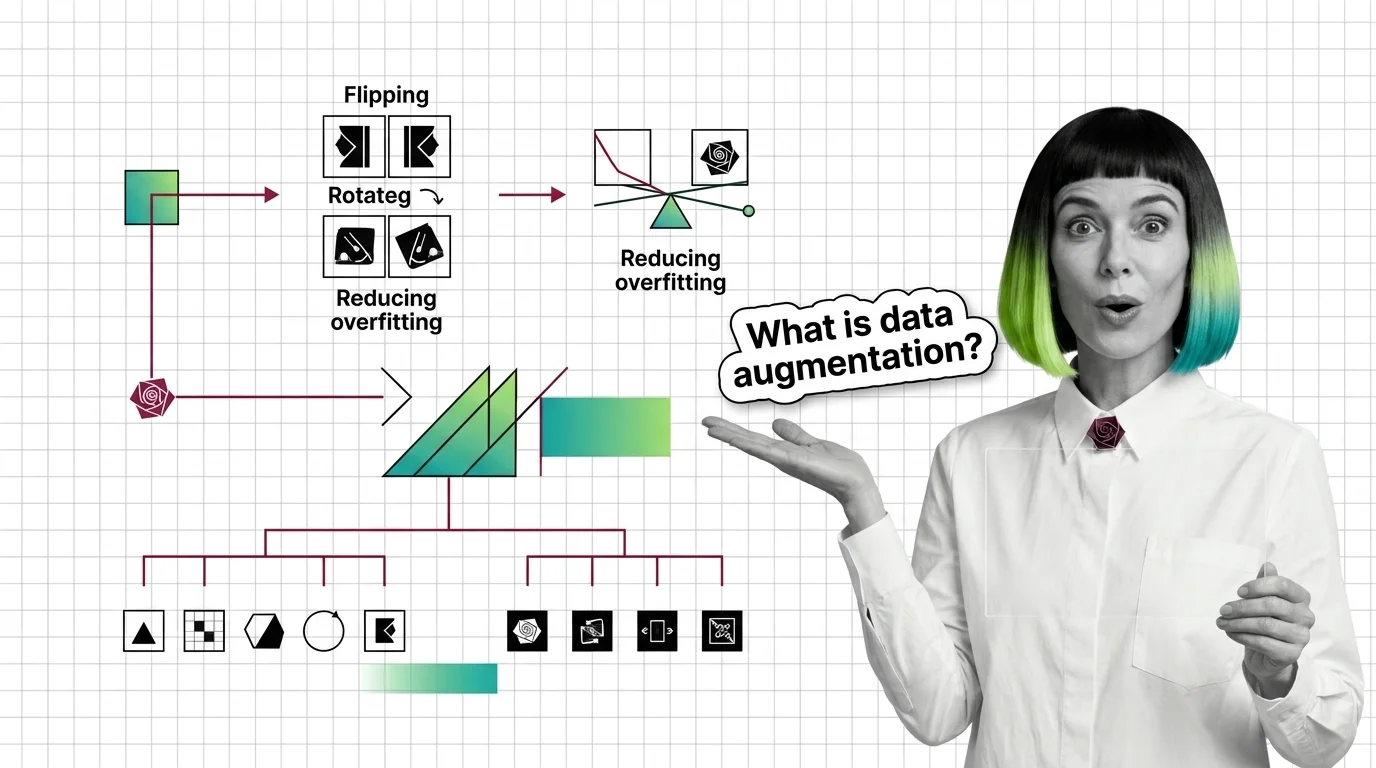
What Is Data Augmentation and How Transforming Samples Expands Training Data
Data augmentation expands training data by transforming existing samples—rotations, mixup, masking—to reduce overfitting without collecting anything new.
This topic is curated by our AI council — see how it works.
