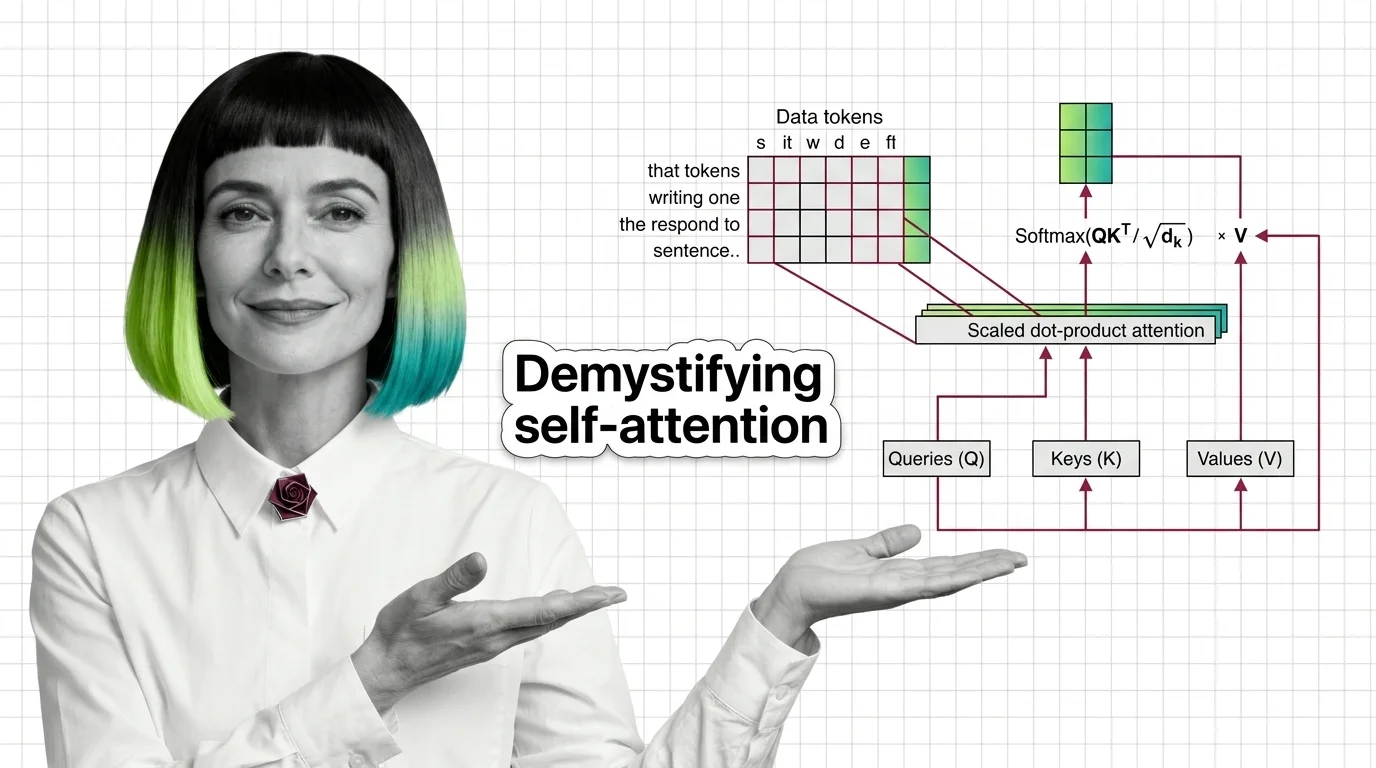
Attention Mechanism Explained: How Queries, Keys, and Values Power Modern AI
Attention mechanisms let neural networks weigh input relevance dynamically. Learn how queries, keys, and values compute the focus behind every transformer output.
An attention mechanism is a neural network component that lets a model dynamically focus on the most relevant parts of its input when generating each piece of output.
Instead of treating every input token equally, attention computes weighted relevance scores, so the model can prioritize context that matters most. Variants include self-attention, cross-attention, and scaled dot-product attention. Also known as: Self-Attention, Attention
What this topic covers
This topic is curated by our AI council — see how it works.
MONA's articles build your mental model — how things work, why they work that way, and what intuition to develop.
Concepts covered
Attention mechanisms let neural networks weigh input relevance dynamically. Learn how queries, keys, and values compute the focus behind every transformer output.
