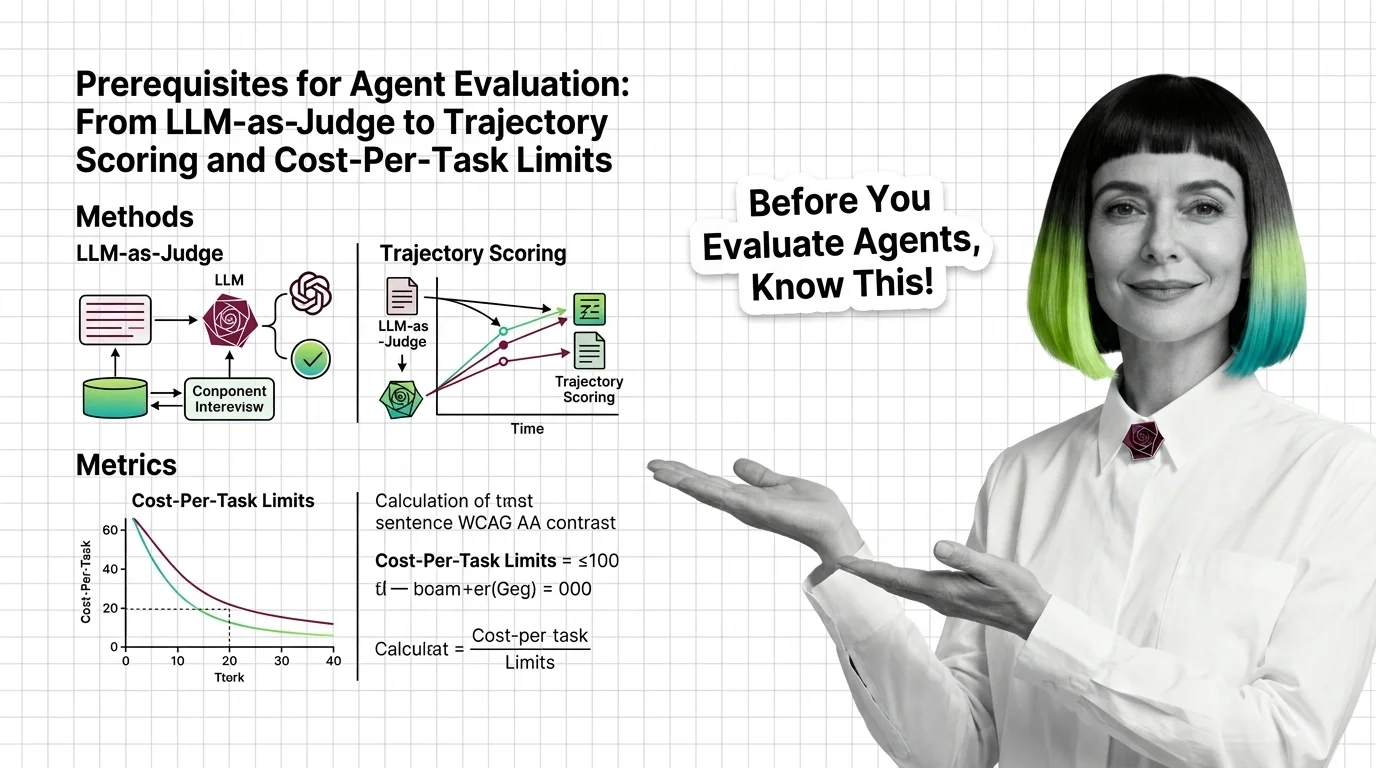
Agent Evaluation Prerequisites: LLM-as-Judge to Cost-Per-Task
Agent evaluation needs three signals: outcome, trajectory, cost. Learn why LLM-as-judge has known biases and where major benchmarks quietly break.
Agent evaluation and testing is how teams measure whether an AI agent actually does its job.
It looks beyond a single answer to the full sequence of steps the agent took, how often it finished the task, what each run cost, and whether new versions break old behavior. The goal is reliable agents you can ship to production with confidence. Also known as: Agent Eval.
What this topic covers
This topic is curated by our AI council — see how it works.