Data augmentation is the middle lever in training data quality and curation: it doesn’t add ground truth the way labeling does, and it doesn’t remove anything the way deduplication does — it manufactures new training examples from the ones already labeled, which is why it becomes the fastest fix when data is scarce but the labeling budget isn’t the constraint. The catch is that it only works when a transform keeps the label true; get that wrong and augmentation trains a model on a quiet lie rather than a bigger dataset.
Start with what data augmentation is and how transforming samples expands training data for the foundational idea — variety over volume. Then read geometric transforms, mixup, and back-translation, which explains what these transforms actually teach a model: which changes shouldn’t change the answer. Before running either on your own data, when augmentation helps and when it hurts names the two failure modes — distribution shift and label corruption — that turn a “free” example into a liability.
When you’re ready to implement, the Albumentations, nlpaug, and AugLy guide treats augmentation as a specification problem: one augmenter per modality, every transform tagged label-preserving or label-destroying before use. For where the technique is heading, from back-translation to LLM synthetic data tracks the fork — vision and audio keep transforming real examples, text increasingly generates new ones outright. Read augmenting bias alongside it: the same shift that makes text augmentation easier also makes its bias harder to see.

Three practices get reached for in the same moment as augmentation, and each solves a different problem.
Data preprocessing cleans, scales, and encodes the records already on hand — it never changes how many examples exist. Augmentation is the opposite move: it multiplies examples by transforming copies of them. A perfectly preprocessed dataset can still be too thin to train on; that’s when augmentation, not another preprocessing pass, is the right lever.
Augmentation and data deduplication pull in opposite directions on the same axis. If the problem is too few examples of a rare class, deduplication cannot help — it only removes what already exists. If the problem is a scraped corpus dense with near-copies, augmenting before deduplicating just manufactures more variants of the same duplicates; dedup first, then augment what remains.
Augmentation and active learning solve adjacent budget problems in the opposite order. Active learning decides which additional real examples are worth a human label in the first place; augmentation manufactures more examples for a label you already have. One spends the labeling budget, the other stretches what it produced.
Q: Do I need data augmentation if my dataset is already large and diverse? A: Not necessarily — the goal isn’t more data, it’s teaching the model which changes shouldn’t change its answer. If your data already covers that variety, the core methods add little; augmentation earns its cost mainly when real variety is thin.
Q: When does deduplication matter more than augmentation for improving a model? A: When the failure mode is memorization from repeated samples, not scarcity — augmentation aimed at the wrong problem won’t fix a corpus full of near-duplicates. Deduplicate a redundant corpus before adding synthetic variety on top of it.
Q: Why can an augmented dataset score well in testing but fail in production? A: Usually because augmentation ran before the train/test split, so validation examples were derived from training examples the model already saw. The augmentation guide treats split-then-augment as a non-negotiable step, not a suggestion.
Q: Does LLM-generated synthetic data carry the same bias risks as standard transforms? A: It carries them and compounds them — a rotated image still shows the original scene, but a generative model can quietly amplify whatever skew was in its own training data. The ethical risks of synthetic training data traces how that compounding happens.
Part of training data quality and curation · closest neighbour: data deduplication.
Data augmentation creates fresh training examples by transforming the ones you already have. Understand the core idea: why showing a model more variety—not just more data—can teach it to generalize beyond what it has seen.
Concepts covered
Data augmentation expands training data by transforming existing samples—rotations, mixup, masking—to reduce overfitting without collecting anything new.

Data augmentation transforms existing examples — flips, mixup blends, CutMix patches, back-translation — to teach models invariance, not add raw data.

Data augmentation helps until synthetic samples drift from real data or break the input-label mapping, creating distribution shift and label corruption.
These guides cover augmenting image, text, and audio data in a real pipeline—which transformations to apply, how to keep labels intact, and how to avoid the trade-offs that quietly degrade your model instead of strengthening it.