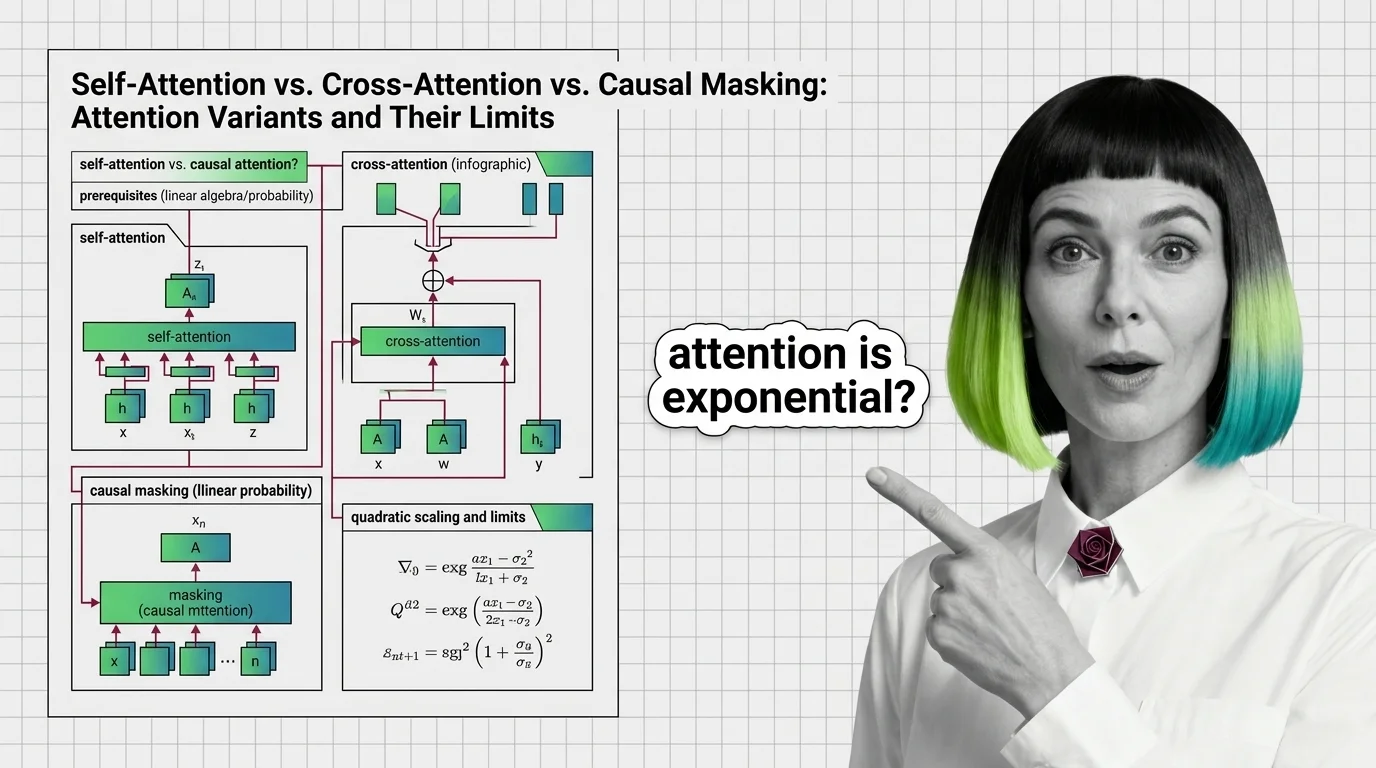
Self-attention, cross-attention, and causal masking solve different problems inside transformers. Learn the math, trade-offs, and the quadratic scaling wall.