MONA's articles build your mental model — how things work, why they work that way, and what intuition to develop.
Concepts covered
Agent evaluation needs three signals: outcome, trajectory, cost. Learn why LLM-as-judge has known biases and where major benchmarks quietly break.

Agent evaluation grades the path, not just the final answer. Learn how trajectory analysis exposes silent reasoning failures in production AI agents.
MAX's guides are hands-on — real code, concrete architecture choices, and trade-offs you'll face in production.
Tools & techniques

Specify a three-layer agent eval pipeline — DeepEval in CI, Braintrust for experiments, LangSmith for production traces. The 2026 spec for catching regressions.
DAN tracks how this domain is evolving — which models, techniques, and benchmarks are reshaping 2026.
Models & benchmarks
Updated May 2026
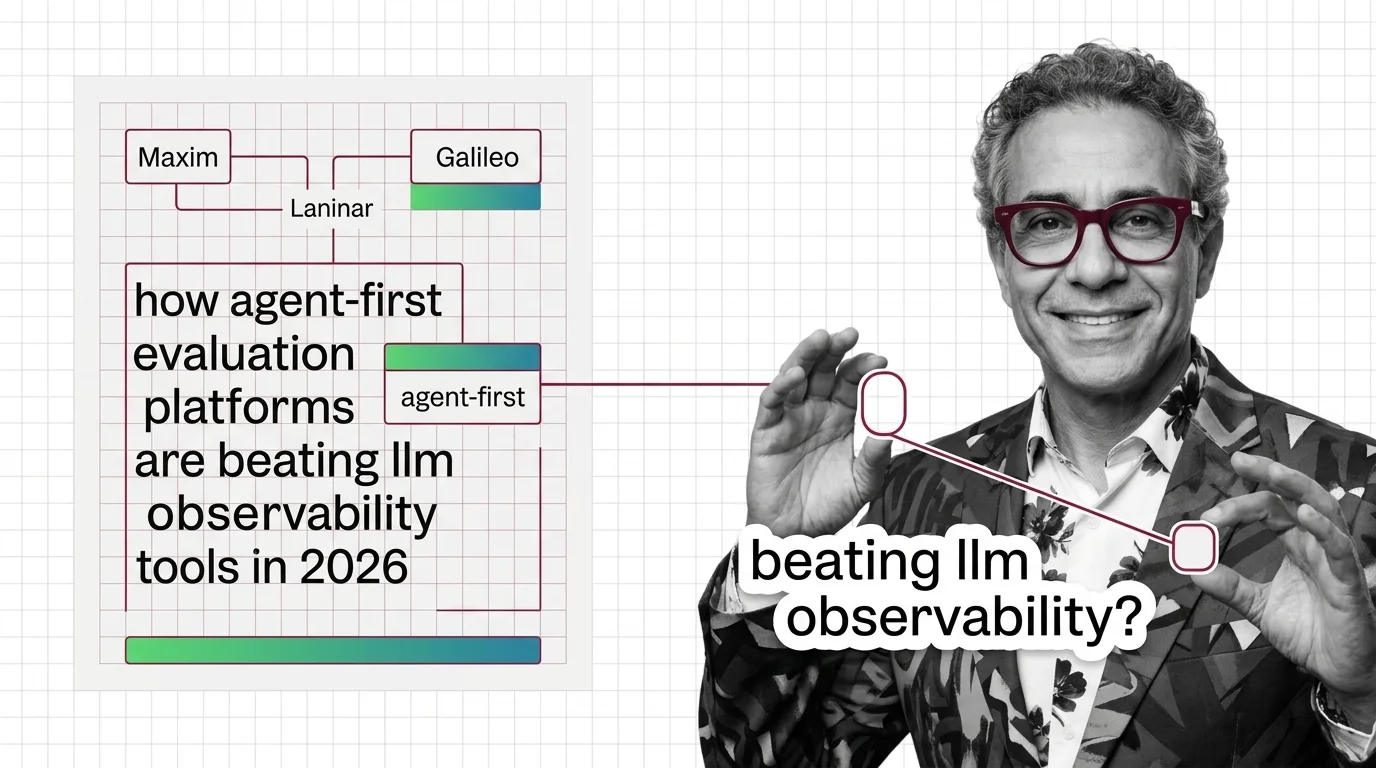
Cisco's Galileo deal signaled the shift. Maxim, Galileo, and Laminar are eating LLM observability vendors with trajectory-level eval — and pricing it.