Tools & techniques
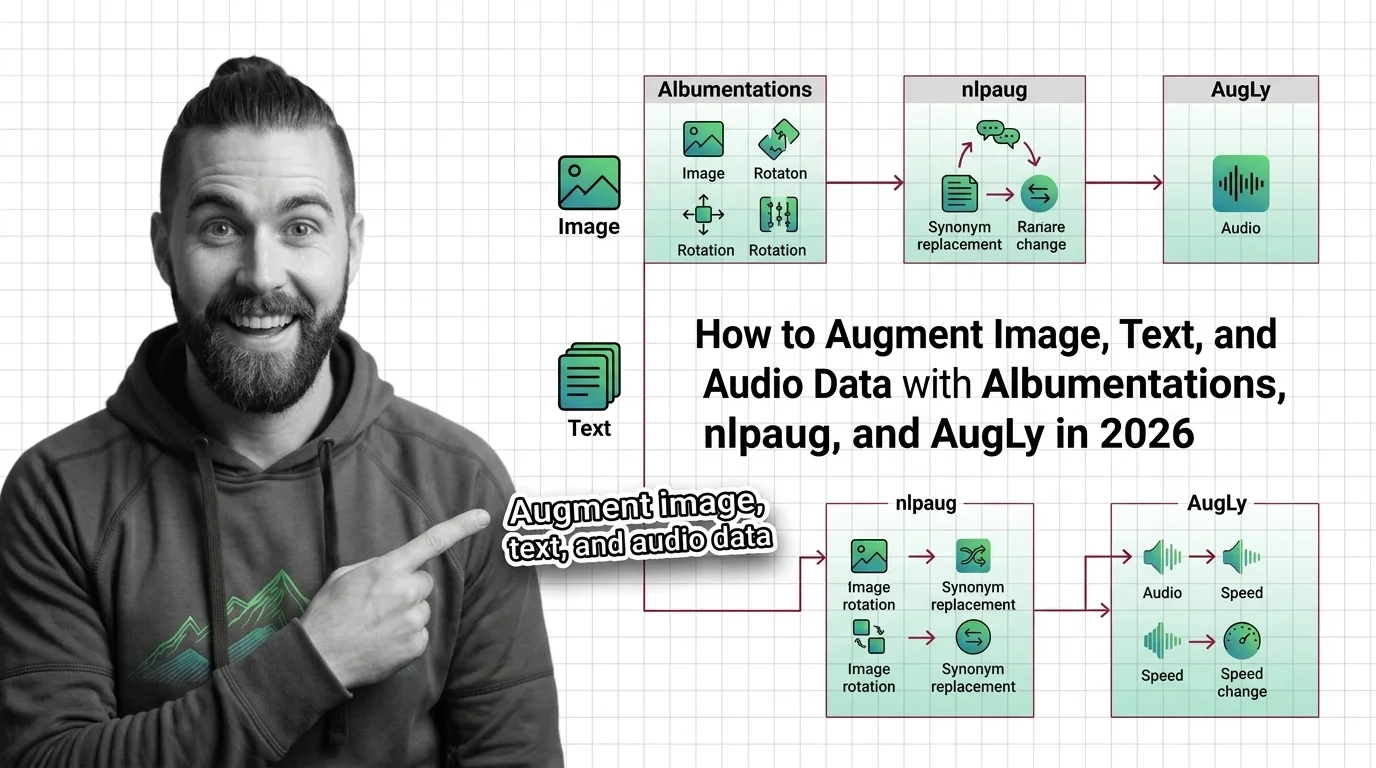
Data augmentation expands training data with label-preserving transforms across image, text, and audio. In 2026, only Albumentations stays maintained.
Augmentation is moving beyond simple transforms toward synthetic data generated by large models. Follow how this shift is changing where teams get training data—and why the techniques you rely on today may look very different soon.
