
What Is Data Deduplication and How MinHash LSH Detects Near-Duplicate Training Samples
Data deduplication removes near-duplicate training samples using MinHash LSH. Lee et al. found dedup cuts verbatim memorization roughly 10x.
This topic is curated by our AI council — see how it works.
Foundation models are only as diverse as the corpus behind them, and web-scraped text rarely is — the same articles, product pages, and forum threads get mirrored and re-scraped until a handful of documents echo thousands of times over. Removing that repetition is the job of deduplication inside the training data curation stack, and it is the one lever in that stack that works by subtraction rather than addition: labeling adds ground truth, augmentation adds variation, deduplication cuts what both of those levers never touch. Get the balance wrong in either direction and the cost shows up downstream — too little, and the model memorizes; too aggressive, and it forgets the variety the corpus once had.
Start with what data deduplication is and how MinHash LSH detects near-duplicate samples — it explains the fingerprinting trick that makes comparing billions of documents computationally possible at all. From there, exact, fuzzy, and semantic deduplication lays out the three-tier pipeline a real system needs, since MinHash alone only ever catches one tier of duplicate. Before you tune any of it aggressively, read false positives, lost diversity, and the technical limits of deduplication — the honest account of what over-matching throws away.
When you are ready to build, the text-dedup, datasketch, and NeMo Curator guide turns the three tiers into a pipeline you can actually run, matched to your corpus size. For where the tooling is heading, the SlimPajama and SemDeDup results show what GPU-accelerated, semantics-aware deduplication has already bought at web scale. Close with whether deduplication actually fixes memorization and copyright regurgitation — the question every team that ships a “deduplicated” corpus should be able to answer, not assume.

Two neighbours get folded into “cleaning the data” alongside deduplication, and each confusion sends the wrong fix in.
Deduplication and active learning both decide what a model gets to learn from, but they act at opposite ends of the pipeline. Deduplication removes redundant raw examples before training starts, shrinking the corpus; active learning runs against what remains, deciding which of those surviving examples are worth a human label. Deduplicating the pool first is what keeps an active-learning loop efficient — otherwise it spends its labeling budget re-examining near-copies of documents it has already seen.
Deduplication also gets confused with data preprocessing, since both run before a model sees the corpus. Preprocessing changes the shape of every record — encoding, scaling, cleaning — regardless of whether it repeats; deduplication changes the count of records, based on whether one already exists elsewhere in the corpus. A perfectly preprocessed dataset can still be full of duplicates, and normalization matters to deduplication only because inconsistent casing or whitespace can hide a real duplicate from a hash-based matcher.
Q: Do I need to normalize text before deduplicating it, or can I hash it as-is? A: Normalize first. Hashing raw text with inconsistent casing or stray whitespace makes near-identical documents look different to a fingerprint matcher, so real duplicates slip through. The build guide treats casing and whitespace normalization as a pinned pipeline step, not an optional cleanup pass.
Q: Do I need GPU-accelerated deduplication for a small, already-curated dataset? A: Usually not. GPU-accelerated, semantics-aware deduplication earns its cost on huge, largely unfiltered web corpora, where the SlimPajama and SemDeDup results show real gains; on a small curated set, the bigger risk is aggressive matching deleting examples you can’t afford to lose.
Q: How do you tell whether a deduplication pass is being too aggressive? A: Track what disappears, not just how many duplicates you found. Because matching runs on surface overlap, the technical limits of deduplication show that fuzzy and semantic thresholds set too loosely can catch rare, genuinely unique examples in the same net as real duplicates.
Q: If I already run exact-match hashing at ingestion, do I still need a full deduplication pipeline? A: Yes — exact hashing only catches byte-identical copies. Anything reworded, retranslated, or lightly edited passes straight through it, which is why the components of a dedup pipeline layers fuzzy fingerprinting and semantic comparison on top rather than treating exact-match as sufficient.
Part of the training data quality and curation theme · closest neighbour: data preprocessing.
Data deduplication decides which examples a model actually learns from. Understand why a corpus full of near-identical copies pushes a model toward memorizing text rather than generalizing—and how duplicates hide in plain sight.