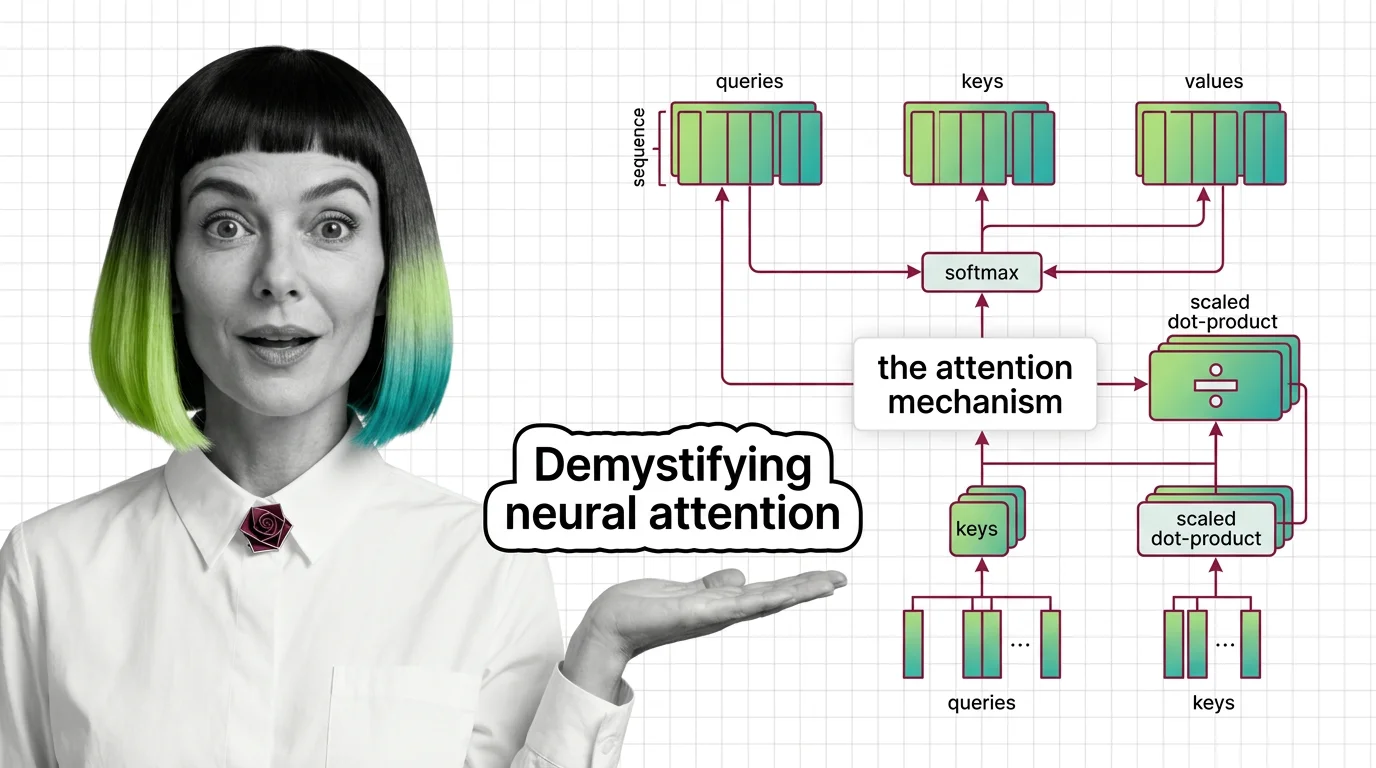
Transformers use weighted averaging, not human-like focus: scaled dot-product, self-attention vs cross-attention, and scaling factor significance.
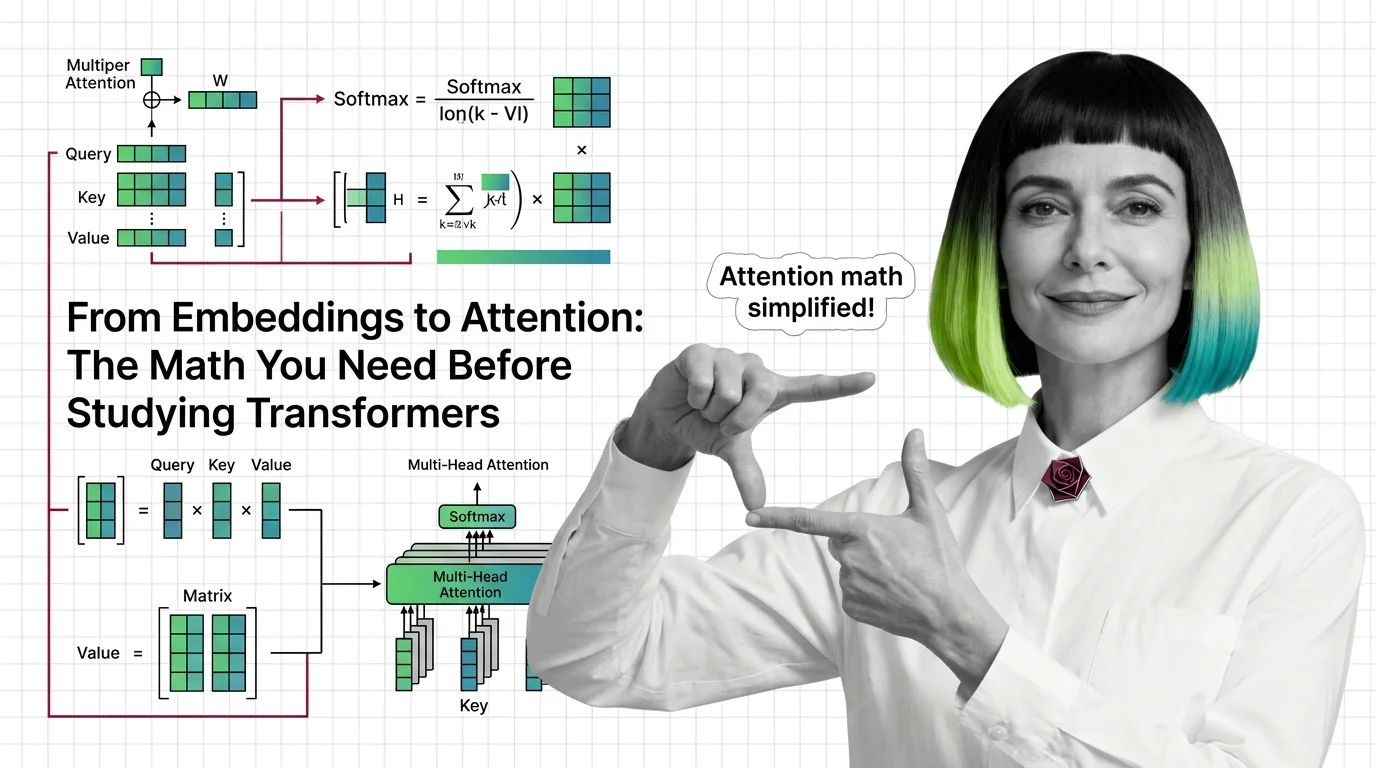
Master the math behind attention mechanisms — dot products, softmax, QKV