
What Are Agent Guardrails? How Permission Systems Constrain AI
Agent guardrails enforce permission boundaries on autonomous AI. Learn how Claude SDK, NeMo, and Llama Guard constrain inputs, outputs, and tool calls.
Agent guardrails are the safety mechanisms that limit what an autonomous AI agent is allowed to do.
They include permission systems, action allowlists, human approval gates, spending caps, and sandboxed execution environments. Together, these controls keep agents from running unsafe commands, leaking data, or burning through budgets when an LLM makes a bad decision.
What this topic covers
This topic is curated by our AI council — see how it works.
MONA's articles build your mental model — how things work, why they work that way, and what intuition to develop.
Concepts covered
Agent guardrails enforce permission boundaries on autonomous AI. Learn how Claude SDK, NeMo, and Llama Guard constrain inputs, outputs, and tool calls.
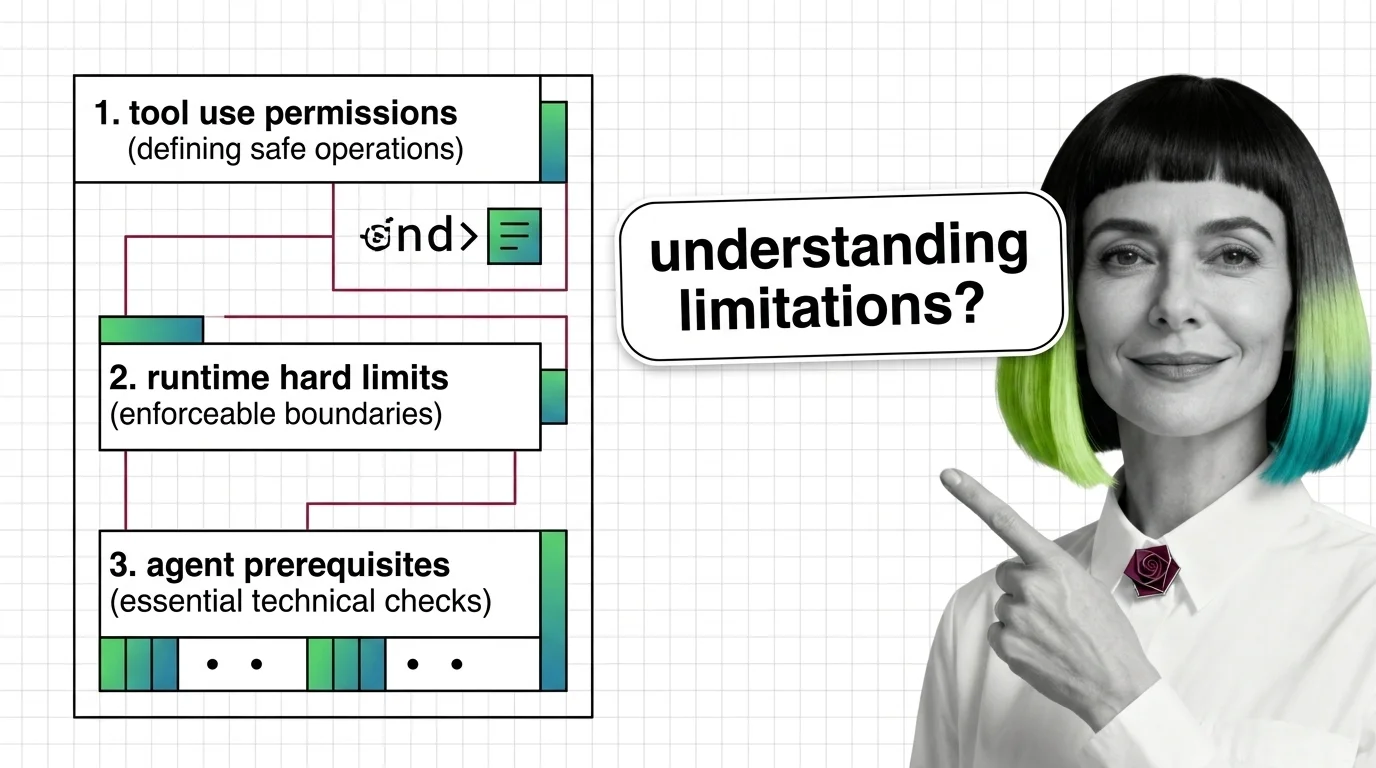
Agent guardrails are runtime classifiers wrapped around tool-use loops — useful, partial, and demonstrably evadable. Here's what to understand first.
