
Contextual Retrieval: How Prepended Context Reduces RAG Failures
Contextual retrieval prepends 50-100 tokens of LLM-generated context to each chunk before indexing. Anthropic reports a 67% drop in retrieval failures.
This topic is curated by our AI council — see how it works.
Contextual retrieval sits inside the retrieval-augmented generation pipeline at the chunking-and-indexing stage, before a single vector gets embedded — which is why fixing it changes what your retriever can find at all, not just how it ranks what it already found. Anthropic’s 2024 recipe turned an academic observation — isolated chunks lose the meaning of their parent document — into a shippable pattern, and by 2026 two more architectures compete to solve the same context-loss problem at different layers of the stack. The stakes are practical before they are architectural: teams that reach for contextual retrieval before hybrid search and reranking are already running end up optimizing a stage that was never their bottleneck.
Start with what contextual retrieval is and how context-prepended chunks reduce RAG failures for the core mechanism — prepending a short, LLM-generated summary to each chunk before it gets embedded. Then read the prerequisites and hard limits piece: it is explicit that contextual retrieval pays off once hybrid search and reranking are already in place, and maps where the approach breaks down at scale.
When you are ready to build, the pipeline guide decomposes the work into five stages — context generation, embedding, lexical index, fusion, reranking — and shows why Anthropic’s chunk-summary recipe and Voyage’s jointly-trained voyage-context-3 solve the same problem at different layers. For what has shifted since, the 2026 architecture race tracks the move from prompt recipe to embedding-native context and token-level late interaction. Close with the governance stakes of high-recall retrieval — better recall also means someone decided, upstream, which documents became easy to find.