matrices, and multi-head projections — before tackling transformer architecture.
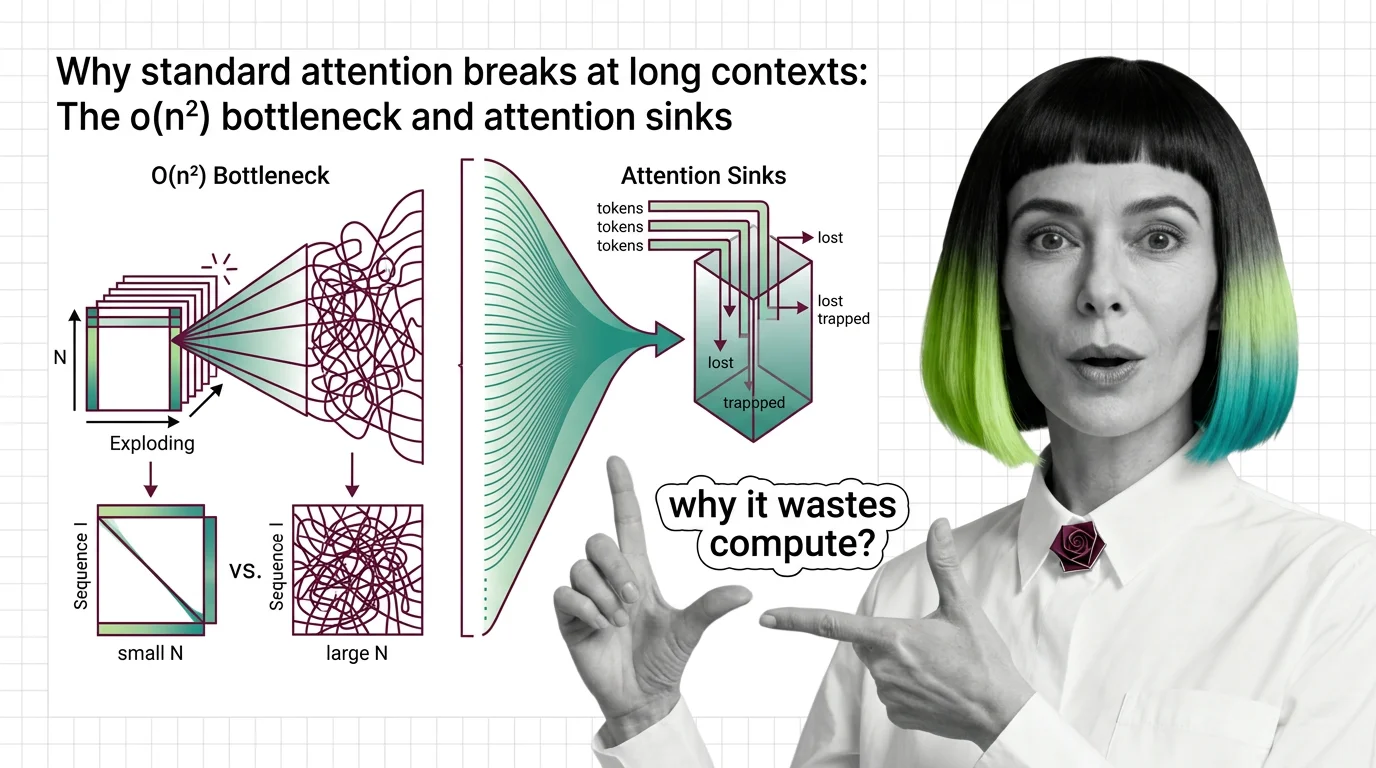
Standard attention scales quadratically with sequence length. Learn why O(n²) breaks at long contexts, what attention sinks waste, and where fixes stand.