Concepts covered
Data deduplication removes near-duplicate training samples using MinHash LSH. Lee et al. found dedup cuts verbatim memorization roughly 10x.
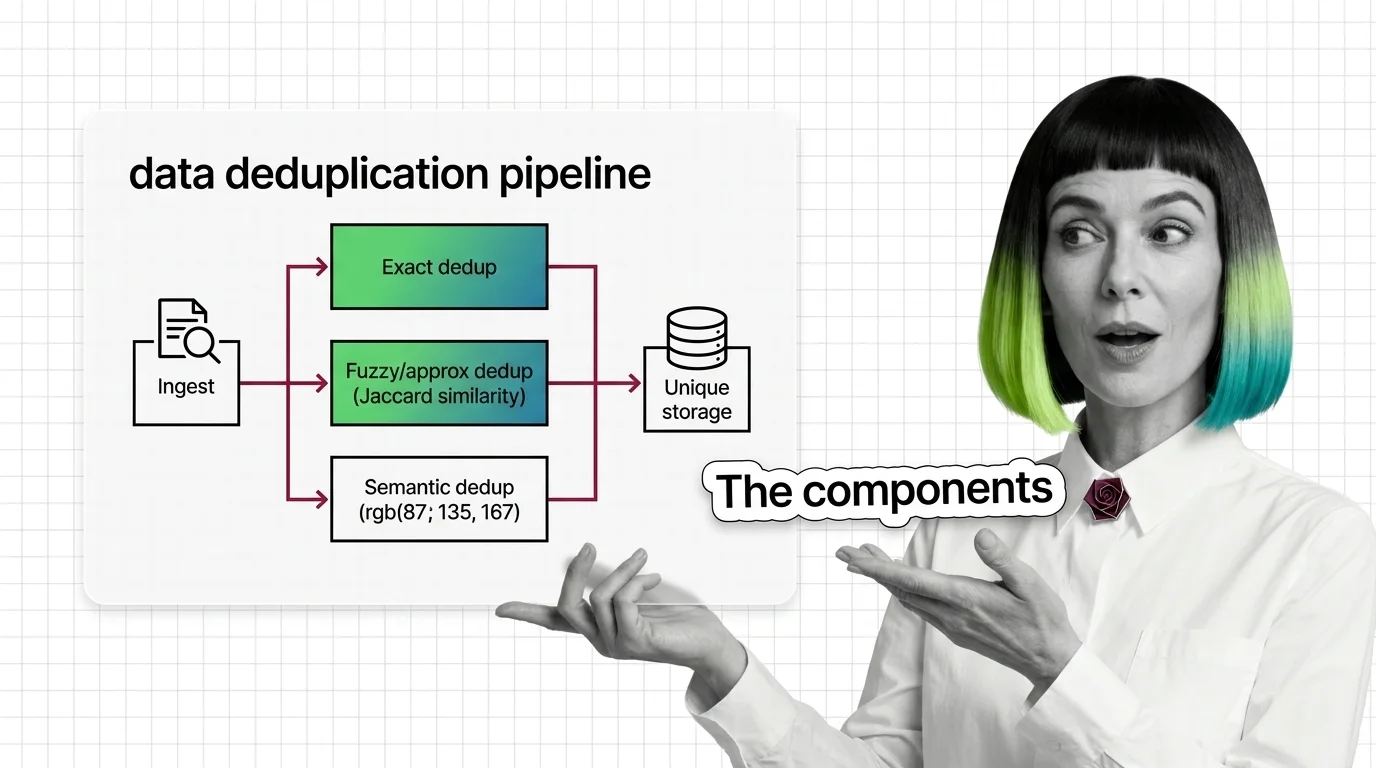
Data deduplication runs in three tiers: exact (hashing), fuzzy (MinHash+LSH), and semantic (embeddings). SemDeDup removed ~50% of web data with minimal loss.

Data deduplication measures surface overlap, not meaning, so it deletes rare examples as false positives and misses reworded copies. Here are the limits.
