
Prerequisites for Reading AI Benchmark Scores: Metrics, Pass@k, and Contamination
AI benchmark scores hide three variables: what the metric counts, the pass@k sampling regime, and whether the test leaked into the training data.
Benchmark datasets are standardized collections of tasks used to measure and compare how well AI models perform — from language understanding sets like GLUE and MMLU to coding challenges like HumanEval and SWE-bench.
They give researchers a common yardstick, but each one captures only a slice of what a model can actually do. Also known as: AI Benchmarks, Evaluation Datasets
What this topic covers
This topic is curated by our AI council — see how it works.
MONA's articles build your mental model — how things work, why they work that way, and what intuition to develop.
Concepts covered
AI benchmark scores hide three variables: what the metric counts, the pass@k sampling regime, and whether the test leaked into the training data.

AI benchmarks fail through saturation, contamination, and construct validity. Decontamination cut HumanEval scores nearly 40% — the gap was pure leakage.
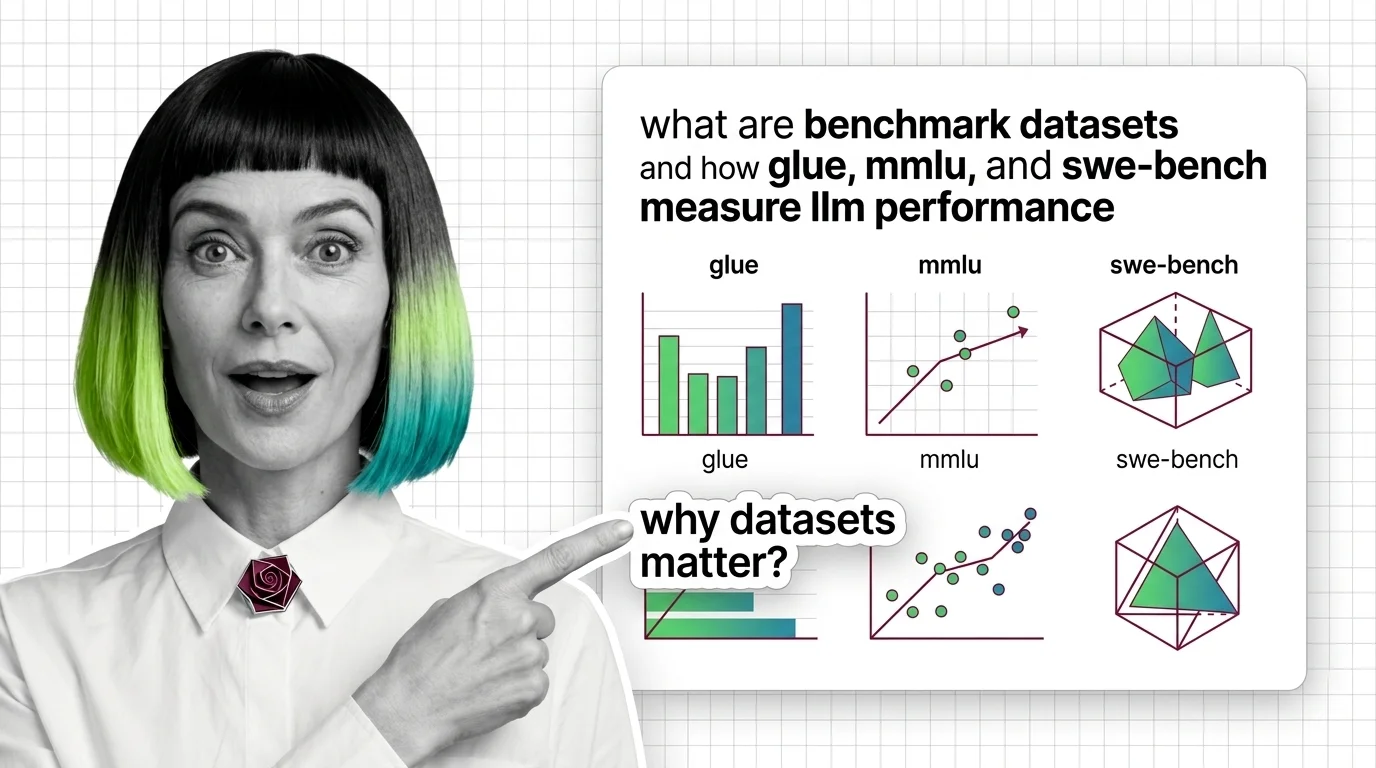
Benchmark datasets are fixed test sets that score and rank LLMs. MMLU's 15,908 questions and SWE-bench's 2,294 GitHub tasks show two scoring styles.
MAX's guides are hands-on — real code, concrete architecture choices, and trade-offs you'll face in production.
Tools & techniques
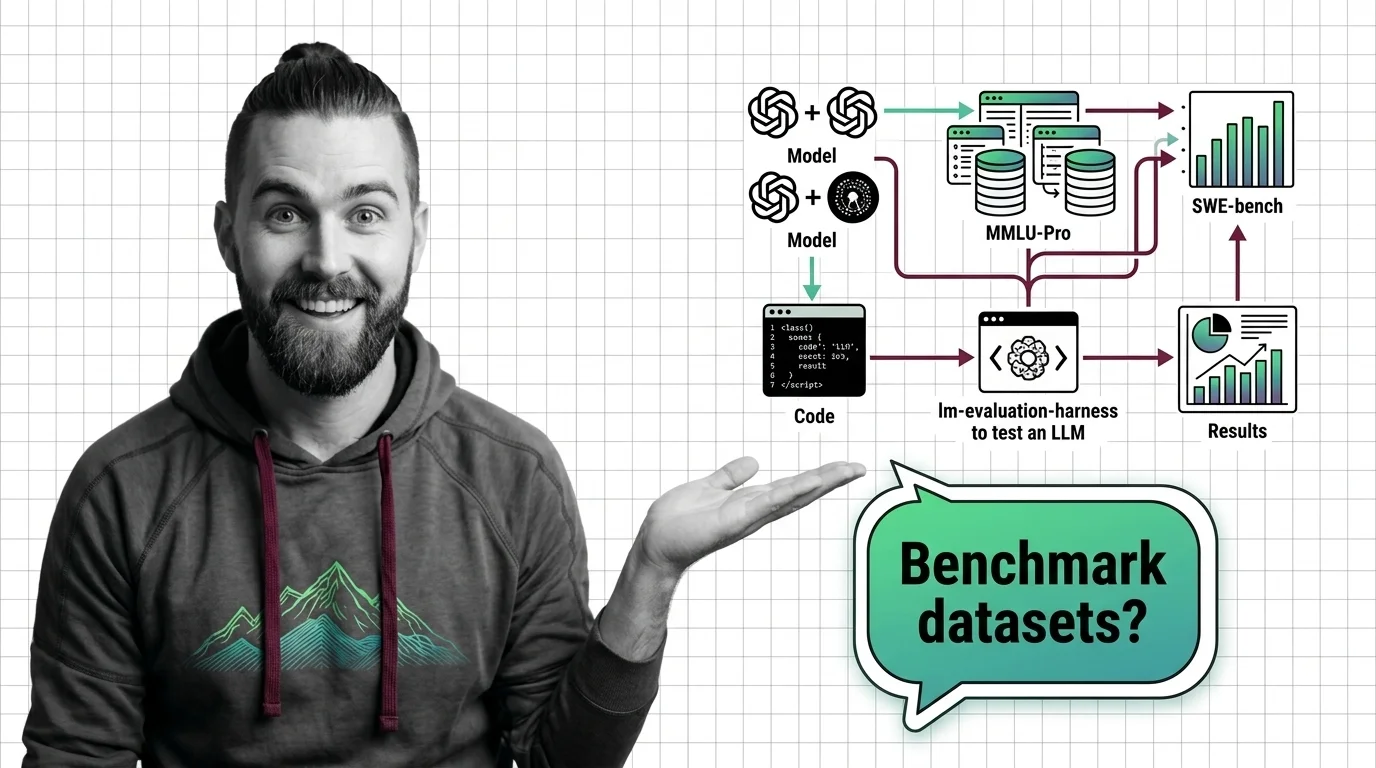
MMLU-Pro and GPQA run through lm-evaluation-harness; SWE-bench needs its own Docker harness. Pin lm-eval v0.4.12 and log config to reproduce 2026 scores.
DAN tracks how this domain is evolving — which models, techniques, and benchmarks are reshaping 2026.
Models & benchmarks
Updated June 2026

OpenAI dropped SWE-bench Verified in February 2026 over contamination. SWE-bench Pro, ARC-AGI-2, and Humanity's Last Exam now define frontier evaluation.
ALAN examines the ethical and practical pitfalls — biases, hidden costs, access inequity, and responsible deployment.
Risks & metrics

Benchmark optimization is decoupling reported AI progress from real capability. When a measure becomes a target, leaderboard gains stop reflecting skill.