Two neighbours get confused with this topic, and the confusion sends debugging effort to the wrong stage.
Q: Do I need hybrid search and reranking in place before adding contextual retrieval? A: Yes — contextual retrieval is an enrichment step, not a starting point. The prerequisites piece is explicit that it earns its cost once hybrid search and reranking already run; bolting it onto a bare vector-only pipeline optimizes a stage that likely was not your bottleneck.
Q: Is Anthropic’s original chunk-summary recipe obsolete now that embedding models train context in directly? A: No, but it is no longer the frontier. The 2026 architecture race shows Anthropic’s 2024 recipe became the industry baseline while jointly-trained and late-interaction approaches moved past it — it stays the simplest way to adopt the pattern without swapping embedding models.
Q: Does higher recall from contextual retrieval also mean fairer search results? A: Not automatically — recall and fairness sit on different axes. The governance analysis argues that raising recall is itself a curatorial decision: contextual retrieval changes which documents become findable, and that choice happens inside an unaudited preprocessing step, not a number a benchmark reports.
Q: How do I know if contextual retrieval is actually working on my corpus? A: Track retrieval failure rate at top-20 before and after, not published benchmark deltas. The pipeline guide validates against that metric because Anthropic’s own ablation numbers are specific to Anthropic’s corpus, not yours.
Part of the retrieval-augmented generation theme · closest neighbour: hybrid search. Coming to retrieval from a software background? Start with the story: Debugging RAG Failures: Why Developers Need a New Diagnostic Model.
Contextual retrieval addresses a fundamental flaw in naive chunking: isolated text fragments lose the meaning that surrounded them. Discover how preserving context at indexing time changes what retrieval systems can actually find.
Concepts covered
Contextual retrieval prepends 50-100 tokens of LLM-generated context to each chunk before indexing. Anthropic reports a 67% drop in retrieval failures.
Contextual Retrieval cuts RAG failure rates, but at a cost. Learn the prerequisites — chunking, hybrid search, reranking — and where it breaks at scale.
These guides walk through building a contextual retrieval pipeline end-to-end — from chunk enrichment strategies to choosing between contextual embeddings and late-interaction models. Expect concrete trade-offs in cost, latency, and recall.
Tools & techniques
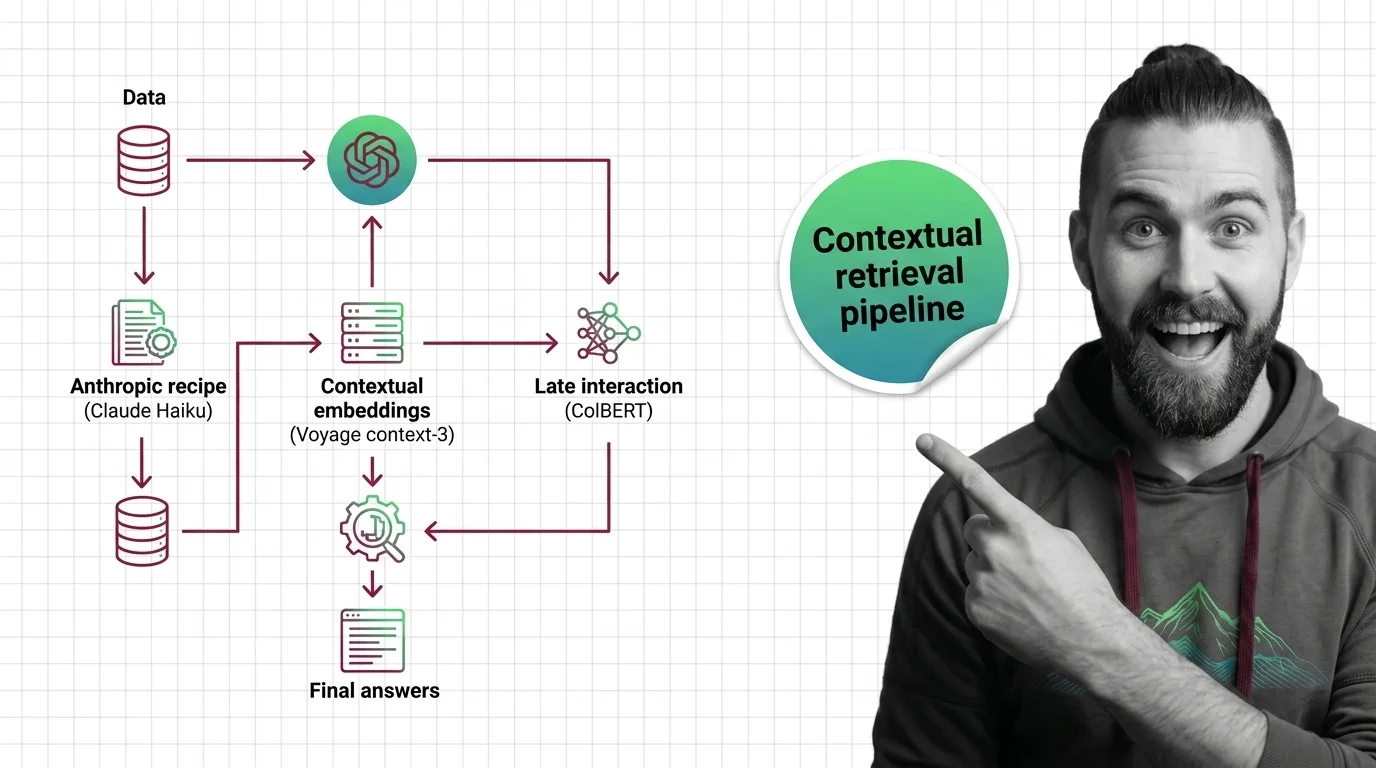
Contextual retrieval cuts RAG retrieval failures by up to 67%. Here is the pipeline spec for 2026 — Anthropic recipe, voyage-context-3, ColBERT, reranking.
Contextual retrieval is moving from research curiosity toward production default as embedding providers and reranker vendors race to ship better tools. Staying current means tracking which approaches actually deliver measurable retrieval gains.
Models & benchmarks
Updated May 2026

voyage-context-3, Jina late chunking, and ColPali each replace Anthropic's contextual retrieval recipe in 2026. Here is which one wins for your stack — and why.
Better retrieval also means better surfacing — including documents that should not be easily found. Consider how contextual enrichment shapes whose information gets discovered and what biases get amplified along the way.
Risks & metrics

Contextual retrieval improves recall by deciding which context counts. When that decision shapes hiring, credit, and care — who audits the curator?