
What Is Active Learning and How Models Pick the Most Informative Samples to Label
Active learning lets a model query only the most informative unlabeled samples to label, hitting target accuracy with far fewer labels than random sampling.
This topic is curated by our AI council — see how it works.
Every other lever in training data quality and curation — cleaning, augmenting, deduplicating — treats a dataset as something you already have in front of you. Active learning is the one strategy that decides what to add to it next, by having the model itself flag which unlabeled examples would actually change what it knows. That reframing turns the loop into a budget decision as much as a modeling one: every label a human produces should teach the model more than a random pick would, or the added complexity is not earning its keep.
Start with what active learning is and how models pick the most informative samples to label for the mechanism itself — how a model ranks its own unlabeled pool and hands the top of that ranking to a human. Once the idea holds, uncertainty sampling explained opens up the query strategy: entropy, margin, and least-confidence are three different ways to define “the model is not sure,” and picking among them shapes everything that follows. Read before active learning before wiring anything — it names the working labeling pipeline and baseline model the loop assumes, plus the cold-start and sampling-bias failure modes that break loops built without them.
With the mechanism and its limits in hand, the modAL, Cleanlab, and Prodigy build guide turns the theory into a four-stage pipeline you can actually run. For the budget picture around that pipeline, annotation-cost savings in practice reports what teams are measuring in 2026 as the technique converges with foundation-model workflows. Close with the ethics of letting models choose what humans label — if the loop’s selections will ever decide whose data gets attention in a fairness-sensitive system, read this before trusting the query strategy’s certainty.

Active learning is not a labeling pipeline in itself — it is the selection layer that decides which examples an existing data labeling and annotation pipeline receives next. Without a working annotation interface and guidelines already in place, the loop has nothing to hand its selections to.
It is also not a fix for bad data. A model already confused by noisy labels does not get better guidance from active learning; the query strategy just samples confidently around the wrong answer key. Training data quality work has to happen on the seed set first, or the loop spends its budget re-confirming errors instead of closing gaps.
And it targets scarcity from the opposite direction of data augmentation. Augmentation manufactures more examples out of data you have already labeled; active learning spends real human attention on real examples you have not labeled yet. One invents variety, the other rations it.
Q: Which active learning article should I read first if my labeling pipeline is already running and cost is the only problem? A: Skip the orientation piece and go straight to uncertainty sampling explained — once labeling exists and you just need it to spend less, entropy, margin, and least-confidence strategies decide which unlabeled examples justify a human’s time.
Q: Are foundation models making active learning unnecessary? A: No — real annotation-cost data from 2026 shows foundation models did not replace active learning; they turned it into the layer deciding which examples those models are even allowed to learn from, inside a propose/select/correct loop.
Q: Why might an active learning loop keep selecting the same mislabeled examples round after round? A: Because uncertainty and a genuine label error look identical to a query strategy — a wrong answer reads as “confusing” forever. The modAL, Cleanlab, and Prodigy loop guide runs Cleanlab over the seed set first, so noisy labels get caught before they anchor the loop.
Q: Who is responsible for fairness when the model, not a person, decides which examples get labeled? A: The person who designs the query strategy, not the algorithm. The ethics of letting models choose what humans label argues active learning has no fixed moral valence — it amplifies or corrects bias depending on whether fairness is built into the objective, not assumed to emerge from efficiency.
Part of training data quality and curation · closest neighbour: data labeling and annotation.
Active learning flips the usual labeling workflow: instead of annotating data at random, the model ranks unlabeled examples by how much they would teach it. Start here to grasp why that choice matters.
Concepts covered
Active learning lets a model query only the most informative unlabeled samples to label, hitting target accuracy with far fewer labels than random sampling.
