Benchmark Contamination
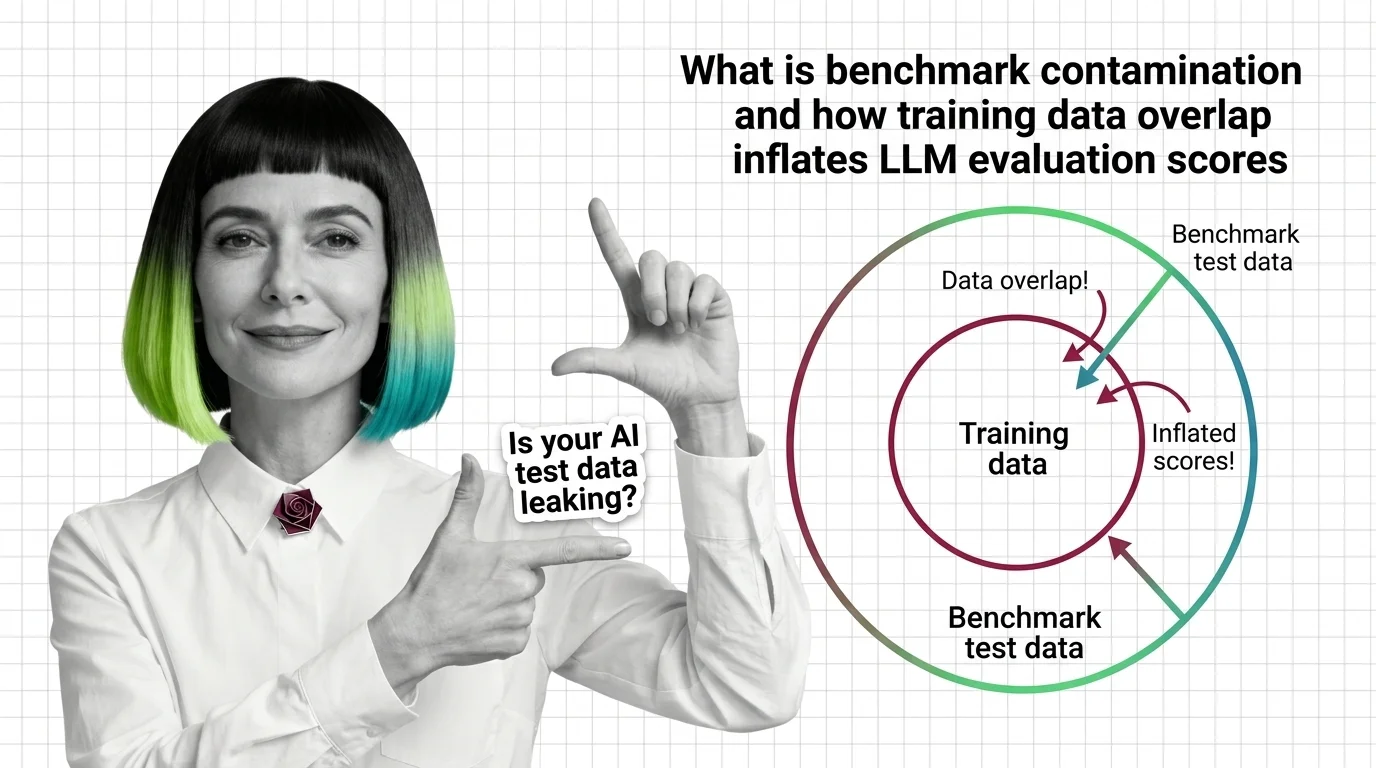
Benchmark contamination occurs when test data from evaluation benchmarks leaks into a model’s training corpus, artificially inflating scores and misrepresenting actual capability. As training datasets scale to web-wide proportions, overlap between training and test sets becomes increasingly difficult to prevent or detect, undermining the reliability of AI model comparisons. Also known as: Data Contamination, Benchmark Leakage
Understand the Fundamentals
Benchmark contamination undermines the core assumption behind model evaluation — that test data is unseen. Understanding how and why leakage happens is essential to reading AI performance claims critically.

Build with Benchmark Contamination
These guides cover practical detection methods, from overlap analysis to dynamic benchmark design, and the trade-offs each approach introduces when integrating contamination checks into your evaluation workflow.

What's Changing in 2026
The community is moving from static benchmarks toward live, regularly refreshed evaluation suites. Following this shift reveals how the field is adapting its measurement tools to keep pace with ever-larger training sets.
Updated April 2026

Risks and Considerations
Inflated benchmark scores can drive flawed procurement decisions, erode public trust, and mask genuine capability gaps. Recognizing contamination risk is critical before relying on any published evaluation result.
