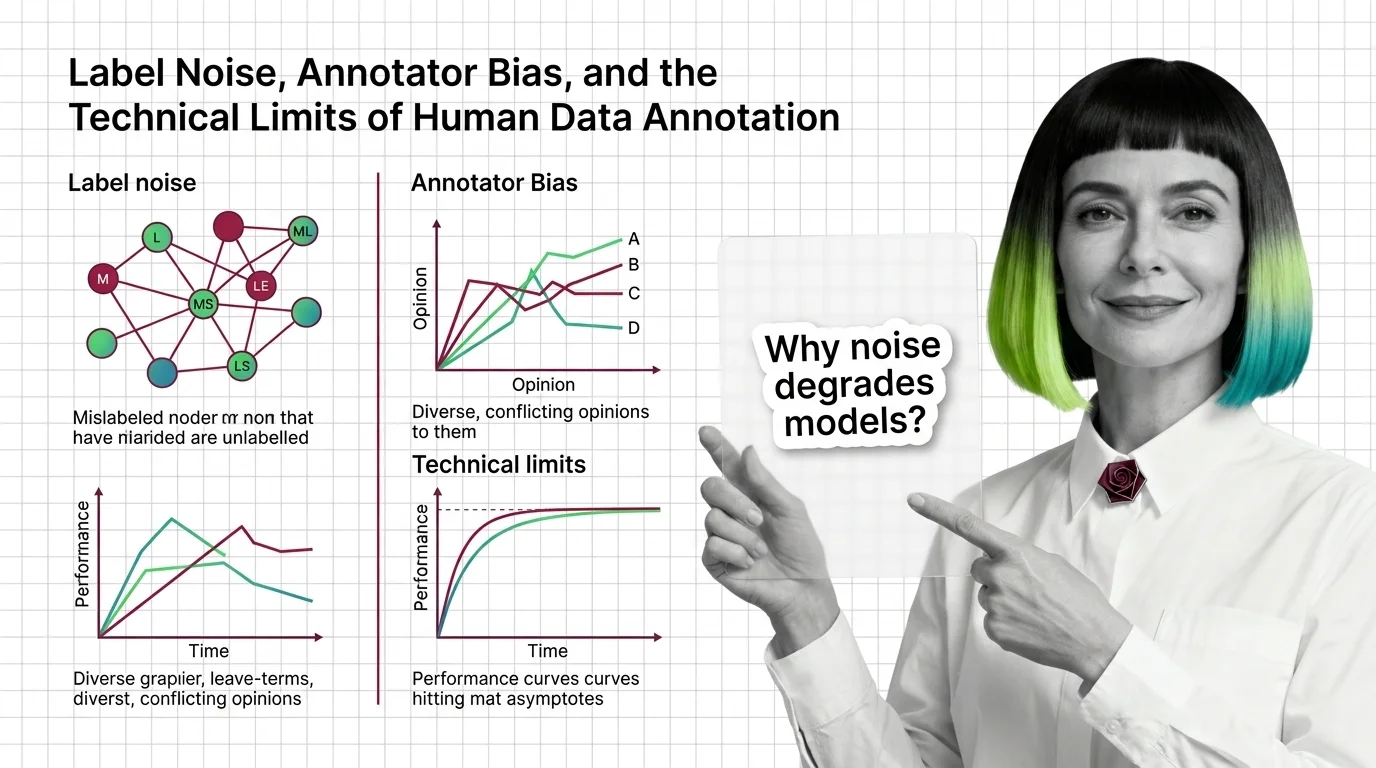
Label noise averages an estimated 3.4% across major ML test sets, distorting supervised model accuracy and even flipping benchmark leaderboard rankings.
These guides walk through assembling a labeling pipeline end to end — choosing tooling, writing annotation guidelines, and weaving in active learning so human effort lands where it actually moves model accuracy.