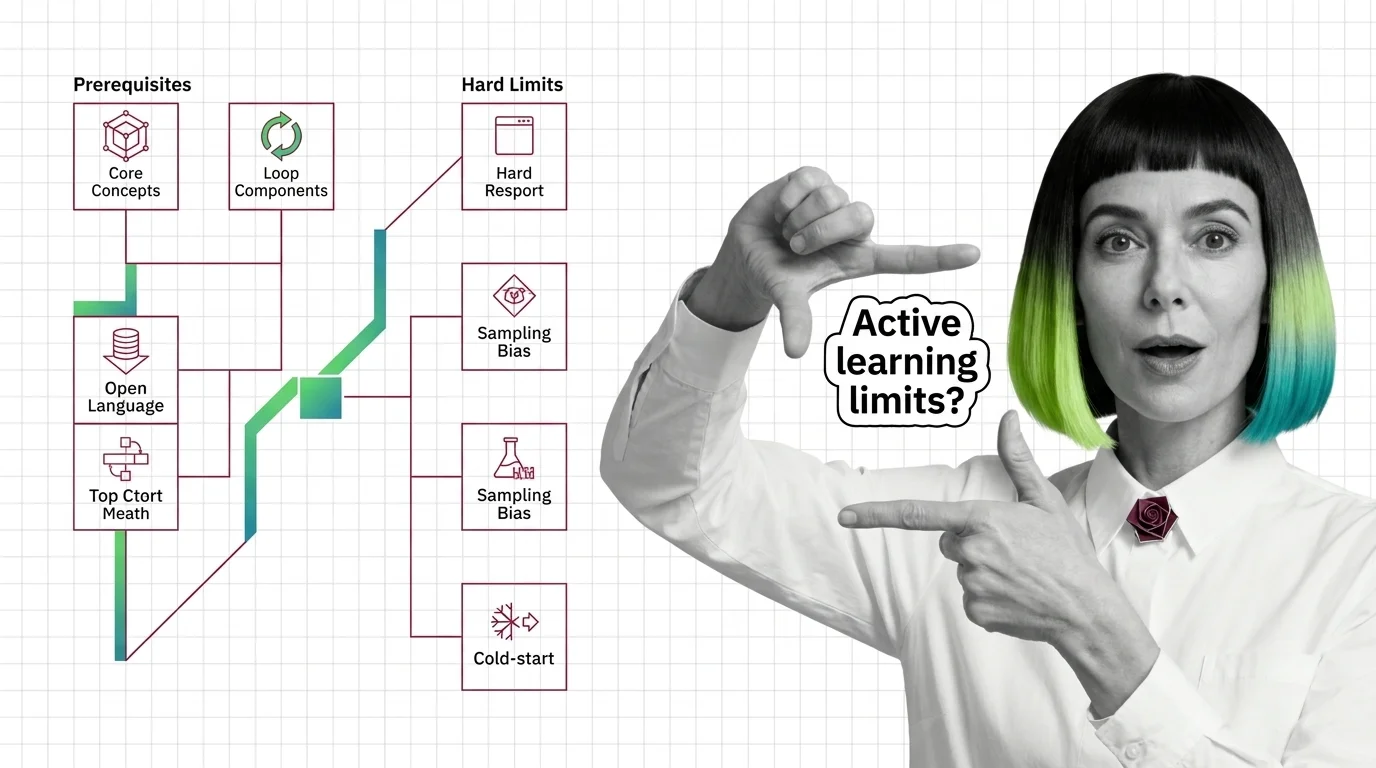
Active learning lets a model pick which examples to label instead of sampling at random — but sampling bias and cold-start can make it lose to random.
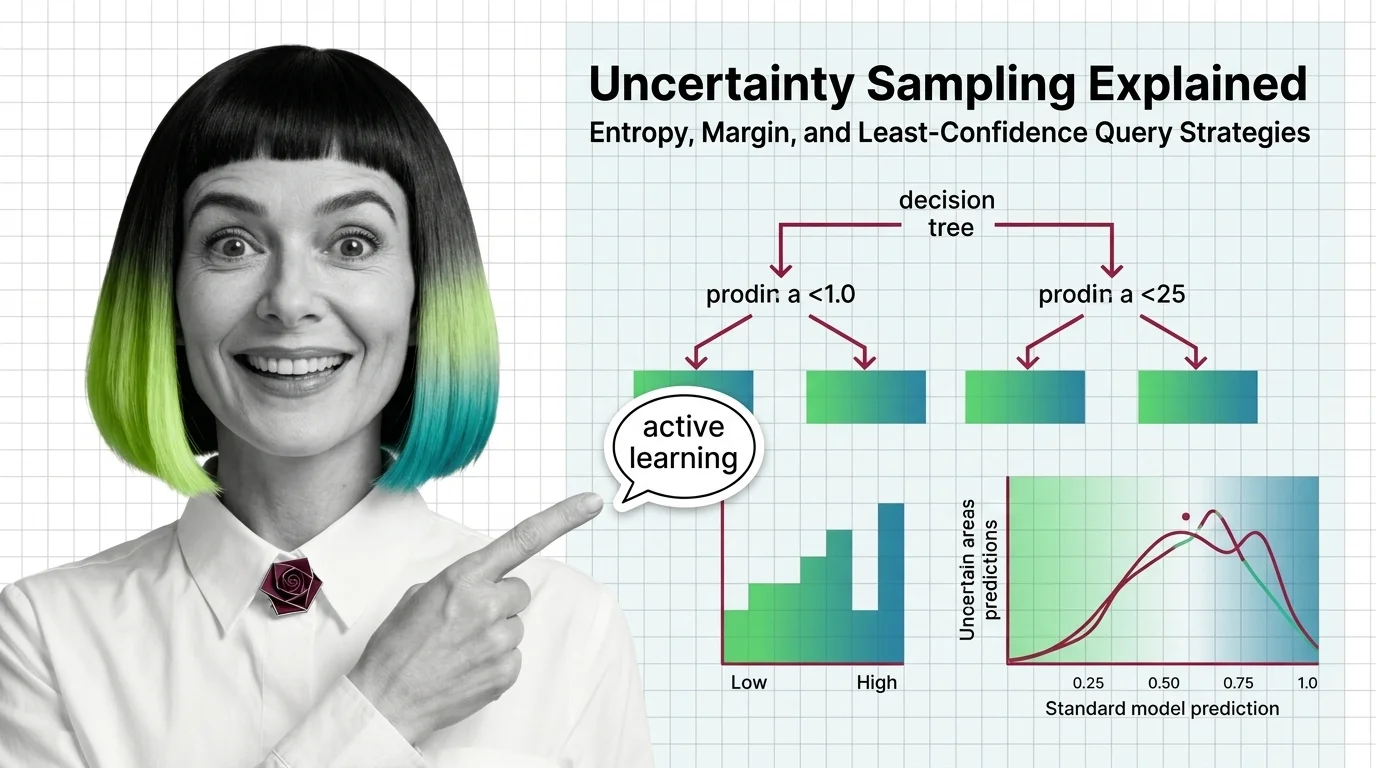
Uncertainty sampling is an active-learning strategy that labels the data a model is least confident about — via entropy, margin, or least-confidence scores.