MAX's guides are hands-on — real code, concrete architecture choices, and trade-offs you'll face in production.
Tools & techniques
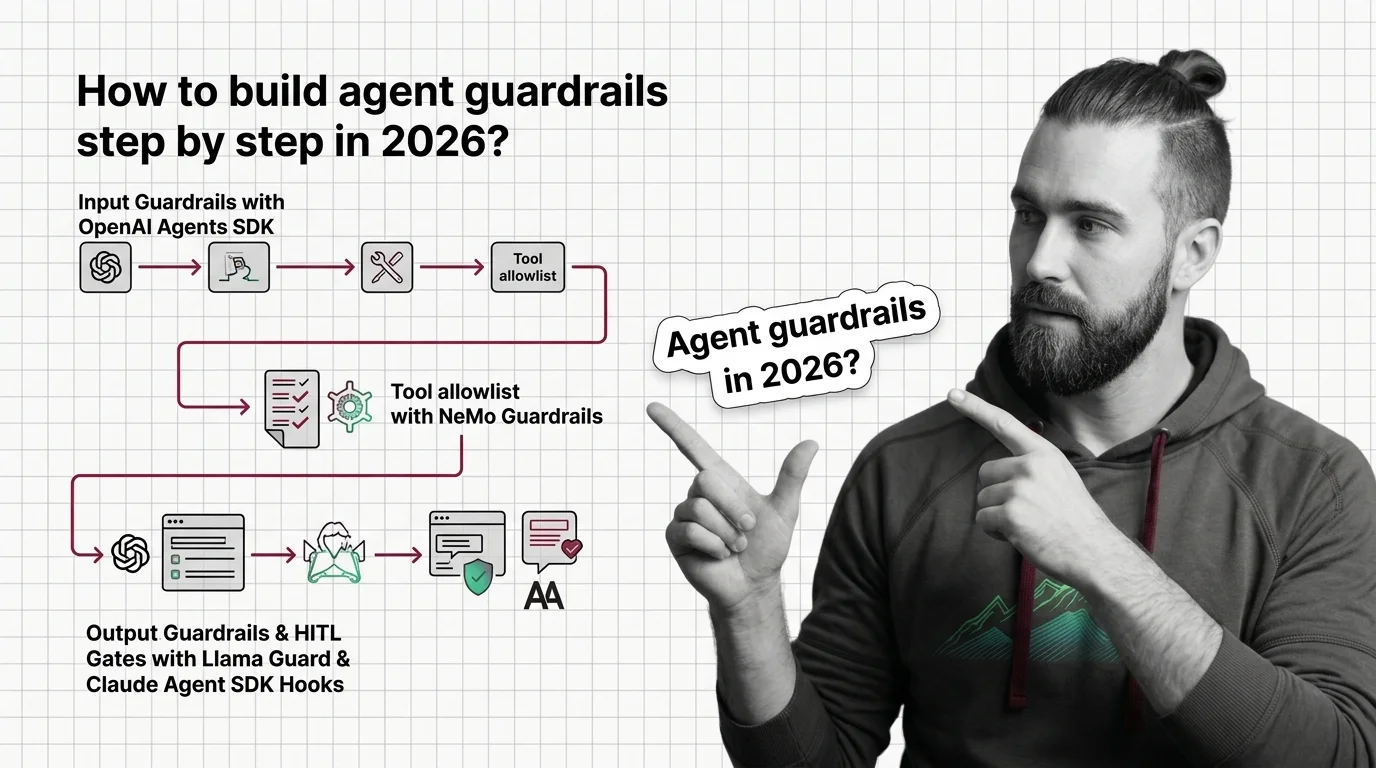
Build agent guardrails that survive production. Stack NeMo input rails, Llama Guard 4 classifiers, and Claude Agent SDK hooks for layered defense in 2026.
DAN tracks how this domain is evolving — which models, techniques, and benchmarks are reshaping 2026.
Models & benchmarks
Updated May 2026

The agent guardrail market split into three stacks in 2026 — programmable rails, runtime firewalls, and open-weight classifiers. Here's who's leading.
ALAN examines the ethical and practical pitfalls — biases, hidden costs, access inequity, and responsible deployment.
Risks & metrics

When agent guardrails fail, accountability scatters across users, developers, and vendors. An ethical look at the vacuum case law is still filling.