Tools & techniques
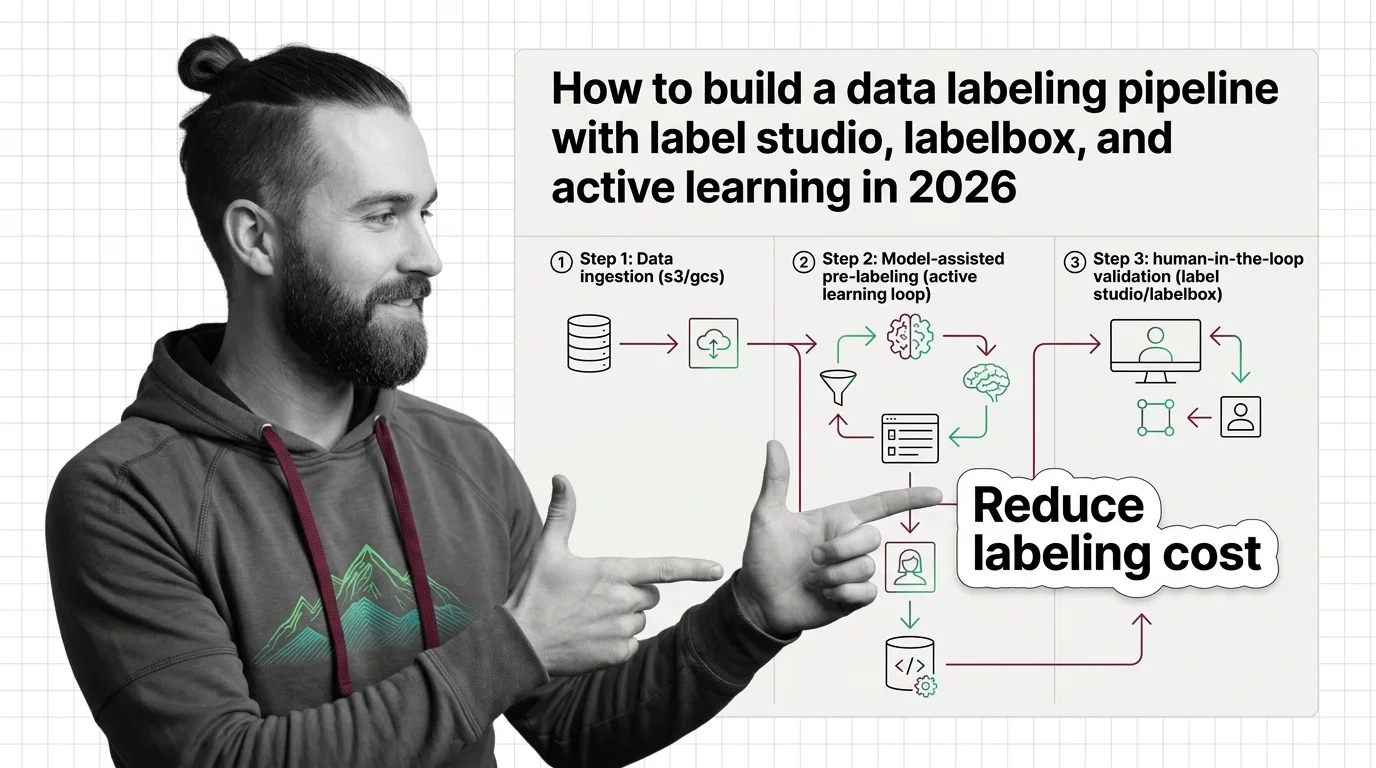
A data labeling pipeline pairs an annotation tool — Label Studio, Labelbox, or CVAT — with active learning to label the uncertain samples first.
The annotation market is shifting fast as programmatic and model-assisted labeling reshape who does the work. Follow these developments to see where human judgment still matters and where automation takes over.
Models & benchmarks
Updated June 2026

Meta's ~$14.3B stake in Scale AI split the data-labeling market: rivals like Surge, Mercor, and Snorkel absorbed the customer exodus heading into 2026.
Behind every labeled dataset sits human labor and human bias. Consider how annotator working conditions, hidden assumptions, and inconsistent guidelines can seep into your model before you deploy it.
Risks & metrics

Data labeling depends on workers earning roughly $1.32–$2/hour to filter traumatic content, while annotator bias quietly shapes what AI treats as truth.