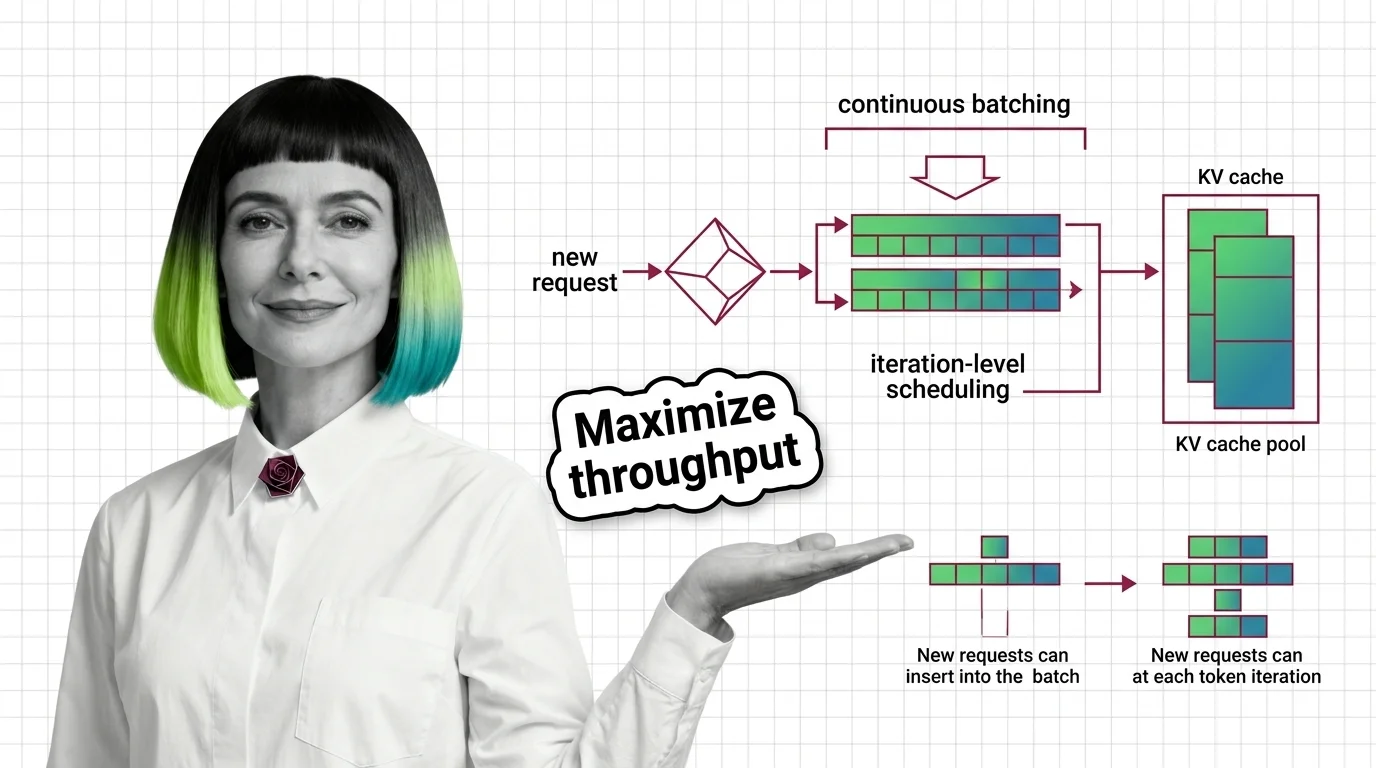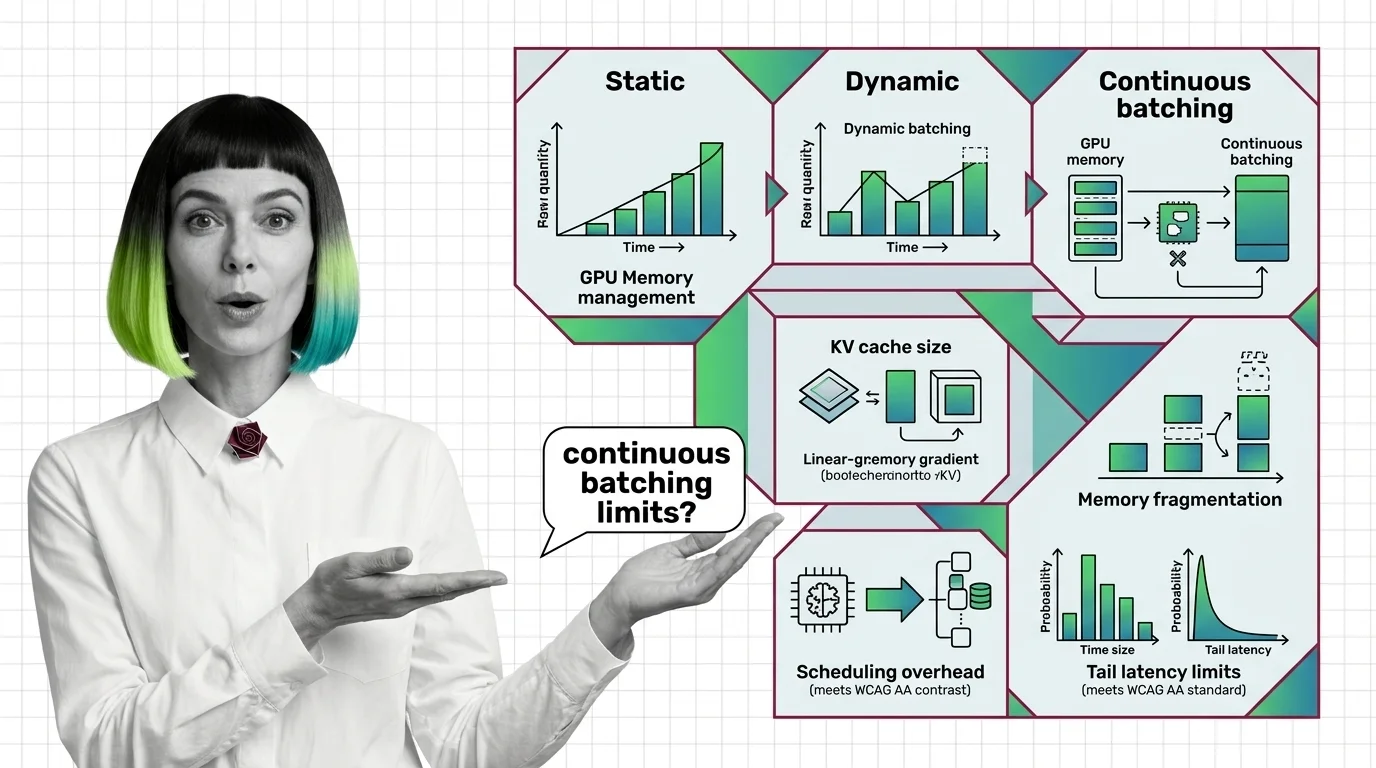
From Static Batching to PagedAttention: Prerequisites and Hard Limits of Continuous Batching
Continuous batching swaps finished LLM requests every decode step. Learn how PagedAttention cuts KV cache waste to under 4% and where the hard limits emerge.