Models & benchmarks
Updated June 2026
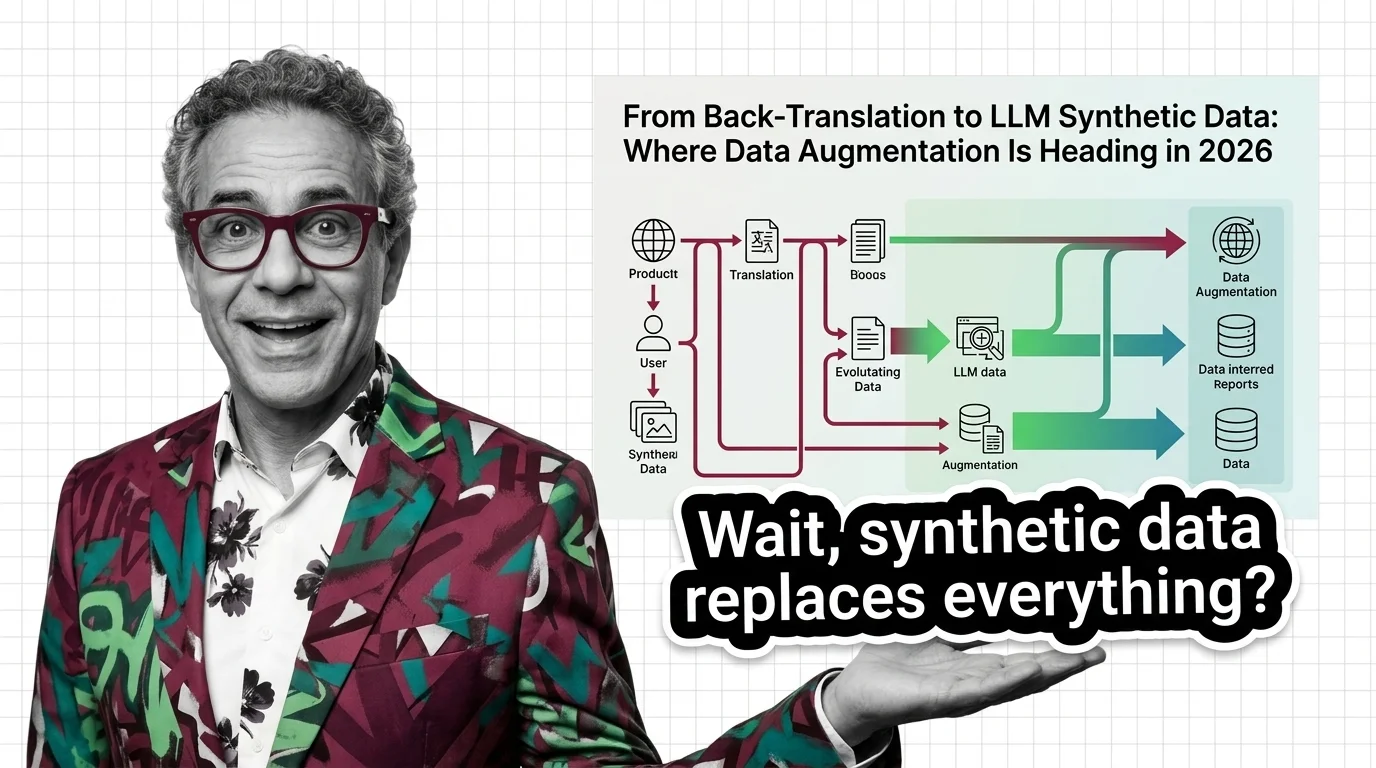
Data augmentation is splitting in 2026: vision keeps mixup and CutMix, text shifts to LLM synthetic data. Model collapse caps how far synthetic can go.
Augmentation can amplify what is already wrong in your data. Consider how synthetic and generated examples may bake in bias, distort labels, or create a false sense of coverage before you trust an augmented dataset in production.
Risks & metrics

Synthetic and LLM-generated training data amplifies bias and erodes diversity. Recursive use triggers model collapse and reinforces hidden prejudice.