These guides walk through wiring an active learning loop end to end — picking a query strategy, connecting it to your annotation tool, and deciding when the loop has squeezed out its useful gains.
Tools & techniques
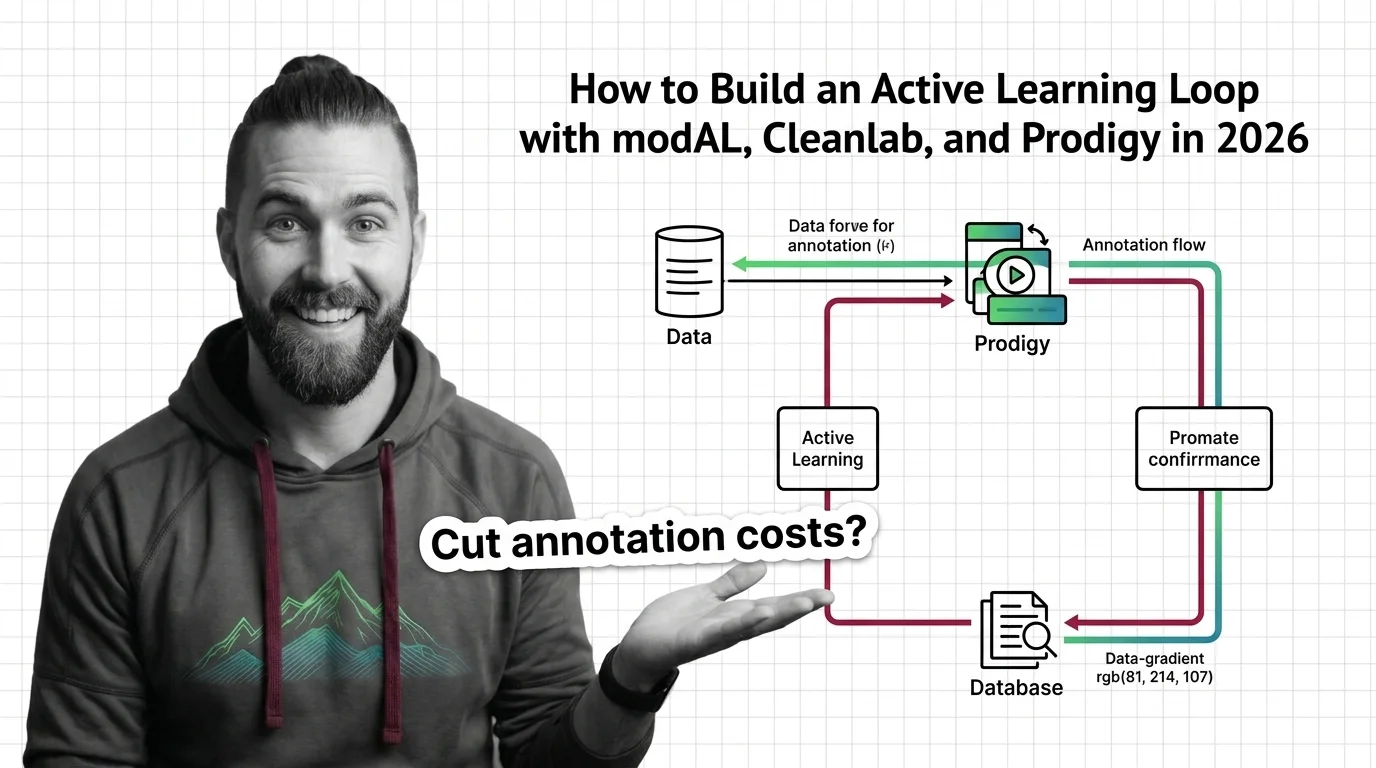
An active learning loop pairs uncertainty sampling, Cleanlab label-error detection, and Prodigy annotation to label only data the model finds hardest.
