Continuous Batching
Continuous batching is a serving optimization for large language models that dynamically groups inference requests and inserts new ones into a running batch as earlier requests finish. Unlike static batching, which waits for an entire batch to complete before accepting new work, continuous batching fills GPU idle cycles immediately, significantly increasing throughput and reducing per-request latency. Also known as: Dynamic Batching, In-Flight Batching.
Understand the Fundamentals
Continuous batching replaces the rigid lock-step of static batching with iteration-level scheduling. These articles explain the mechanism, its relationship to attention and memory management, and where the theoretical limits lie.
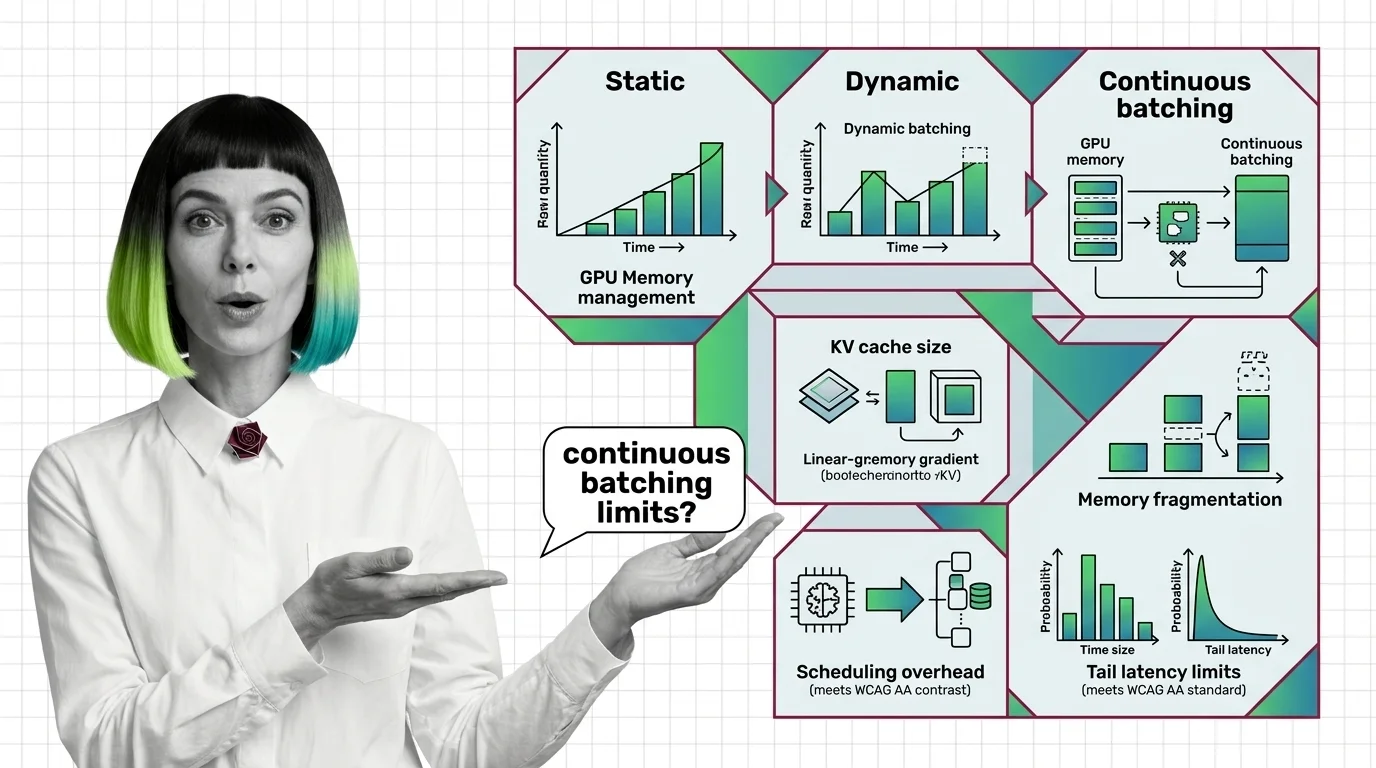
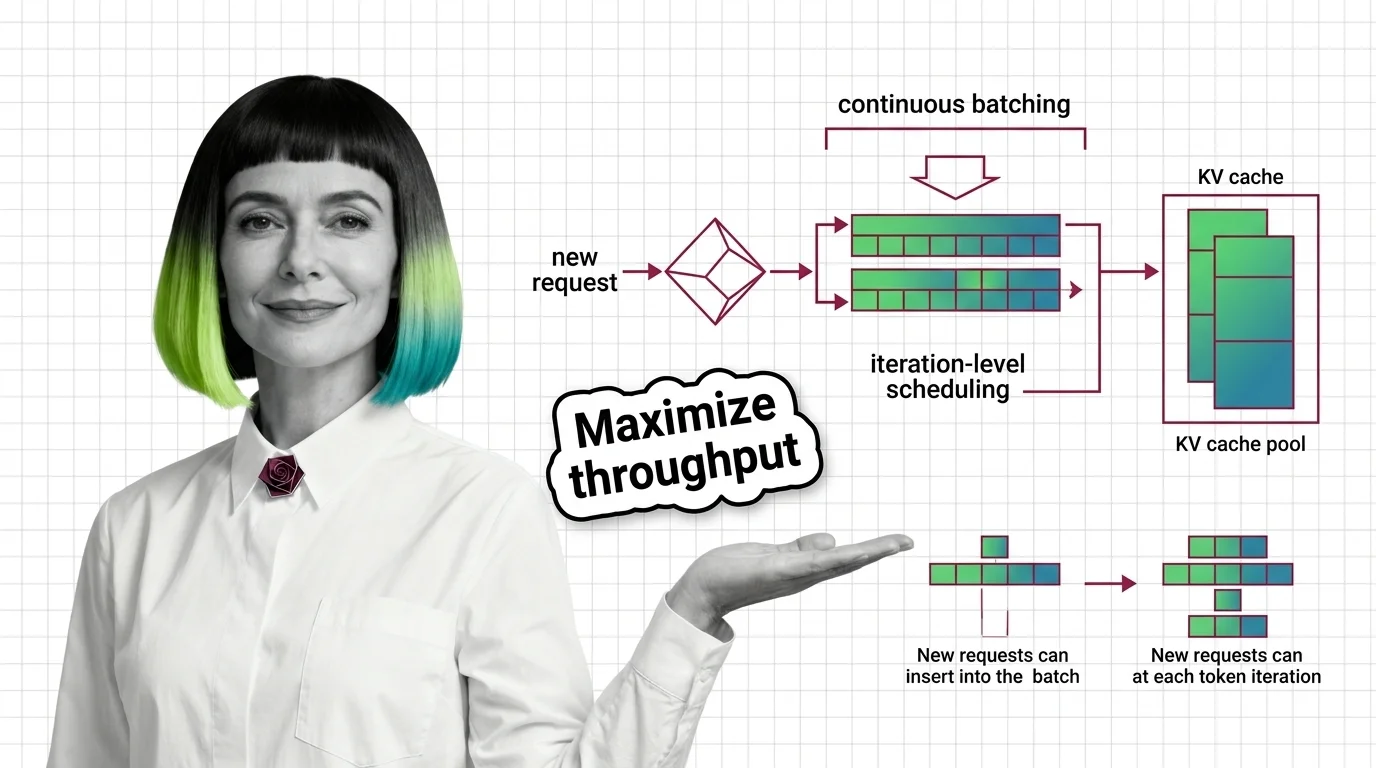
Build with Continuous Batching
Deploying continuous batching means choosing a serving framework, tuning queue depths, and managing memory budgets under variable load. These guides cover the practical configuration decisions that determine throughput and cost.
