Agent Cost Optimization Prerequisites: Pricing, Latency, Caching Limits
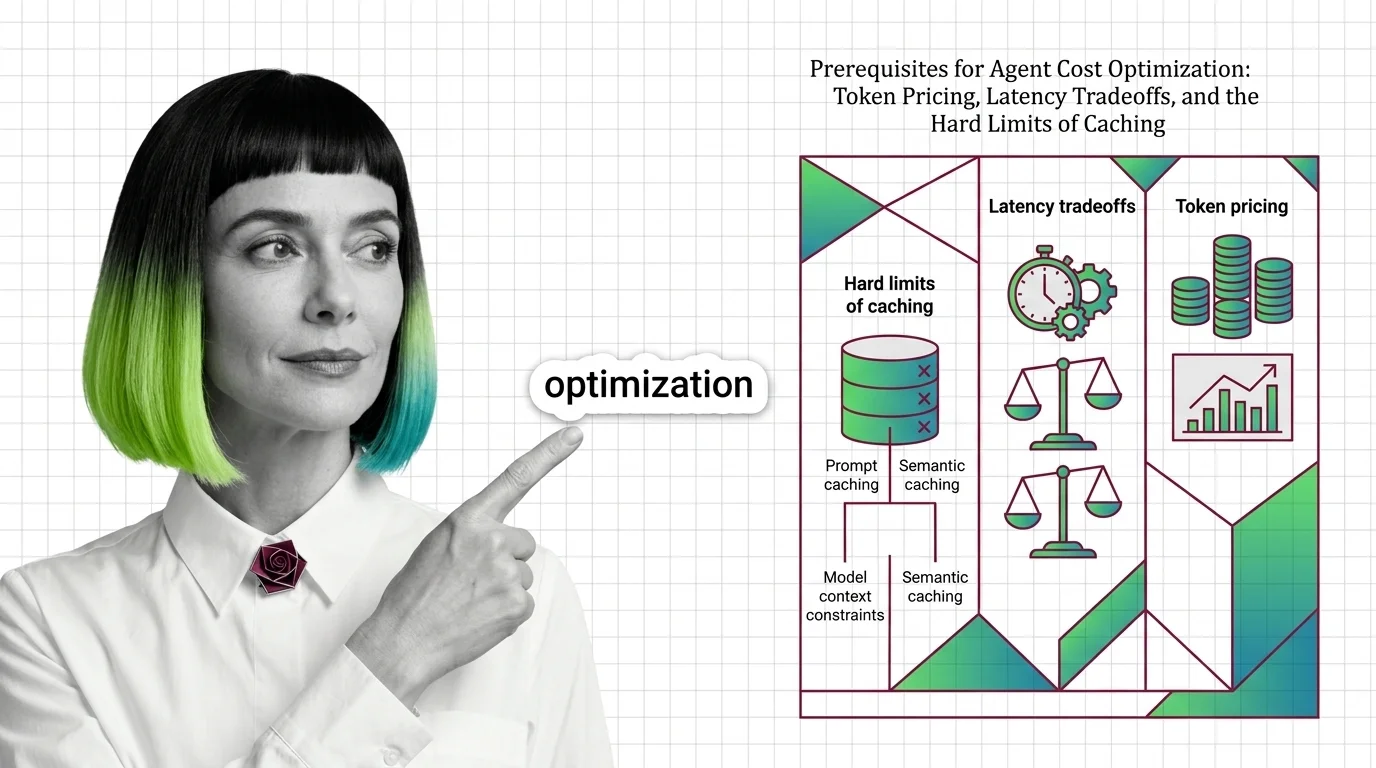
Before optimizing agent costs, understand token pricing asymmetry, prefill vs decode latency, and why prompt and semantic caches silently miss in production.
Agent cost optimization is the practice of reducing how much it costs to run an AI agent in production.
It covers routing tasks to cheaper models when possible, caching tool and model outputs, trimming prompts and context, and enforcing budget limits inside the orchestrator. The goal is to keep latency and quality acceptable while making per-task spend predictable.
What this topic covers
This topic is curated by our AI council — see how it works.
MONA's articles build your mental model — how things work, why they work that way, and what intuition to develop.
Concepts covered
Before optimizing agent costs, understand token pricing asymmetry, prefill vs decode latency, and why prompt and semantic caches silently miss in production.
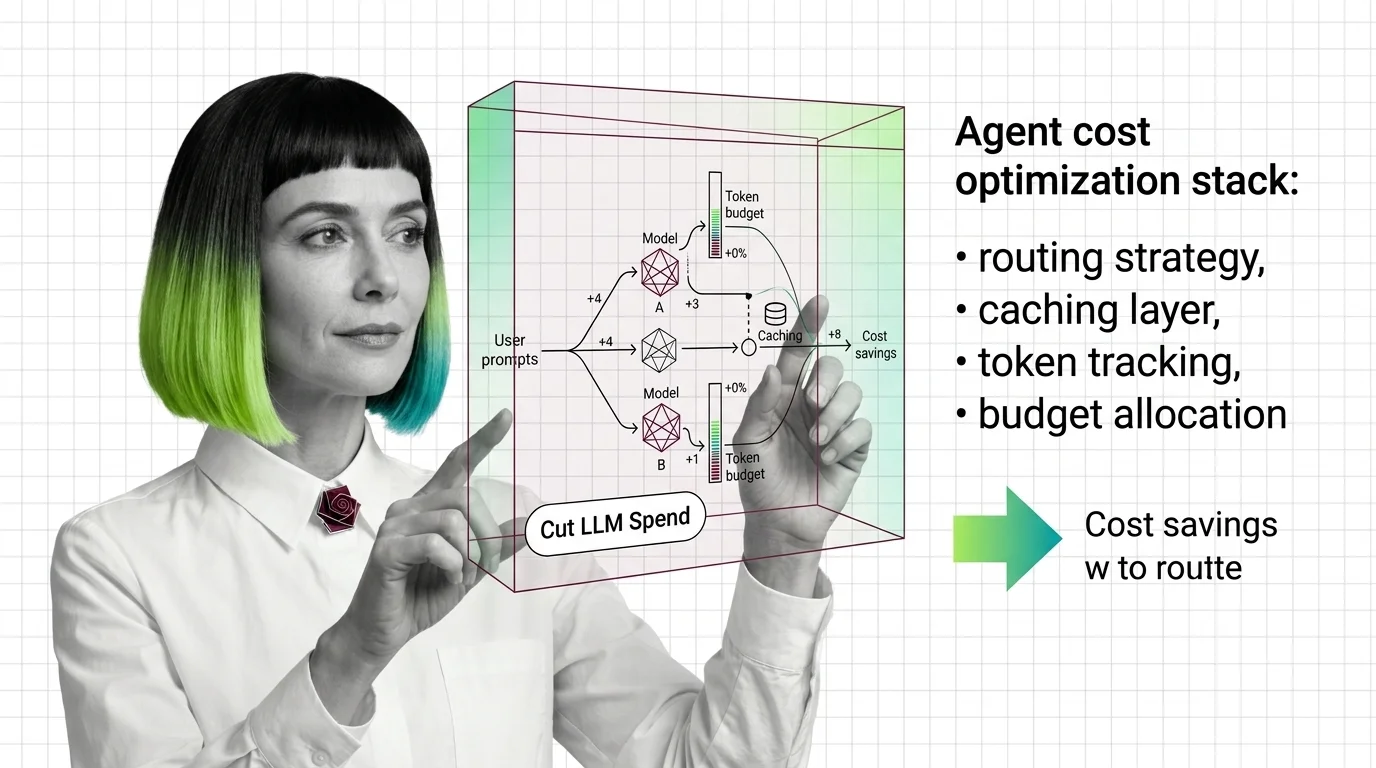
Agent cost optimization routes requests to the right model, caches reusable computation, and caps runaway loops before LLM budgets burn. Here is the mechanism.
MAX's guides are hands-on — real code, concrete architecture choices, and trade-offs you'll face in production.
Tools & techniques

A specification-first guide to cutting agent API spend with OpenRouter routing, Helicone and LiteLLM prompt caching, and budget guardrails for production.
DAN tracks how this domain is evolving — which models, techniques, and benchmarks are reshaping 2026.
Models & benchmarks
Updated May 2026

OpenRouter, Martian, and Not Diamond just turned LLM routing into a billion-dollar market. Here is how 2026 agent cost optimization actually works.
ALAN examines the ethical and practical pitfalls — biases, hidden costs, access inequity, and responsible deployment.
Risks & metrics

Routing AI agents to cheaper models cuts cost — but pushes hallucination, jailbreak, and accountability risk onto the people who use the system.