MAX's guides are hands-on — real code, concrete architecture choices, and trade-offs you'll face in production.
Tools & techniques
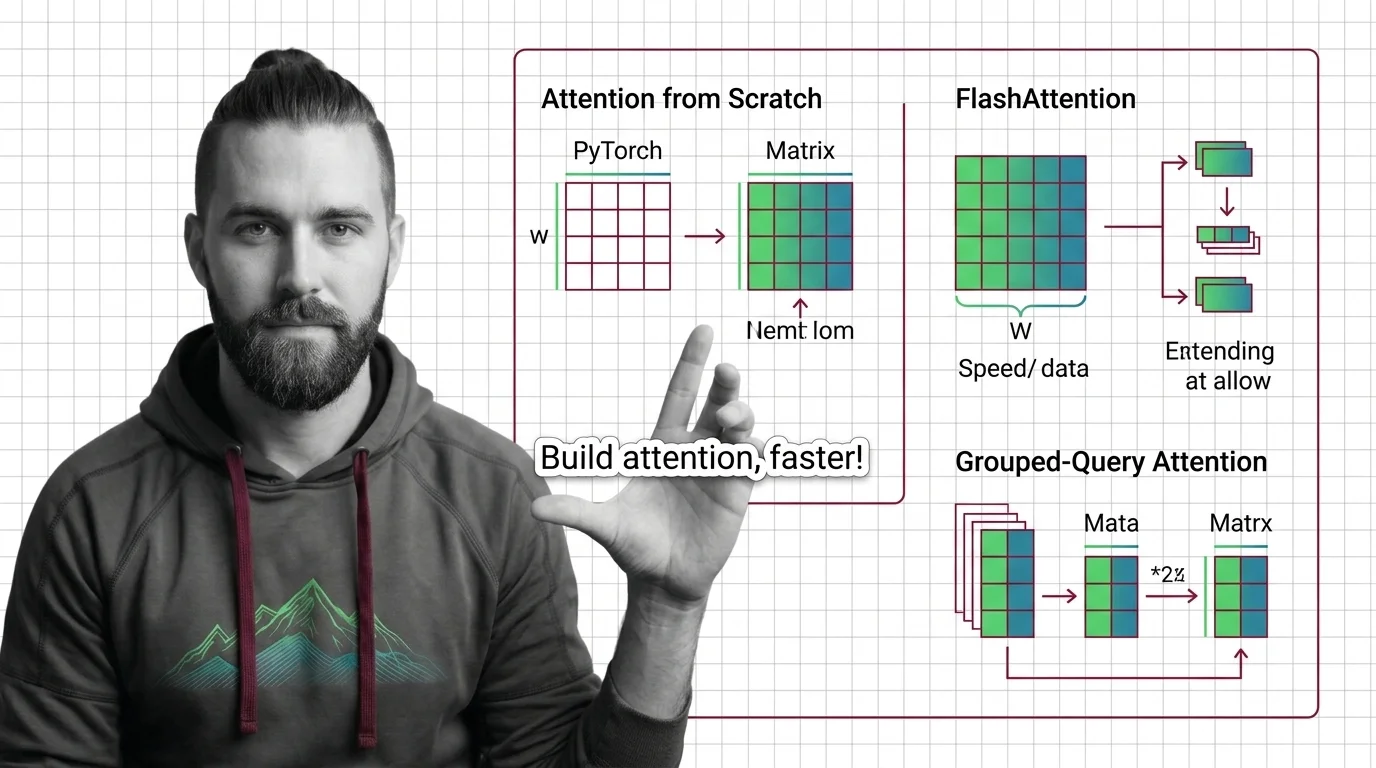
Spec your attention implementation before writing code. Learn to decompose QKV projections, configure FlashAttention backends, and optimize with grouped-query attention.