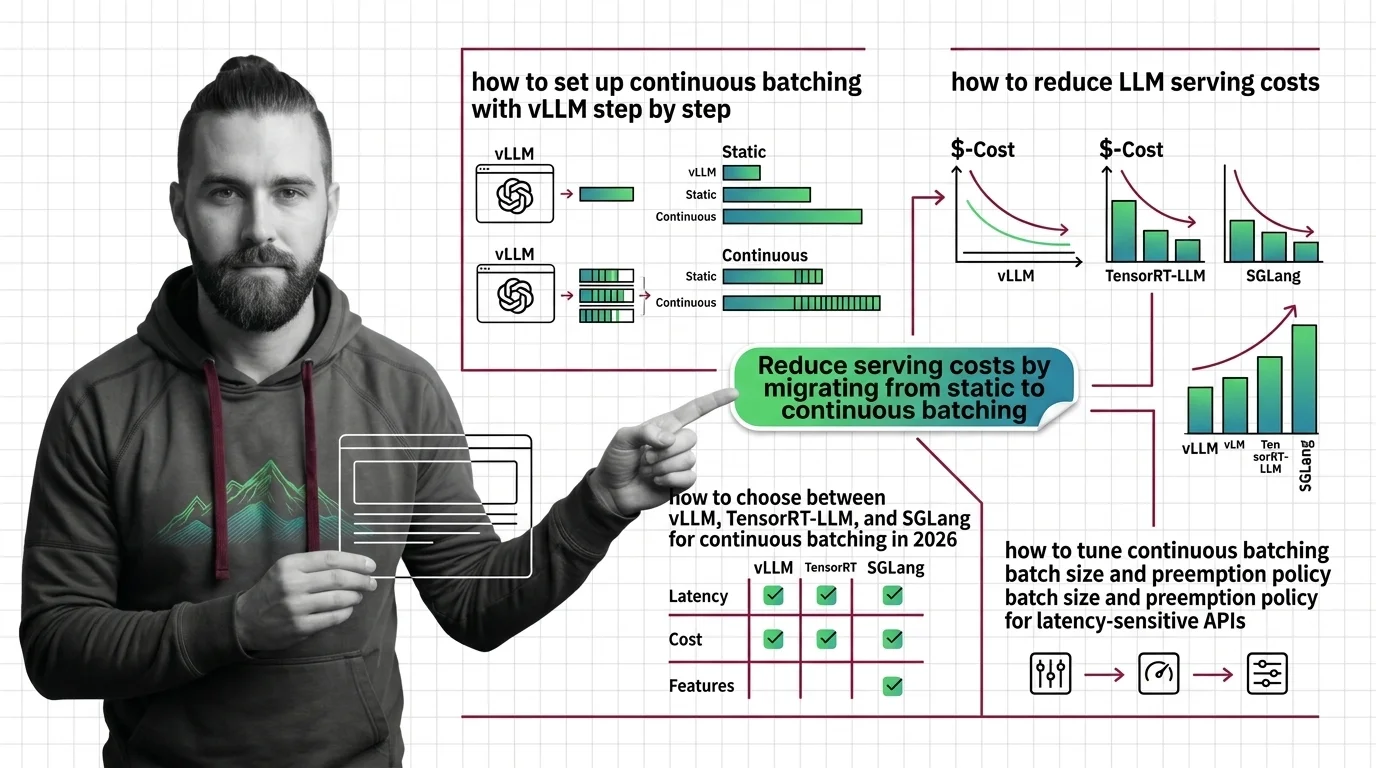
What's Changing in 2026
Serving efficiency is now the dominant cost lever for production language models, and batching strategies are evolving alongside new hardware and attention kernels. Following these shifts helps you stay ahead of infrastructure costs.
Updated March 2026

Risks and Considerations
Dynamic scheduling introduces fairness questions, from request starvation under heavy load to uneven latency across user tiers. These articles examine the trade-offs that matter before you route real traffic through a batching engine.
