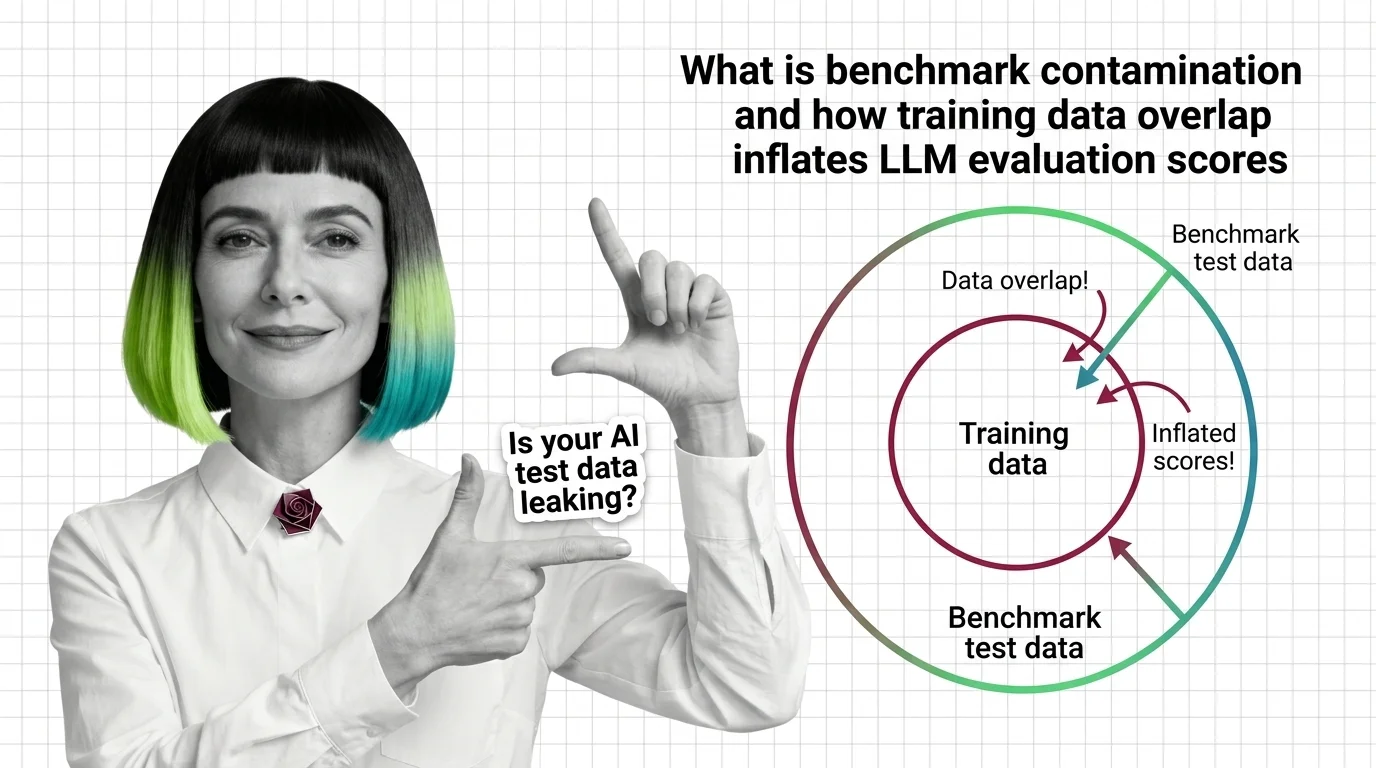
What Is Benchmark Contamination and How Training Data Overlap Inflates LLM Evaluation Scores
Benchmark contamination inflates LLM scores when training data overlaps with test sets. Learn how data leaks in and why memorization mimics true generalization.