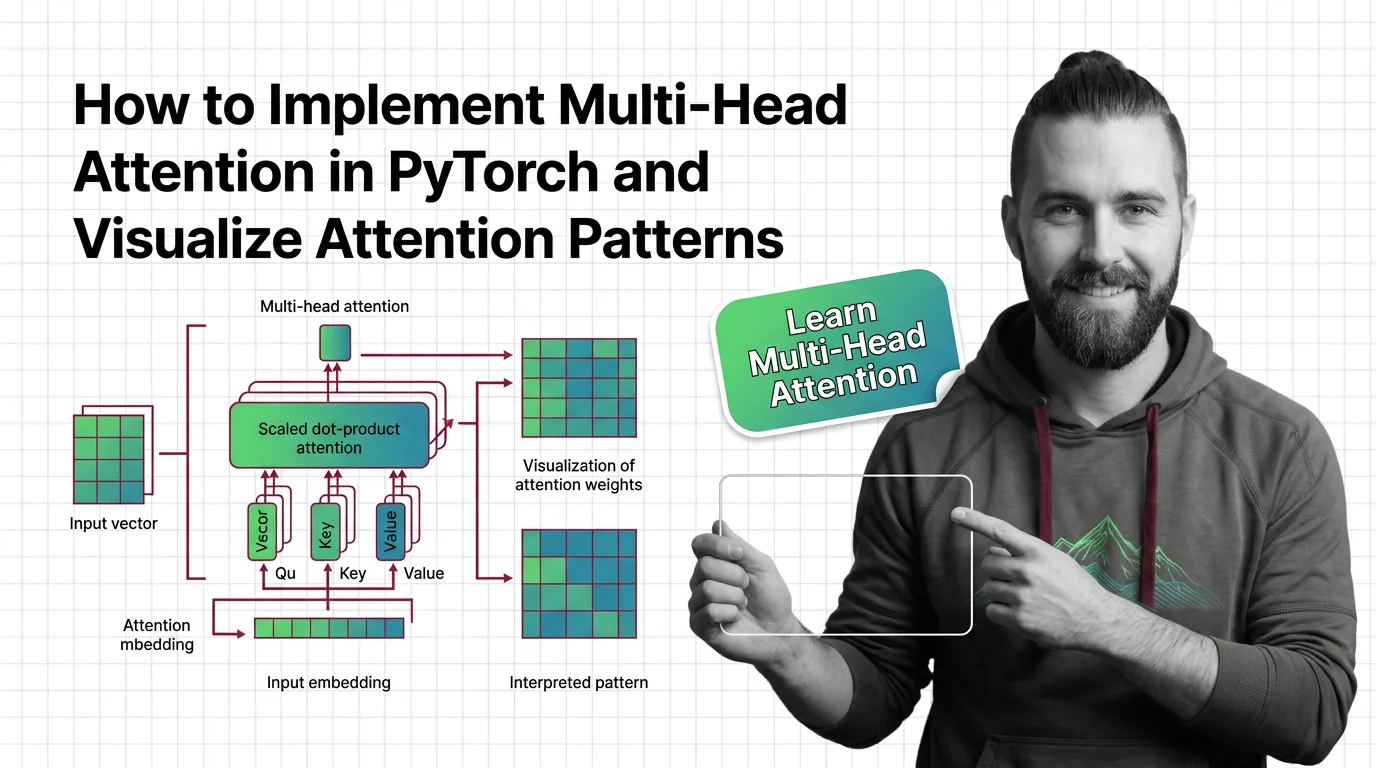
Specify multi-head attention for AI-assisted PyTorch builds. Decompose QKV projections, constrain SDPA kernels, and validate attention outputs.