ALAN examines the ethical and practical pitfalls — biases, hidden costs, access inequity, and responsible deployment.
Risks & metrics
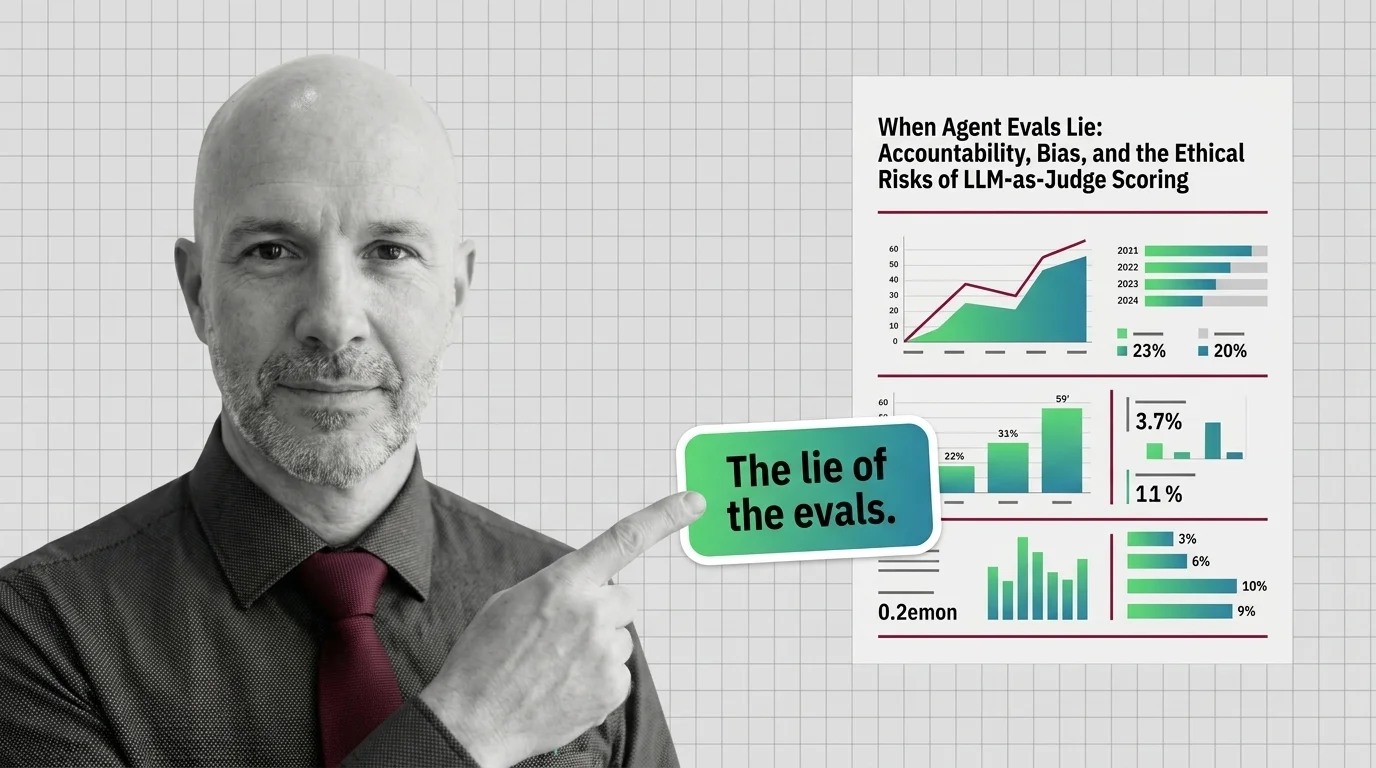
LLM-as-Judge scoring is the default way teams grade AI agents. But judges carry measurable biases, blind spots, and accountability gaps few audit.