Annotation budgets keep shrinking while datasets grow, so smarter sample selection is moving from research curiosity toward standard practice. Follow how the field is shifting and where the real savings show up.
Models & benchmarks
Updated June 2026
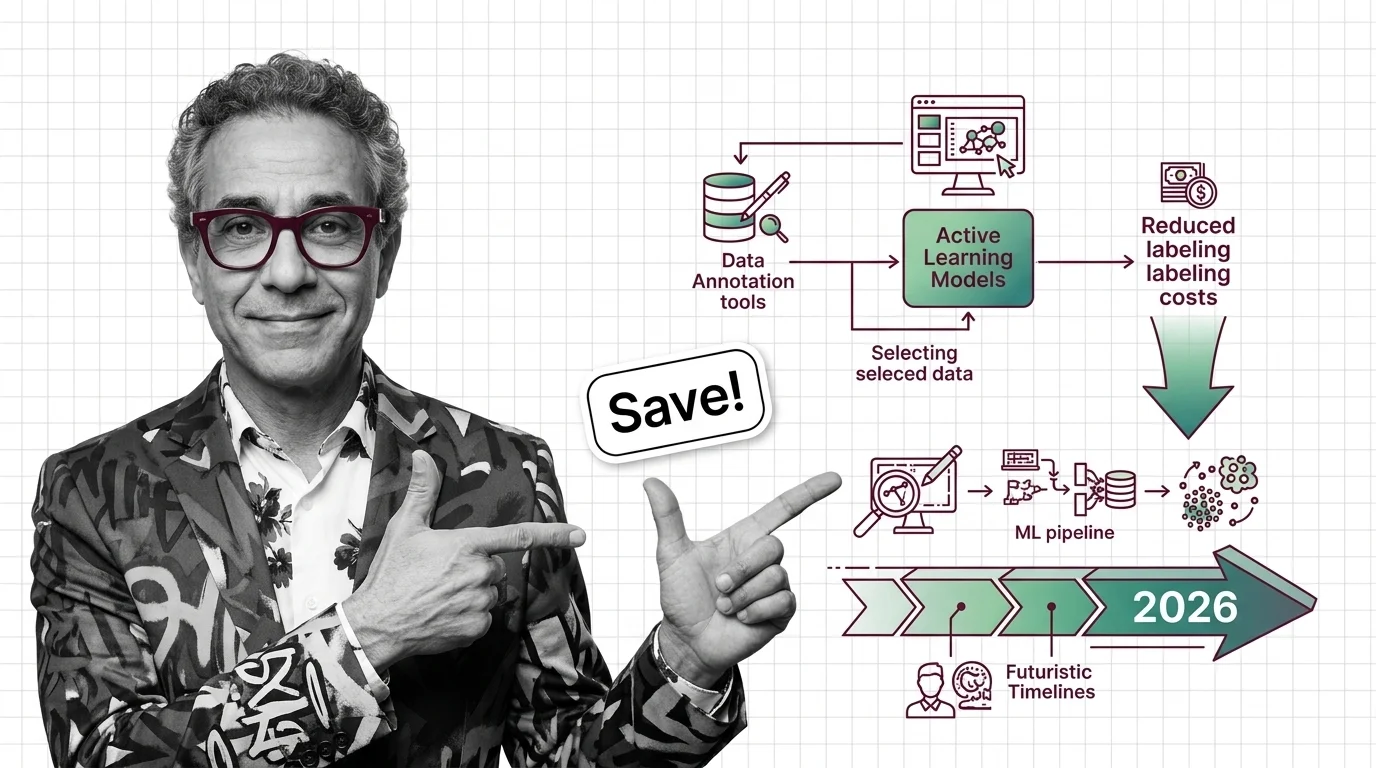
Active learning cuts annotation cost 50%+ in biomedical imaging by choosing which examples humans label — and in 2026 it pairs with foundation models.
Letting a model decide what humans label is not neutral. It can quietly entrench existing blind spots and amplify dataset bias, so weigh what gets left unlabeled before trusting the loop.
Risks & metrics

Active learning lets models choose which data humans label. Whether it amplifies or curbs dataset bias depends on the query strategy and the source of bias.