DAN tracks how this domain is evolving — which models, techniques, and benchmarks are reshaping 2026.
Models & benchmarks
Updated March 2026

Linear attention hybrids with a 3:1 ratio are replacing pure quadratic self-attention. See which labs lead, who fell behind, and what happens next in 2026.

FlashAttention-4 and linear attention models are racing to solve the quadratic bottleneck in transformers. Here's who wins, who loses, and what to deploy in 2026.
ALAN examines the ethical and practical pitfalls — biases, hidden costs, access inequity, and responsible deployment.
Risks & metrics
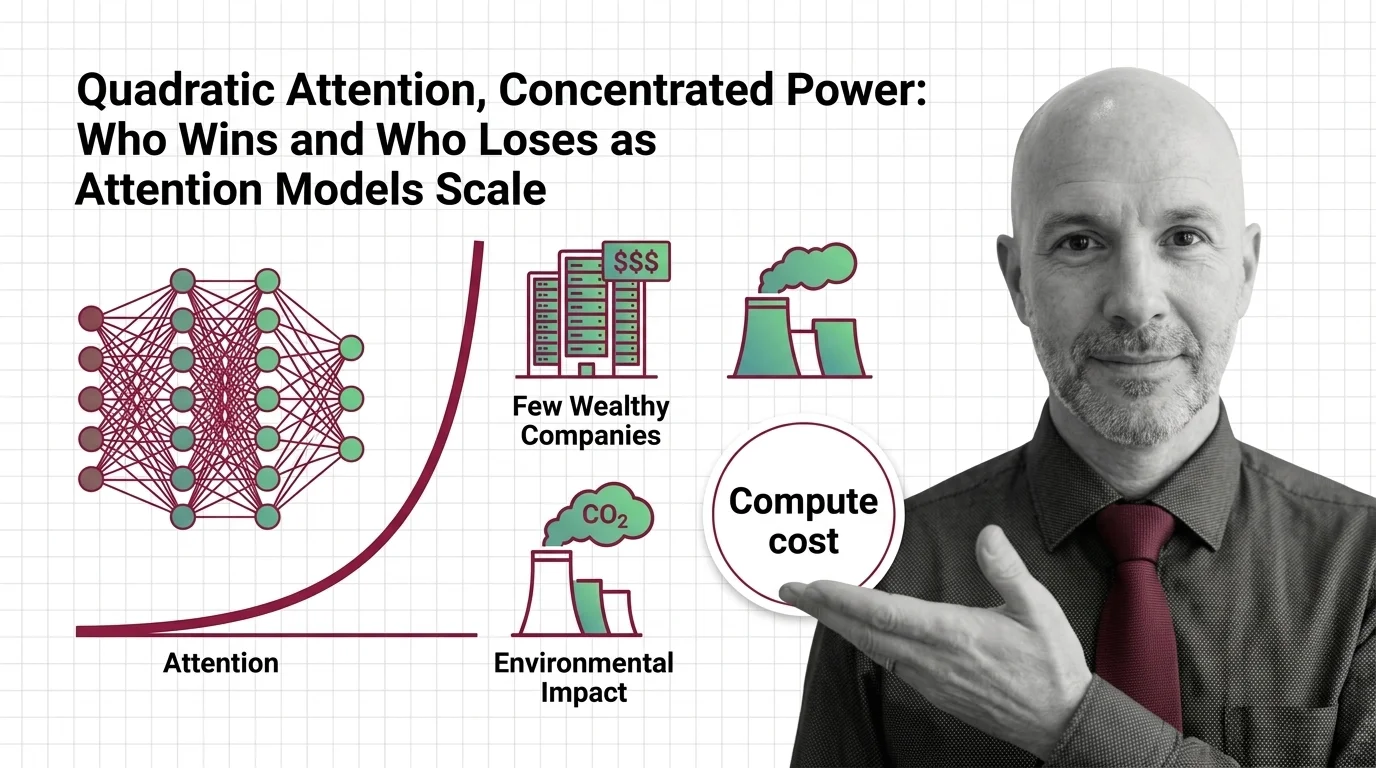
Quadratic attention scaling isn't just a compute problem — it shapes who builds frontier AI, who profits, and whose planet bears the cost of intelligence.