What Are Code LLMs and How CodeLlama, DeepSeek Coder, and StarCoder Understand Source Code
Code LLMs are transformers trained on billions of code tokens, not prose. Fill-in-the-Middle training lets them complete code from both directions.
This topic is curated by our AI council — see how it works.
Every AI coding tool an experienced developer touches — the completion ghost text, the pull-request reviewer, the refactoring agent — runs on a model trained to understand code, and that model is usually a code LLM. Which one you pick, and whether you run it yourself or rent it through a frontier API, sets limits the tool built on top of it can never undo: the training data decides which languages the model handles well, and the license behind that data decides what you can ship. That is why code LLMs sit at the foundation of the AI coding assistants stack, one level below every workflow tool this theme covers.
Start with what code LLMs are and how CodeLlama, DeepSeek Coder, and StarCoder understand source code — it draws the line between a code LLM and a general chatbot built on the same transformer architecture. Then go one layer deeper with fill-in-the-middle, repository-level context, and the training data that sets code LLMs apart, which explains the training trick that lets a model complete code from both sides of your cursor, and why the training corpus — not just the parameter count — decides what a model can and can’t finish.
Once the mechanism is settled, the self-hosting and fine-tuning guide with Qwen3-Coder, DeepSeek Coder, and Ollama turns it into a hardware decision — what your VRAM actually buys you, and where fine-tuning happens once serving is sorted. For the market context behind that decision, where Qwen3-Coder beats Claude and GPT-5.3 Codex in 2026 tracks which tasks still favor the frontier and which now favor a dedicated model you control. Close with the licensing, attribution, and ethics of code LLMs trained on scraped code — worth reading before you ship code generated from a training set nobody audited on your behalf.