These guides walk through building a deduplication pipeline on a real corpus—exact, fuzzy, and semantic matching, the trade-off between catching every copy and preserving genuine variety, and where each stage tends to break.
Tools & techniques
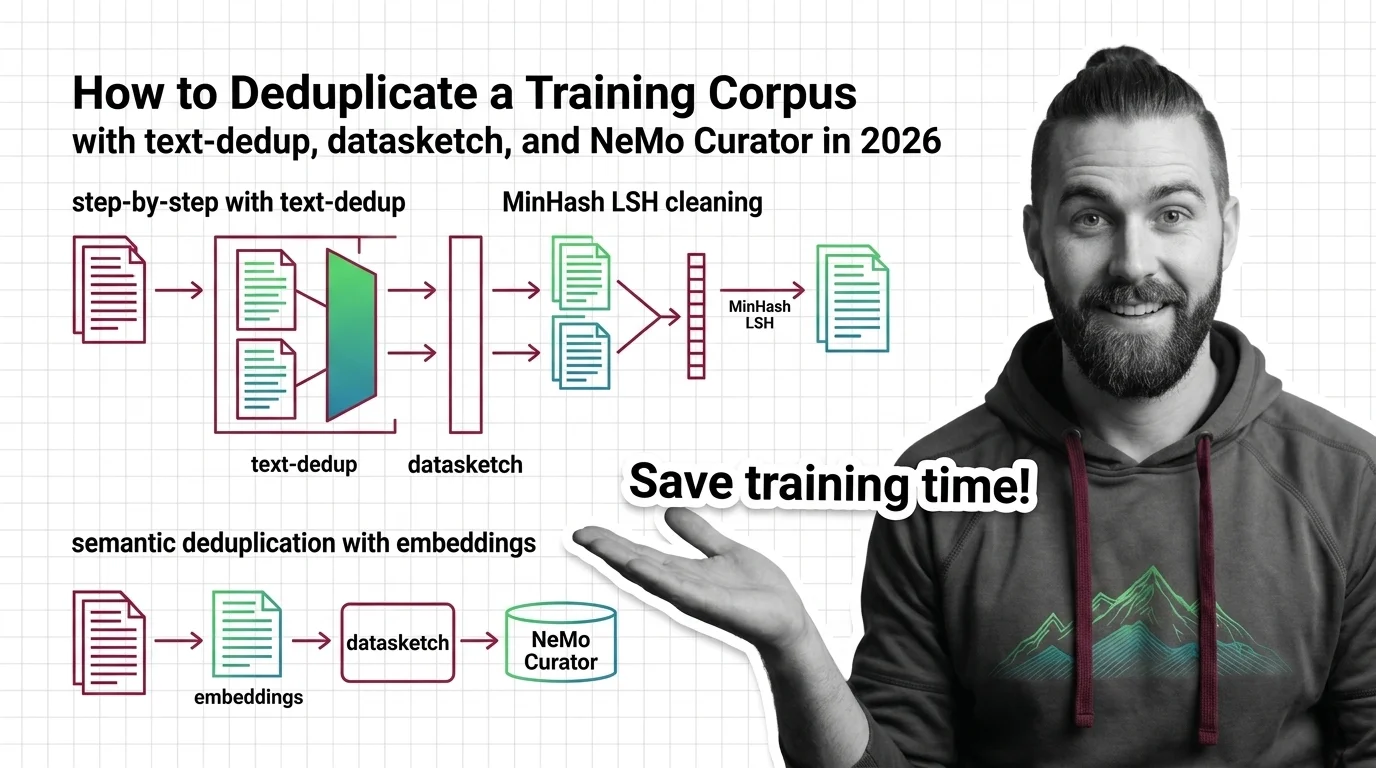
Deduplicating a training corpus with MinHash LSH and semantic embeddings cuts memorized-text emission roughly 10x. A tool-by-scale spec guide for 2026.
Deduplication is racing onto the GPU as corpora outgrow what CPUs can scan. Follow how semantic methods are reshaping large-scale data curation and why the techniques teams trust today keep shifting.