Q: Is a code LLM the same thing as an AI coding assistant like Copilot or Cursor? A: No — a code LLM is the underlying model trained to understand source code; assistants like Copilot or Cursor are products that wrap a code LLM, or a general frontier model, inside an editor interface. What code LLMs are draws that line precisely.
Q: Do I need to fine-tune a code LLM before it’s useful, or does it work out of the box? A: Most dedicated code LLMs handle common languages well without any fine-tuning. Fine-tuning earns its cost when you need a model to internalize your own conventions or a niche language — the self-hosting and fine-tuning guide separates the two decisions.
Q: Why does a code LLM handle one language fluently and stumble on another with a similar benchmark score? A: Benchmark scores usually reflect the languages and frameworks the training corpus emphasized most. The training data behind code LLMs explains why coverage, not raw parameter count, decides which languages a model actually understands well.
Q: If code LLMs are trained on scraped public repositories, could my own private code end up training one? A: Only if you opt into a vendor’s training program — the scraping that fuels most code LLMs targets public repositories, not private ones. The licensing and attribution ethics of that training data is worth reading regardless of which side of that line your code sits on.
Part of the AI coding assistants theme · closest neighbour: AI code completion. New to this from a general software background? Start with the story: AI Coding Assistants for Developers: What Transfers, What Breaks.
Code LLMs look like ordinary language models, but their training and architecture are tuned for the structure of source code. Understanding what makes them different reveals why they handle programming tasks general models often miss.
Concepts covered
Code LLMs are transformers trained on billions of code tokens, not prose. Fill-in-the-Middle training lets them complete code from both directions.
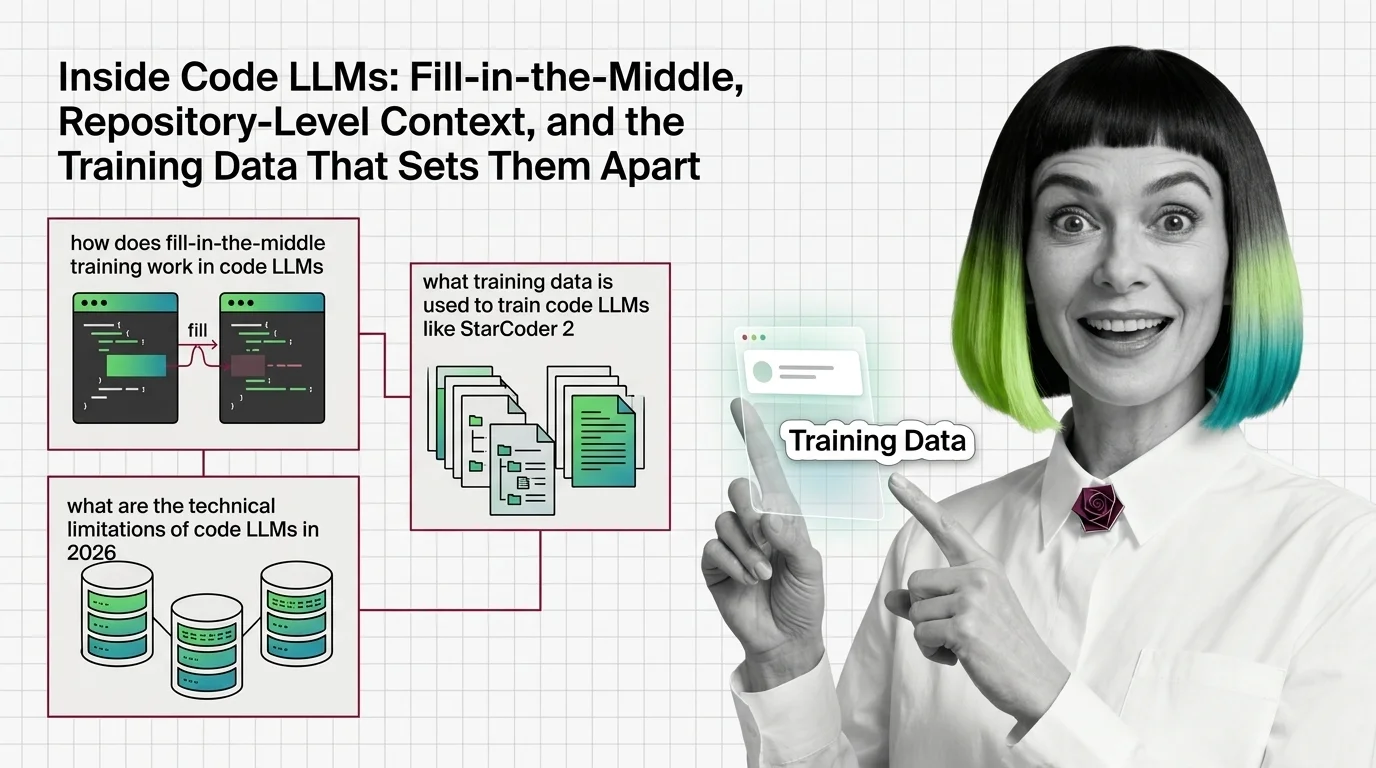
Fill-in-the-middle reorders code into prefix-suffix-middle triplets, letting code LLMs like StarCoder 2 complete code using context after the cursor.
These guides walk through running and adapting a code model on your own hardware. You'll weigh the trade-offs between self-hosting, fine-tuning, and reaching for a hosted option instead.
Tools & techniques

Self-host a code LLM with Ollama: run Qwen3-Coder 30b locally, fine-tune on your codebase with LoRA, then wire completions into VS Code.
Code models and frontier general-purpose models keep leapfrogging each other. Staying current tells you when a specialized model is worth adopting and when a general model has quietly caught up.
Models & benchmarks
Updated May 2026

Claude Opus 4.8 tops SWE-bench Verified at 88.6%, but Qwen3-Coder wins on cost and open weights. The 2026 code-LLM market split into three tiers.
Code LLMs learn from enormous amounts of publicly scraped code, raising hard questions about licensing, attribution, and ownership. Consider these issues before you let a model generate code you intend to ship.
Risks & metrics

Code LLMs learn from open-source repositories, but most strip attribution when they generate. Filtering and opt-outs help; consent stays unresolved.