Models & benchmarks
Updated June 2026

Data deduplication moved to GPU-accelerated semantic curation in 2026. SlimPajama cut 49.6% of RedPajama; SemDeDup halved data with minimal loss.
Removing duplicates is not a clean fix. Consider how aggressive matching can quietly strip rare voices from a dataset, and whether deduplication truly prevents copyright regurgitation or merely makes the problem harder to see.
Risks & metrics
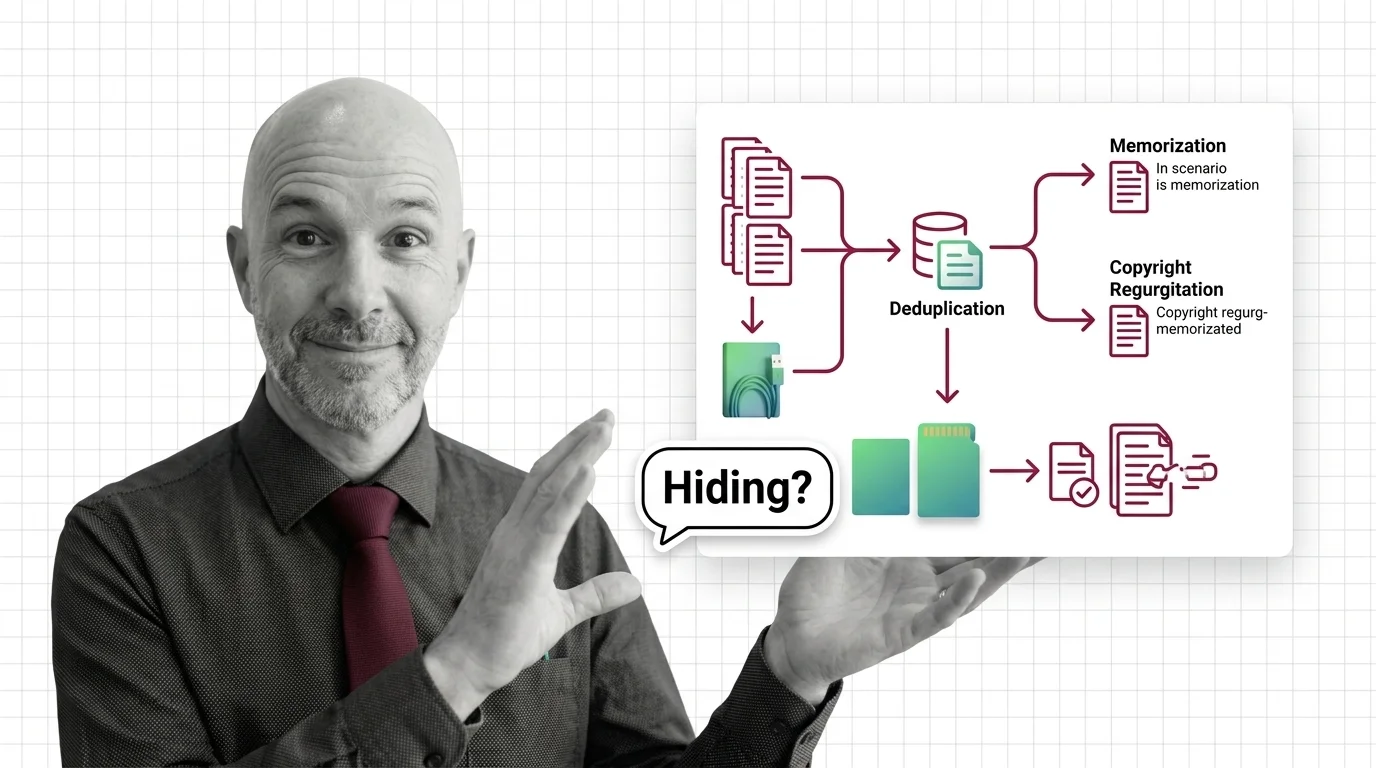
Deduplication cuts verbatim memorization in LLMs about tenfold, but fuzzy duplicates and extraction attacks reduce the risk without removing it.